 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEBUG-HD: Debugging TinyML models on-device using Hyper-Dimensional computing
Nov 16, 2024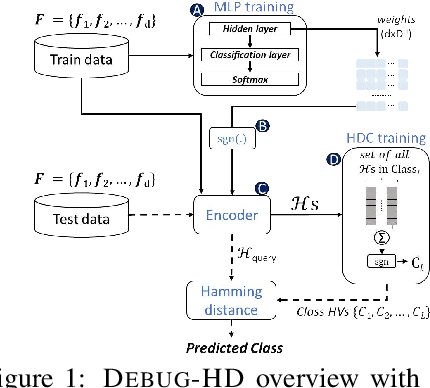
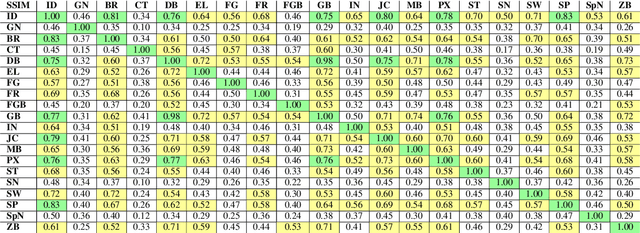

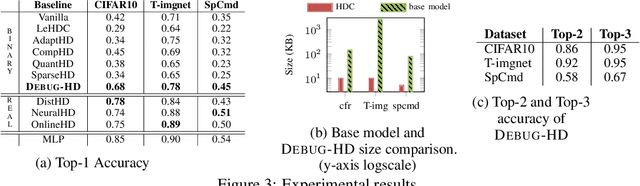
TinyML models often operate in remote, dynamic environments without cloud connectivity, making them prone to failures. Ensuring reliability in such scenarios requires not only detecting model failures but also identifying their root causes. However, transient failures, privacy concerns, and the safety-critical nature of many applications-where systems cannot be interrupted for debugging-complicate the use of raw sensor data for offline analysis. We propose DEBUG-HD, a novel, resource-efficient on-device debugging approach optimized for KB-sized tinyML devices that utilizes hyper-dimensional computing (HDC). Our method introduces a new HDC encoding technique that leverages conventional neural networks, allowing DEBUG-HD to outperform prior binary HDC methods by 27% on average in detecting input corruptions across various image and audio datasets.
QUTE: Quantifying Uncertainty in TinyML models with Early-exit-assisted ensembles
Apr 19, 2024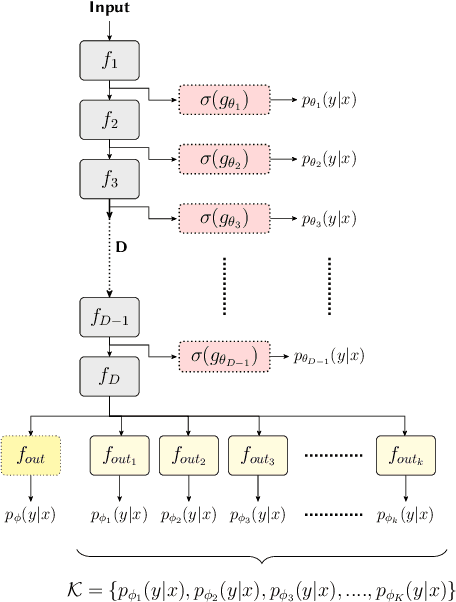
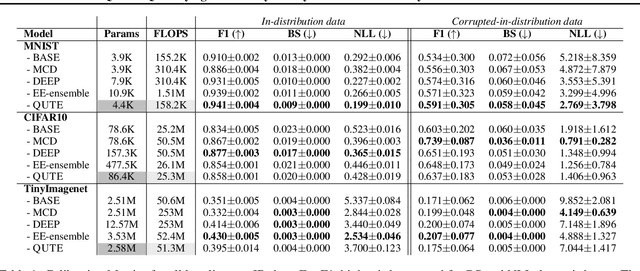
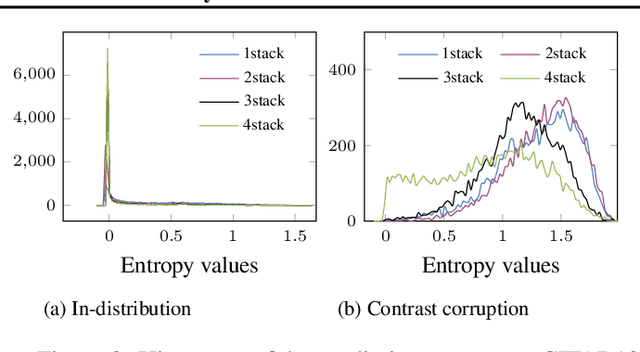

