 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DM-WeConvene: Learned Image Compression with 3D Multi-Level Wavelet-Domain Convolution and Entropy Model
Apr 07, 2025



Learned image compression (LIC) has recently made significant progress, surpassing traditional methods. However, most LIC approaches operate mainly in the spatial domain and lack mechanisms for reducing frequency-domain correlations. To address this, we propose a novel framework that integrates low-complexity 3D multi-level Discrete Wavelet Transform (DWT) into convolutional layers and entropy coding, reducing both spatial and channel correlations to improve frequency selectivity and rate-distortion (R-D) performance. Our proposed 3D multi-level wavelet-domain convolution (3DM-WeConv) layer first applies 3D multi-level DWT (e.g., 5/3 and 9/7 wavelets from JPEG 2000) to transform data into the wavelet domain. Then, different-sized convolutions are applied to different frequency subbands, followed by inverse 3D DWT to restore the spatial domain. The 3DM-WeConv layer can be flexibly used within existing CNN-based LIC models. We also introduce a 3D wavelet-domain channel-wise autoregressive entropy model (3DWeChARM), which performs slice-based entropy coding in the 3D DWT domain. Low-frequency (LF) slices are encoded first to provide priors for high-frequency (HF) slices. A two-step training strategy is adopted: first balancing LF and HF rates, then fine-tuning with separate weights. Extensive experiments demonstrate that our framework consistently outperforms state-of-the-art CNN-based LIC methods in R-D performance and computational complexity, with larger gains for high-resolution images. On the Kodak, Tecnick 100, and CLIC test sets, our method achieves BD-Rate reductions of -12.24%, -15.51%, and -12.97%, respectively, compared to H.266/VVC.
Fast and High-Performance Learned Image Compression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation
Sep 05, 2023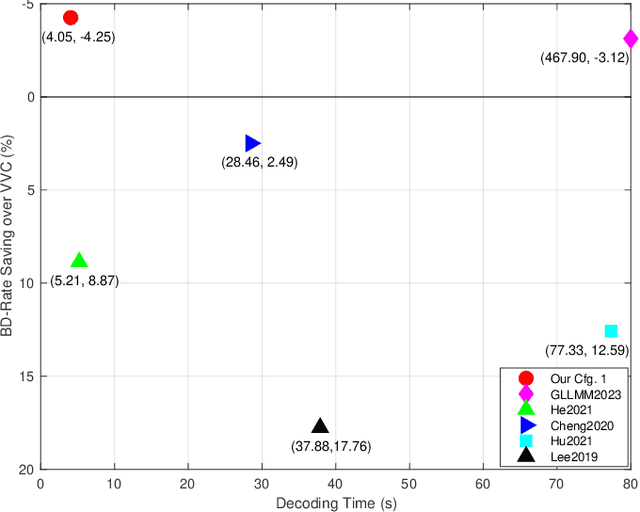



Deep learning-based image compression has made great progresses recently. However, many leading schemes use serial context-adaptive entropy model to improve the rate-distortion (R-D) performance, which is very slow. In addition, the complexities of the encoding and decoding networks are quite high and not suitable for many practical applications. In this paper, we introduce four techniques to balance the trade-off between the complexity and performance. We are the first to introduce deformable convolutional module in compression framework, which can remove more redundancies in the input image, thereby enhancing compression performance. Second, we design a checkerboard context model with two separate distribution parameter estimation networks and different probability models, which enables parallel decoding without sacrificing the performance compared to the sequential context-adaptive model. Third, we develop an improved three-step knowledge distillation and training scheme to achieve different trade-offs between the complexity and the performance of the decoder network, which transfers both the final and intermediate results of the teacher network to the student network to help its training. Fourth, we introduce $L_{1}$ regularization to make the numerical values of the latent representation more sparse. Then we only encode non-zero channels in the encoding and decoding process, which can greatly reduce the encoding and decoding time. Experiments show that compared to the state-of-the-art learned image coding scheme, our method can be about 20 times faster in encoding and 70-90 times faster in decoding, and our R-D performance is also $2.3 \%$ higher. Our method outperforms the traditional approach in H.266/VVC-intra (4:4:4) and some leading learned schemes in terms of PSNR and MS-SSIM metrics when testing on Kodak and Tecnick-40 datasets.
