 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic High-quality Verilog Assertion Generation through Subtask-Focused Fine-Tuned LLMs and Iterative Prompting
Nov 23, 2024



Formal Property Verification (FPV), using SystemVerilog Assertions (SVA), is crucial for ensuring the completeness of design with respect to the specification. However, writing SVA is a laborious task and has a steep learning curve. In this work, we present a large language model (LLM) -based flow to automatically generate high-quality SVA from the design specification documents, named \ToolName. We introduce a novel sub-task-focused fine-tuning approach that effectively addresses functionally incorrect assertions produced by baseline LLMs, leading to a remarkable 7.3-fold increase in the number of functionally correct assertions. Recognizing the prevalence of syntax and semantic errors, we also developed an iterative refinement method that enhances the LLM's initial outputs by systematically re-prompting it to correct identified issues. This process is further strengthened by a custom compiler that generates meaningful error messages, guiding the LLM towards improved accuracy. The experiments demonstrate a 26\% increase in the number of assertions free from syntax errors using this approach, showcasing its potential to streamline the FPV process.
Quantizing YOLOv7: A Comprehensive Study
Jul 06, 2024



YOLO is a deep neural network (DNN) model presented for robust real-time object detection following the one-stage inference approach. It outperforms other real-time object detectors in terms of speed and accuracy by a wide margin. Nevertheless, since YOLO is developed upon a DNN backbone with numerous parameters, it will cause excessive memory load, thereby deploying it on memory-constrained devices is a severe challenge in practice. To overcome this limitation, model compression techniques, such as quantizing parameters to lower-precision values, can be adopted. As the most recent version of YOLO, YOLOv7 achieves such state-of-the-art performance in speed and accuracy in the range of 5 FPS to 160 FPS that it surpasses all former versions of YOLO and other existing models in this regard. So far, the robustness of several quantization schemes has been evaluated on older versions of YOLO. These methods may not necessarily yield similar results for YOLOv7 as it utilizes a different architecture. In this paper, we conduct in-depth research on the effectiveness of a variety of quantization schemes on the pre-trained weights of the state-of-the-art YOLOv7 model. Experimental results demonstrate that using 4-bit quantization coupled with the combination of different granularities results in ~3.92x and ~3.86x memory-saving for uniform and non-uniform quantization, respectively, with only 2.5% and 1% accuracy loss compared to the full-precision baseline model.
ZOBNN: Zero-Overhead Dependable Design of Binary Neural Networks with Deliberately Quantized Parameters
Jul 06, 2024



Low-precision weights and activations in deep neural networks (DNNs) outperform their full-precision counterparts in terms of hardware efficiency. When implemented with low-precision operations, specifically in the extreme case where network parameters are binarized (i.e. BNNs), the two most frequently mentioned benefits of quantization are reduced memory consumption and a faster inference process. In this paper, we introduce a third advantage of very low-precision neural networks: improved fault-tolerance attribute. We investigate the impact of memory faults on state-of-the-art binary neural networks (BNNs) through comprehensive analysis. Despite the inclusion of floating-point parameters in BNN architectures to improve accuracy, our findings reveal that BNNs are highly sensitive to deviations in these parameters caused by memory faults. In light of this crucial finding, we propose a technique to improve BNN dependability by restricting the range of float parameters through a novel deliberately uniform quantization. The introduced quantization technique results in a reduction in the proportion of floating-point parameters utilized in the BNN, without incurring any additional computational overheads during the inference stage. The extensive experimental fault simulation on the proposed BNN architecture (i.e. ZOBNN) reveal a remarkable 5X enhancement in robustness compared to conventional floating-point DNN. Notably, this improvement is achieved without incurring any computational overhead. Crucially, this enhancement comes without computational overhead. \ToolName~excels in critical edge applications characterized by limited computational resources, prioritizing both dependability and real-time performance.
DNN Memory Footprint Reduction via Post-Training Intra-Layer Multi-Precision Quantization
Apr 03, 2024



