 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DM-WeConvene: Learned Image Compression with 3D Multi-Level Wavelet-Domain Convolution and Entropy Model
Apr 07, 2025



Learned image compression (LIC) has recently made significant progress, surpassing traditional methods. However, most LIC approaches operate mainly in the spatial domain and lack mechanisms for reducing frequency-domain correlations. To address this, we propose a novel framework that integrates low-complexity 3D multi-level Discrete Wavelet Transform (DWT) into convolutional layers and entropy coding, reducing both spatial and channel correlations to improve frequency selectivity and rate-distortion (R-D) performance. Our proposed 3D multi-level wavelet-domain convolution (3DM-WeConv) layer first applies 3D multi-level DWT (e.g., 5/3 and 9/7 wavelets from JPEG 2000) to transform data into the wavelet domain. Then, different-sized convolutions are applied to different frequency subbands, followed by inverse 3D DWT to restore the spatial domain. The 3DM-WeConv layer can be flexibly used within existing CNN-based LIC models. We also introduce a 3D wavelet-domain channel-wise autoregressive entropy model (3DWeChARM), which performs slice-based entropy coding in the 3D DWT domain. Low-frequency (LF) slices are encoded first to provide priors for high-frequency (HF) slices. A two-step training strategy is adopted: first balancing LF and HF rates, then fine-tuning with separate weights. Extensive experiments demonstrate that our framework consistently outperforms state-of-the-art CNN-based LIC methods in R-D performance and computational complexity, with larger gains for high-resolution images. On the Kodak, Tecnick 100, and CLIC test sets, our method achieves BD-Rate reductions of -12.24%, -15.51%, and -12.97%, respectively, compared to H.266/VVC.
SELIC: Semantic-Enhanced Learned Image Compression via High-Level Textual Guidance
Apr 02, 2025Learned image compression (LIC) techniques have achieved remarkable progress; however, effectively integrating high-level semantic information remains challenging. In this work, we present a \underline{S}emantic-\underline{E}nhanced \underline{L}earned \underline{I}mage \underline{C}ompression framework, termed \textbf{SELIC}, which leverages high-level textual guidance to improve rate-distortion performance. Specifically, \textbf{SELIC} employs a text encoder to extract rich semantic descriptions from the input image. These textual features are transformed into fixed-dimension tensors and seamlessly fused with the image-derived latent representation. By embedding the \textbf{SELIC} tensor directly into the compression pipeline, our approach enriches the bitstream without requiring additional inputs at the decoder, thereby maintaining fast and efficient decoding. Extensive experiments on benchmark datasets (e.g., Kodak) demonstrate that integrating semantic information substantially enhances compression quality. Our \textbf{SELIC}-guided method outperforms a baseline LIC model without semantic integration by approximately 0.1-0.15 dB across a wide range of bit rates in PSNR and achieves a 4.9\% BD-rate improvement over VVC. Moreover, this improvement comes with minimal computational overhead, making the proposed \textbf{SELIC} framework a practical solution for advanced image compression applications.
FEDS: Feature and Entropy-Based Distillation Strategy for Efficient Learned Image Compression
Mar 09, 2025Learned image compression (LIC) methods have recently outperformed traditional codecs such as VVC in rate-distortion performance. However, their large models and high computational costs have limited their practical adoption. In this paper, we first construct a high-capacity teacher model by integrating Swin-Transformer V2-based attention modules, additional residual blocks, and expanded latent channels, thus achieving enhanced compression performance. Building on this foundation, we propose a \underline{F}eature and \underline{E}ntropy-based \underline{D}istillation \underline{S}trategy (\textbf{FEDS}) that transfers key knowledge from the teacher to a lightweight student model. Specifically, we align intermediate feature representations and emphasize the most informative latent channels through an entropy-based loss. A staged training scheme refines this transfer in three phases: feature alignment, channel-level distillation, and final fine-tuning. Our student model nearly matches the teacher across Kodak (1.24\% BD-Rate increase), Tecnick (1.17\%), and CLIC (0.55\%) while cutting parameters by about 63\% and accelerating encoding/decoding by around 73\%. Moreover, ablation studies indicate that FEDS generalizes effectively to transformer-based networks. The experimental results demonstrate our approach strikes a compelling balance among compression performance, speed, and model parameters, making it well-suited for real-time or resource-limited scenarios.