Asymmetric Learned Image Compression with Multi-Scale Residual Block, Importance Map, and Post-Quantization Filtering
Jun 21, 2022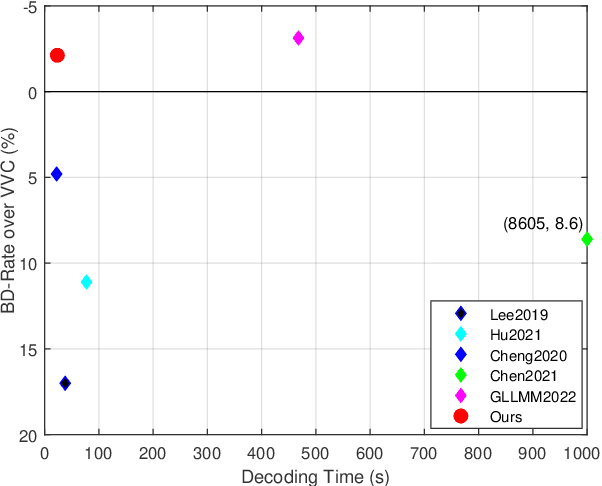



Recently, deep learning-based image compression has made signifcant progresses, and has achieved better ratedistortion (R-D) performance than the latest traditional method, H.266/VVC, in both subjective metric and the more challenging objective metric. However, a major problem is that many leading learned schemes cannot maintain a good trade-off between performance and complexity. In this paper, we propose an effcient and effective image coding framework, which achieves similar R-D performance with lower complexity than the state of the art. First, we develop an improved multi-scale residual block (MSRB) that can expand the receptive feld and is easier to obtain global information. It can further capture and reduce the spatial correlation of the latent representations. Second, a more advanced importance map network is introduced to adaptively allocate bits to different regions of the image. Third, we apply a 2D post-quantization flter (PQF) to reduce the quantization error, motivated by the Sample Adaptive Offset (SAO) flter in video coding. Moreover, We fnd that the complexity of encoder and decoder have different effects on image compression performance. Based on this observation, we design an asymmetric paradigm, in which the encoder employs three stages of MSRBs to improve the learning capacity, whereas the decoder only needs one stage of MSRB to yield satisfactory reconstruction, thereby reducing the decoding complexity without sacrifcing performance. Experimental results show that compared to the state-of-the-art method, the encoding and decoding time of the proposed method are about 17 times faster, and the R-D performance is only reduced by less than 1% on both Kodak and Tecnick datasets, which is still better than H.266/VVC(4:4:4) and other recent learning-based methods. Our source code is publicly available at https://github.com/fengyurenpingsheng.