The imperative to deploy Deep Neural Network (DNN) models on resource-constrained edge devices, spurred by privacy concerns, has become increasingly apparent. To facilitate the transition from cloud to edge computing, this paper introduces a technique that effectively reduces the memory footprint of DNNs, accommodating the limitations of resource-constrained edge devices while preserving model accuracy. Our proposed technique, named Post-Training Intra-Layer Multi-Precision Quantization (PTILMPQ), employs a post-training quantization approach, eliminating the need for extensive training data. By estimating the importance of layers and channels within the network, the proposed method enables precise bit allocation throughout the quantization process. Experimental results demonstrate that PTILMPQ offers a promising solution for deploying DNNs on edge devices with restricted memory resources. For instance, in the case of ResNet50, it achieves an accuracy of 74.57\% with a memory footprint of 9.5 MB, representing a 25.49\% reduction compared to previous similar methods, with only a minor 1.08\% decrease in accuracy.
A Decision Making Approach for Chemotherapy Planning based on Evolutionary Processing
Mar 19, 2023



The problem of chemotherapy treatment optimization can be defined in order to minimize the size of the tumor without endangering the patient's health; therefore, chemotherapy requires to achieve a number of objectives, simultaneously. For this reason, the optimization problem turns to a multi-objective problem. In this paper, a multi-objective meta-heuristic method is provided for cancer chemotherapy with the aim of balancing between two objectives: the amount of toxicity and the number of cancerous cells. The proposed method uses mathematical models in order to measure the drug concentration, tumor growth and the amount of toxicity. This method utilizes a Multi-Objective Particle Swarm Optimization (MOPSO) algorithm to optimize cancer chemotherapy plan using cell-cycle specific drugs. The proposed method can be a good model for personalized medicine as it returns a set of solutions as output that have balanced between different objectives and provided the possibility to choose the most appropriate therapeutic plan based on some information about the status of the patient. Experimental results confirm that the proposed method is able to explore the search space efficiently in order to find out the suitable treatment plan with minimal side effects. This main objective is provided using a desirable designing of chemotherapy drugs and controlling the injection dose. Moreover, results show that the proposed method achieve to a better therapeutic performance compared to a more recent similar method [1].
BDFA: A Blind Data Adversarial Bit-flip Attack on Deep Neural Networks
Jan 07, 2022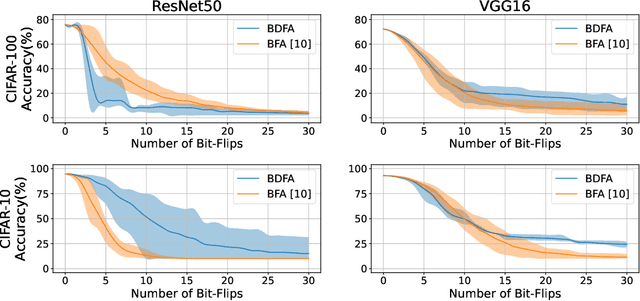