Towards Accurate and Efficient Sub-8-Bit Integer Training
Nov 17, 2024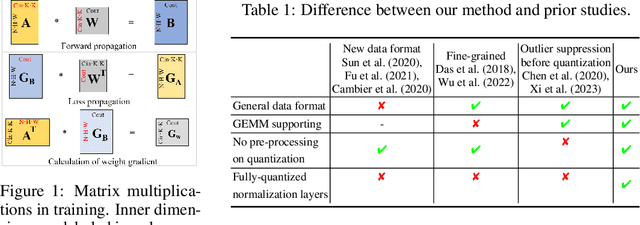
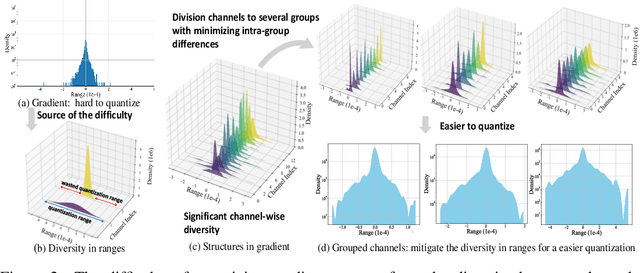
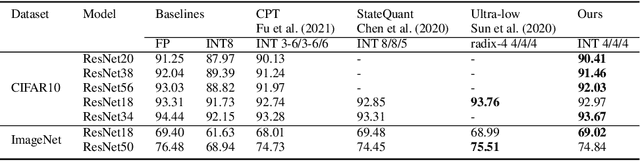
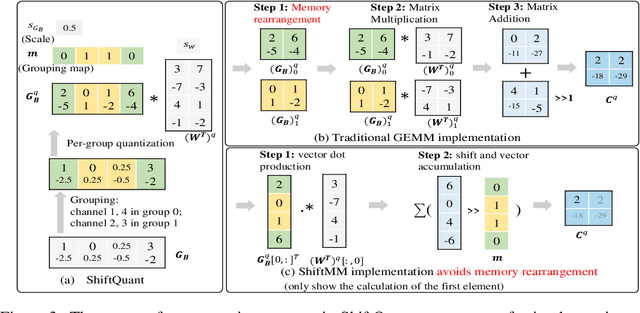
Neural network training is a memory- and compute-intensive task. Quantization, which enables low-bitwidth formats in training, can significantly mitigate the workload. To reduce quantization error, recent methods have developed new data formats and additional pre-processing operations on quantizers. However, it remains quite challenging to achieve high accuracy and efficiency simultaneously. In this paper, we explore sub-8-bit integer training from its essence of gradient descent optimization. Our integer training framework includes two components: ShiftQuant to realize accurate gradient estimation, and L1 normalization to smoothen the loss landscape. ShiftQuant attains performance that approaches the theoretical upper bound of group quantization. Furthermore, it liberates group quantization from inefficient memory rearrangement. The L1 normalization facilitates the implementation of fully quantized normalization layers with impressive convergence accuracy. Our method frees sub-8-bit integer training from pre-processing and supports general devices. This framework achieves negligible accuracy loss across various neural networks and tasks ($0.92\%$ on 4-bit ResNets, $0.61\%$ on 6-bit Transformers). The prototypical implementation of ShiftQuant achieves more than $1.85\times/15.3\%$ performance improvement on CPU/GPU compared to its FP16 counterparts, and $33.9\%$ resource consumption reduction on FPGA than the FP16 counterparts. The proposed fully-quantized L1 normalization layers achieve more than $35.54\%$ improvement in throughout on CPU compared to traditional L2 normalization layers. Moreover, theoretical analysis verifies the advancement of our method.
Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers
Jul 25, 2024

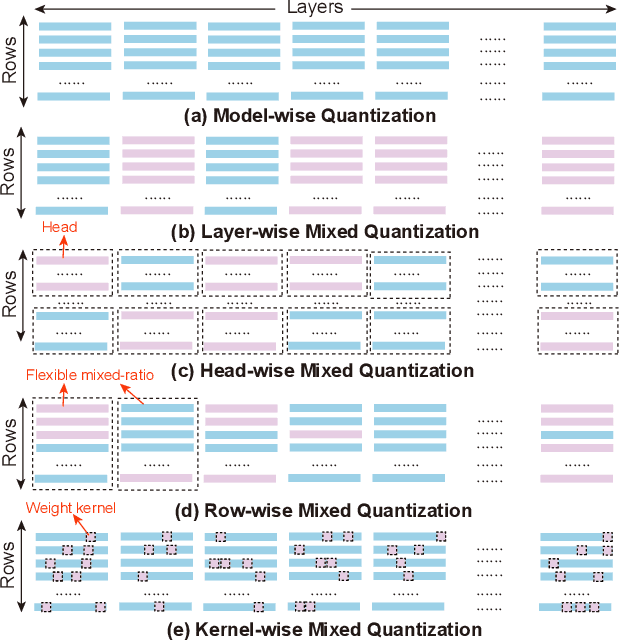

Vision transformers (ViTs) have demonstrated their superior accuracy for computer vision tasks compared to convolutional neural networks (CNNs). However, ViT models are often computation-intensive for efficient deployment on resource-limited edge devices. This work proposes Quasar-ViT, a hardware-oriented quantization-aware architecture search framework for ViTs, to design efficient ViT models for hardware implementation while preserving the accuracy. First, Quasar-ViT trains a supernet using our row-wise flexible mixed-precision quantization scheme, mixed-precision weight entanglement, and supernet layer scaling techniques. Then, it applies an efficient hardware-oriented search algorithm, integrated with hardware latency and resource modeling, to determine a series of optimal subnets from supernet under different inference latency targets. Finally, we propose a series of model-adaptive designs on the FPGA platform to support the architecture search and mitigate the gap between the theoretical computation reduction and the practical inference speedup. Our searched models achieve 101.5, 159.6, and 251.6 frames-per-second (FPS) inference speed on the AMD/Xilinx ZCU102 FPGA with 80.4%, 78.6%, and 74.9% top-1 accuracy, respectively, for the ImageNet dataset, consistently outperforming prior works.
HeatViT: Hardware-Efficient Adaptive Token Pruning for Vision Transformers
Nov 15, 2022



While vision transformers (ViTs) have continuously achieved new milestones in the field of computer vision, their sophisticated network architectures with high computation and memory costs have impeded their deployment on resource-limited edge devices. In this paper, we propose a hardware-efficient image-adaptive token pruning framework called HeatViT for efficient yet accurate ViT acceleration on embedded FPGAs. By analyzing the inherent computational patterns in ViTs, we first design an effective attention-based multi-head token selector, which can be progressively inserted before transformer blocks to dynamically identify and consolidate the non-informative tokens from input images. Moreover, we implement the token selector on hardware by adding miniature control logic to heavily reuse existing hardware components built for the backbone ViT. To improve the hardware efficiency, we further employ 8-bit fixed-point quantization, and propose polynomial approximations with regularization effect on quantization error for the frequently used nonlinear functions in ViTs. Finally, we propose a latency-aware multi-stage training strategy to determine the transformer blocks for inserting token selectors and optimize the desired (average) pruning rates for inserted token selectors, in order to improve both the model accuracy and inference latency on hardware. Compared to existing ViT pruning studies, under the similar computation cost, HeatViT can achieve 0.7%$\sim$8.9% higher accuracy; while under the similar model accuracy, HeatViT can achieve more than 28.4%$\sim$65.3% computation reduction, for various widely used ViTs, including DeiT-T, DeiT-S, DeiT-B, LV-ViT-S, and LV-ViT-M, on the ImageNet dataset. Compared to the baseline hardware accelerator, our implementations of HeatViT on the Xilinx ZCU102 FPGA achieve 3.46$\times$$\sim$4.89$\times$ speedup.
SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery
Sep 27, 2022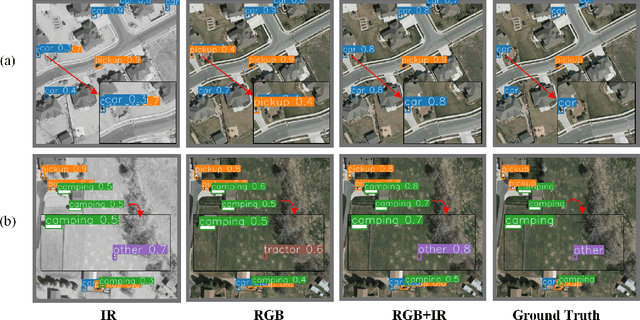
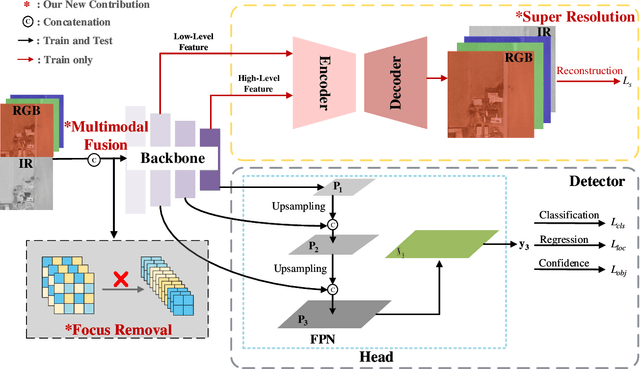
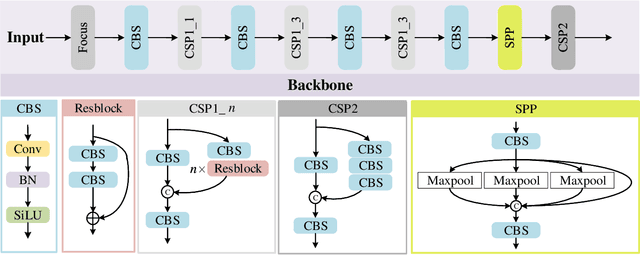
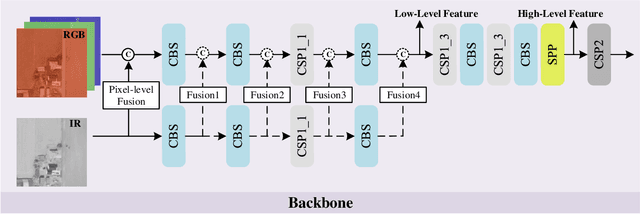
In this paper, we propose an accurate yet fast small object detection method for RSI, named SuperYOLO, which fuses multimodal data and performs high resolution (HR) object detection on multiscale objects by utilizing the assisted super resolution (SR) learning and considering both the detection accuracy and computation cost. First, we construct a compact baseline by removing the Focus module to keep the HR features and significantly overcomes the missing error of small objects. Second, we utilize pixel-level multimodal fusion (MF) to extract information from various data to facilitate more suitable and effective features for small objects in RSI. Furthermore, we design a simple and flexible SR branch to learn HR feature representations that can discriminate small objects from vast backgrounds with low-resolution (LR) input, thus further improving the detection accuracy. Moreover, to avoid introducing additional computation, the SR branch is discarded in the inference stage and the computation of the network model is reduced due to the LR input. Experimental results show that, on the widely used VEDAI RS dataset, SuperYOLO achieves an accuracy of 73.61% (in terms of mAP50), which is more than 10% higher than the SOTA large models such as YOLOv5l, YOLOv5x and RS designed YOLOrs. Meanwhile, the GFOLPs and parameter size of SuperYOLO are about 18.1x and 4.2x less than YOLOv5x. Our proposed model shows a favorable accuracy-speed trade-off compared to the state-of-art models. The code will be open sourced at https://github.com/icey-zhang/SuperYOLO.