Learned Image Compression with Discretized Gaussian-Laplacian-Logistic Mixture Model and Concatenated Residual Modules
Jul 18, 2021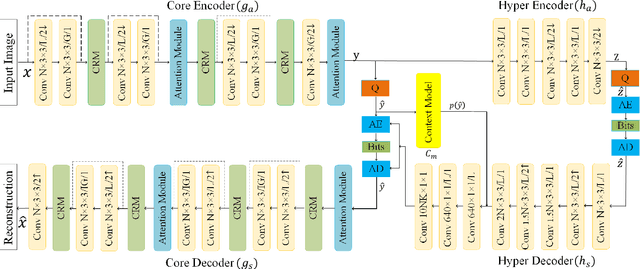
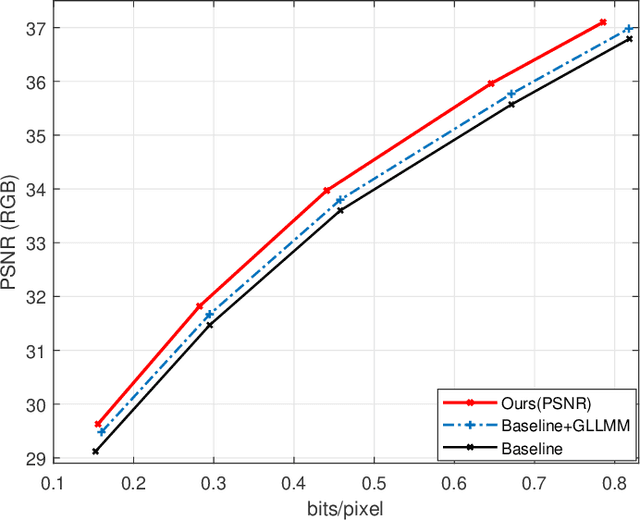
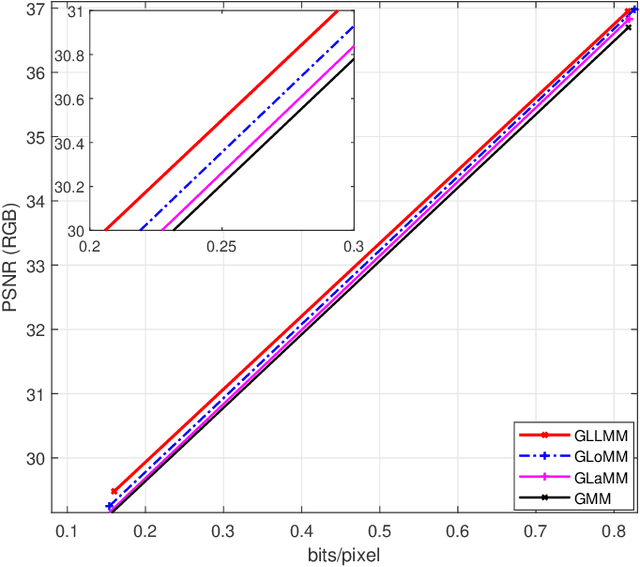
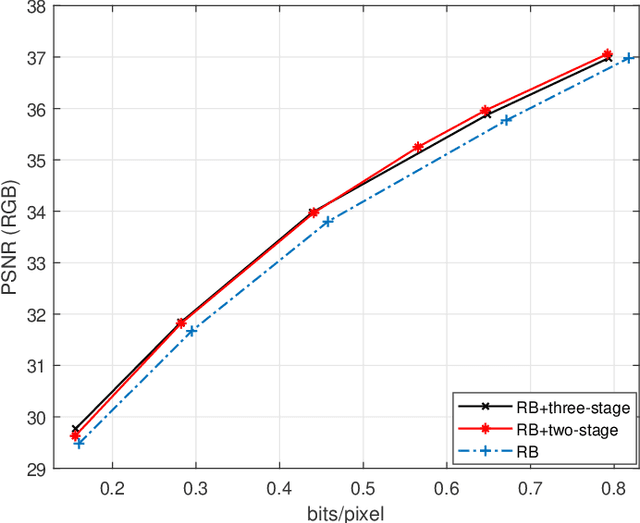
Recently deep learning-based image compression methods have achieved significant achievements and gradually outperformed traditional approaches including the latest standard Versatile Video Coding (VVC) in both PSNR and MS-SSIM metrics. Two key components of learned image compression frameworks are the entropy model of the latent representations and the encoding/decoding network architectures. Various models have been proposed, such as autoregressive, softmax, logistic mixture, Gaussian mixture, and Laplacian. Existing schemes only use one of these models. However, due to the vast diversity of images, it is not optimal to use one model for all images, even different regions of one image. In this paper, we propose a more flexible discretized Gaussian-Laplacian-Logistic mixture model (GLLMM) for the latent representations, which can adapt to different contents in different images and different regions of one image more accurately. Besides, in the encoding/decoding network design part, we propose a concatenated residual blocks (CRB), where multiple residual blocks are serially connected with additional shortcut connections. The CRB can improve the learning ability of the network, which can further improve the compression performance. Experimental results using the Kodak and Tecnick datasets show that the proposed scheme outperforms all the state-of-the-art learning-based methods and existing compression standards including VVC intra coding (4:4:4 and 4:2:0) in terms of the PSNR and MS-SSIM. The project page is at \url{https://github.com/fengyurenpingsheng/Learned-image-compression-with-GLLMM}