Adversarial bit-flip attack (BFA) on Neural Network weights can result in catastrophic accuracy degradation by flipping a very small number of bits. A major drawback of prior bit flip attack techniques is their reliance on test data. This is frequently not possible for applications that contain sensitive or proprietary data. In this paper, we propose Blind Data Adversarial Bit-flip Attack (BDFA), a novel technique to enable BFA without any access to the training or testing data. This is achieved by optimizing for a synthetic dataset, which is engineered to match the statistics of batch normalization across different layers of the network and the targeted label. Experimental results show that BDFA could decrease the accuracy of ResNet50 significantly from 75.96\% to 13.94\% with only 4 bits flips.
FitAct: Error Resilient Deep Neural Networks via Fine-Grained Post-Trainable Activation Functions
Dec 27, 2021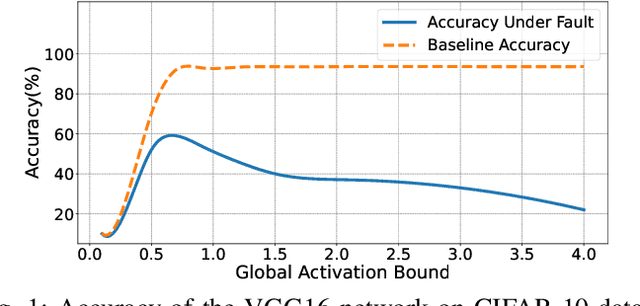
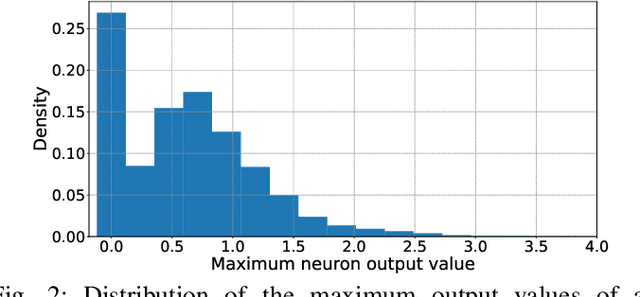
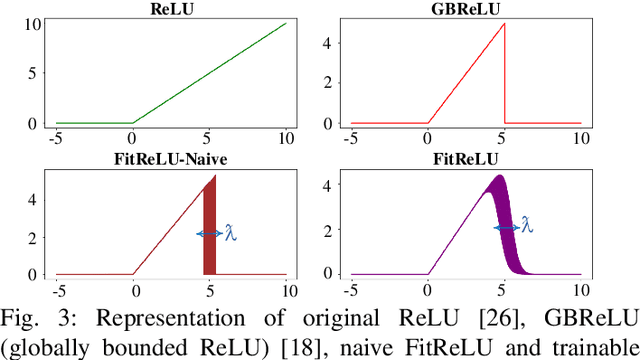
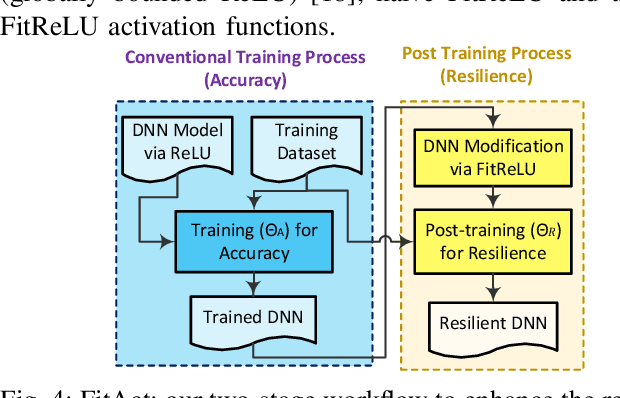
Deep neural networks (DNNs) are increasingly being deployed in safety-critical systems such as personal healthcare devices and self-driving cars. In such DNN-based systems, error resilience is a top priority since faults in DNN inference could lead to mispredictions and safety hazards. For latency-critical DNN inference on resource-constrained edge devices, it is nontrivial to apply conventional redundancy-based fault tolerance techniques. In this paper, we propose FitAct, a low-cost approach to enhance the error resilience of DNNs by deploying fine-grained post-trainable activation functions. The main idea is to precisely bound the activation value of each individual neuron via neuron-wise bounded activation functions so that it could prevent fault propagation in the network. To avoid complex DNN model re-training, we propose to decouple the accuracy training and resilience training and develop a lightweight post-training phase to learn these activation functions with precise bound values. Experimental results on widely used DNN models such as AlexNet, VGG16, and ResNet50 demonstrate that FitAct outperforms state-of-the-art studies such as Clip-Act and Ranger in enhancing the DNN error resilience for a wide range of fault rates while adding manageable runtime and memory space overheads.