Auto-ViT-Acc: An FPGA-Aware Automatic Acceleration Framework for Vision Transformer with Mixed-Scheme Quantization
Aug 10, 2022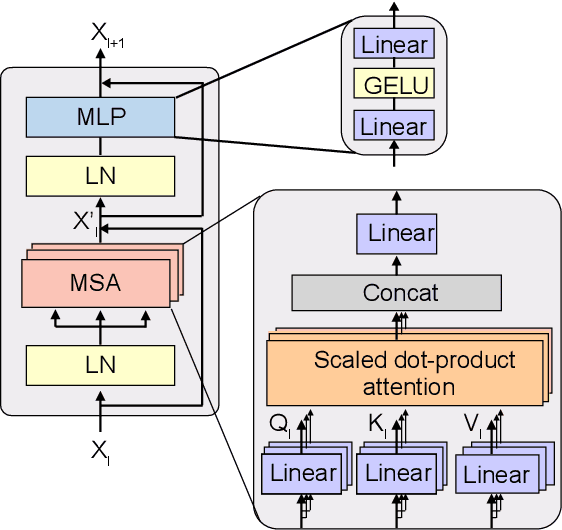
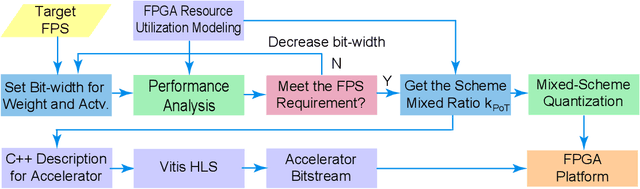
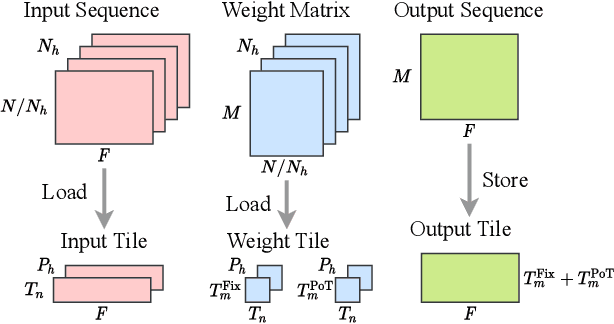
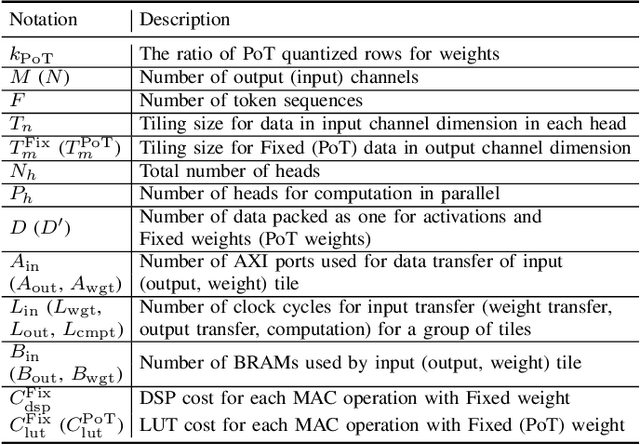
Vision transformers (ViTs) are emerging with significantly improved accuracy in computer vision tasks. However, their complex architecture and enormous computation/storage demand impose urgent needs for new hardware accelerator design methodology. This work proposes an FPGA-aware automatic ViT acceleration framework based on the proposed mixed-scheme quantization. To the best of our knowledge, this is the first FPGA-based ViT acceleration framework exploring model quantization. Compared with state-of-the-art ViT quantization work (algorithmic approach only without hardware acceleration), our quantization achieves 0.47% to 1.36% higher Top-1 accuracy under the same bit-width. Compared with the 32-bit floating-point baseline FPGA accelerator, our accelerator achieves around 5.6x improvement on the frame rate (i.e., 56.8 FPS vs. 10.0 FPS) with 0.71% accuracy drop on ImageNet dataset for DeiT-base.
BDFA: A Blind Data Adversarial Bit-flip Attack on Deep Neural Networks
Jan 07, 2022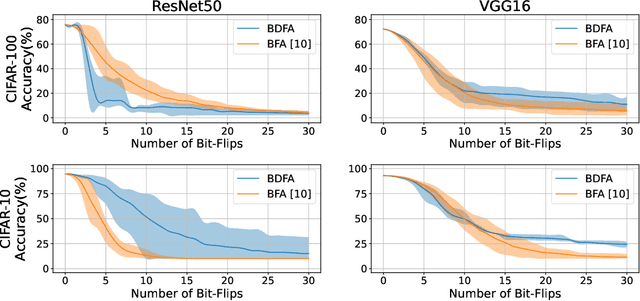

Adversarial bit-flip attack (BFA) on Neural Network weights can result in catastrophic accuracy degradation by flipping a very small number of bits. A major drawback of prior bit flip attack techniques is their reliance on test data. This is frequently not possible for applications that contain sensitive or proprietary data. In this paper, we propose Blind Data Adversarial Bit-flip Attack (BDFA), a novel technique to enable BFA without any access to the training or testing data. This is achieved by optimizing for a synthetic dataset, which is engineered to match the statistics of batch normalization across different layers of the network and the targeted label. Experimental results show that BDFA could decrease the accuracy of ResNet50 significantly from 75.96\% to 13.94\% with only 4 bits flips.