Existing methods for uncertainty quantification incur massive memory and compute overhead, often requiring multiple models/inferences. Hence they are impractical on ultra-low-power KB-sized TinyML devices. To reduce overhead, prior works have proposed the use of early-exit networks as ensembles to quantify uncertainty in a single forward-pass. However, they still have a prohibitive cost for tinyML. To address these challenges, we propose QUTE, a novel resource-efficient early-exit-assisted ensemble architecture optimized for tinyML models. QUTE adds additional output blocks at the final exit of the base network and distills the knowledge of early-exits into these blocks to create a diverse and lightweight ensemble architecture. Our results show that QUTE outperforms popular prior works, and improves the quality of uncertainty estimates by 6% with 3.1x lower model size on average compared to the most relevant prior work. Furthermore, we demonstrate that QUTE is also effective in detecting co-variate shifted and out-of-distribution inputs, and shows competitive performance relative to G-ODIN, a state-of-the-art generalized OOD detector.
T-RECX: Tiny-Resource Efficient Convolutional Neural Networks with Early-Exit
Jul 14, 2022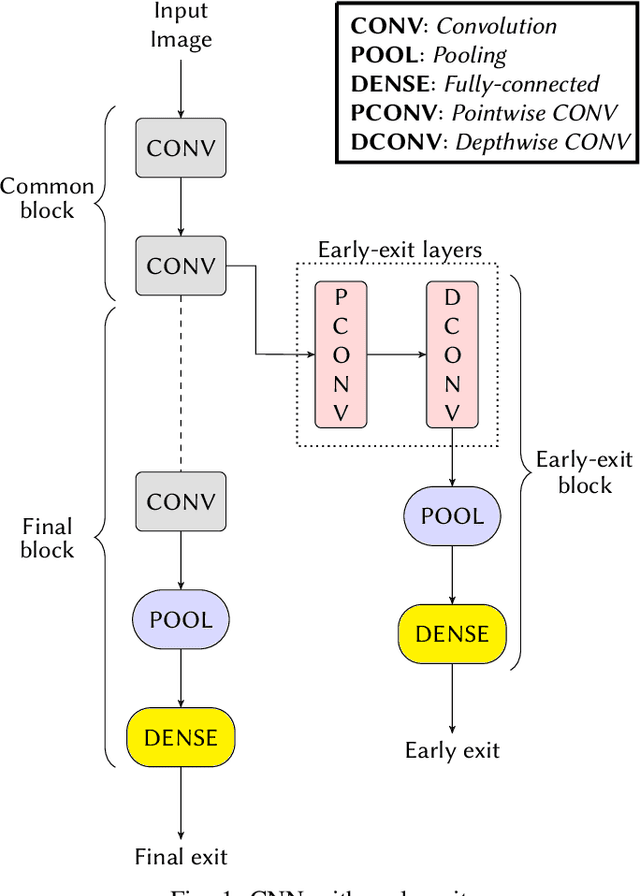
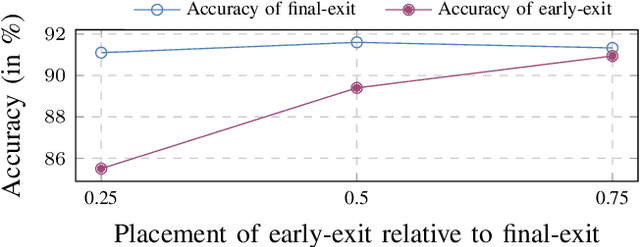
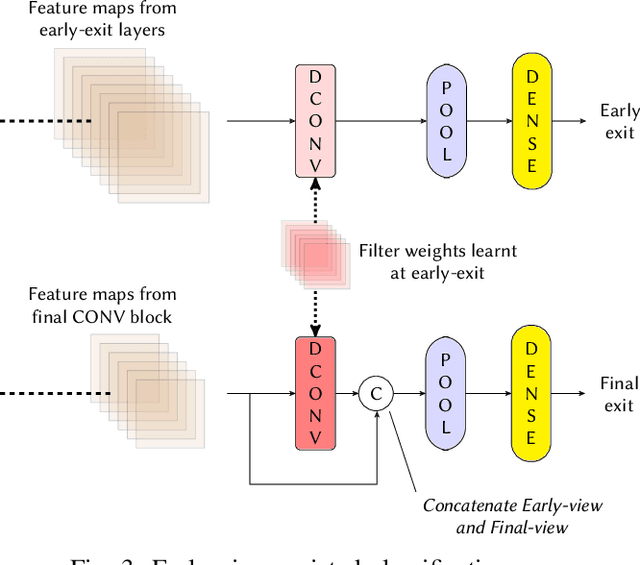
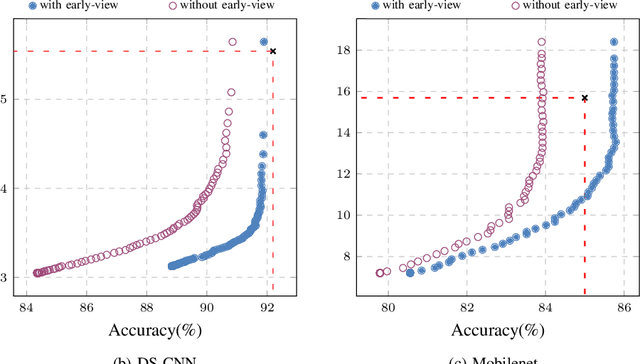
Deploying Machine learning (ML) on the milliwatt-scale edge devices (tinyML) is gaining popularity due to recent breakthroughs in ML and IoT. However, the capabilities of tinyML are restricted by strict power and compute constraints. The majority of the contemporary research in tinyML focuses on model compression techniques such as model pruning and quantization to fit ML models on low-end devices. Nevertheless, the improvements in energy consumption and inference time obtained by existing techniques are limited because aggressive compression quickly shrinks model capacity and accuracy. Another approach to improve inference time and/or reduce power while preserving its model capacity is through early-exit networks. These networks place intermediate classifiers along a baseline neural network that facilitate early exit from neural network computation if an intermediate classifier exhibits sufficient confidence in its prediction. Previous work on early-exit networks have focused on large networks, beyond what would typically be used for tinyML applications. In this paper, we discuss the challenges of adding early-exits to state-of-the-art tiny-CNNs and devise an early-exit architecture, T-RECX, that addresses these challenges. In addition, we develop a method to alleviate the effect of network overthinking at the final exit by leveraging the high-level representations learned by the early-exit. We evaluate T-RECX on three CNNs from the MLPerf tiny benchmark suite for image classification, keyword spotting and visual wake word detection tasks. Our results demonstrate that T-RECX improves the accuracy of baseline network and significantly reduces the average inference time of tiny-CNNs. T-RECX achieves 32.58% average reduction in FLOPS in exchange for 1% accuracy across all evaluated models. Also, our techniques increase the accuracy of baseline network in two out of three models we evaluate