FitAct: Error Resilient Deep Neural Networks via Fine-Grained Post-Trainable Activation Functions
Dec 27, 2021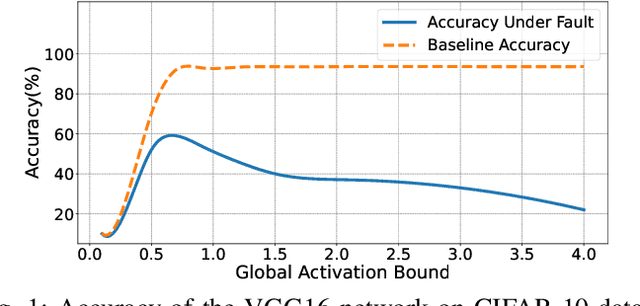
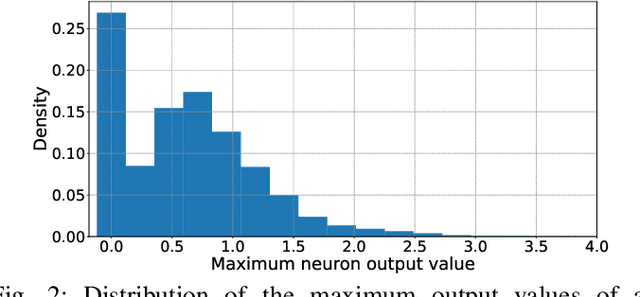
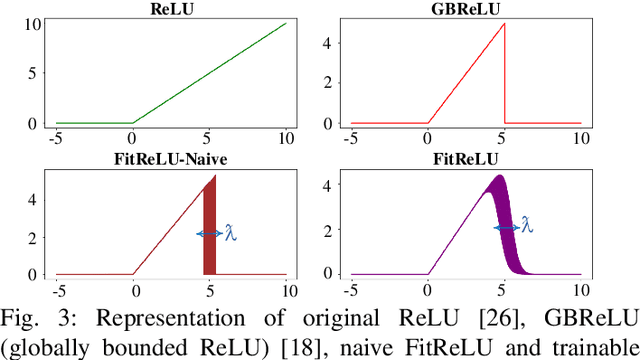
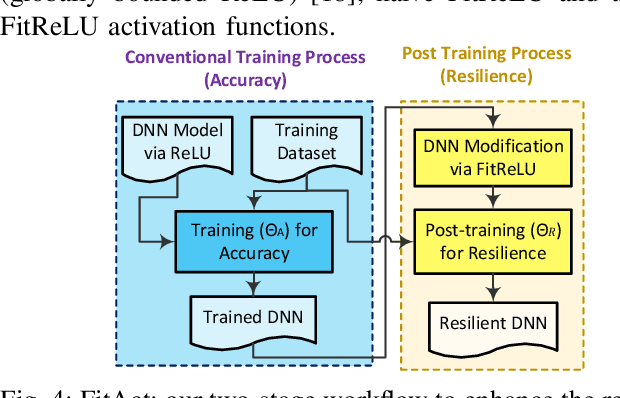
Deep neural networks (DNNs) are increasingly being deployed in safety-critical systems such as personal healthcare devices and self-driving cars. In such DNN-based systems, error resilience is a top priority since faults in DNN inference could lead to mispredictions and safety hazards. For latency-critical DNN inference on resource-constrained edge devices, it is nontrivial to apply conventional redundancy-based fault tolerance techniques. In this paper, we propose FitAct, a low-cost approach to enhance the error resilience of DNNs by deploying fine-grained post-trainable activation functions. The main idea is to precisely bound the activation value of each individual neuron via neuron-wise bounded activation functions so that it could prevent fault propagation in the network. To avoid complex DNN model re-training, we propose to decouple the accuracy training and resilience training and develop a lightweight post-training phase to learn these activation functions with precise bound values. Experimental results on widely used DNN models such as AlexNet, VGG16, and ResNet50 demonstrate that FitAct outperforms state-of-the-art studies such as Clip-Act and Ranger in enhancing the DNN error resilience for a wide range of fault rates while adding manageable runtime and memory space overheads.