 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROI-based Deep Image Compression with Swin Transformers
May 12, 2023Encoding the Region Of Interest (ROI) with better quality than the background has many applications including video conferencing systems, video surveillance and object-oriented vision tasks. In this paper, we propose a ROI-based image compression framework with Swin transformers as main building blocks for the autoencoder network. The binary ROI mask is integrated into different layers of the network to provide spatial information guidance. Based on the ROI mask, we can control the relative importance of the ROI and non-ROI by modifying the corresponding Lagrange multiplier $ \lambda $ for different regions. Experimental results show our model achieves higher ROI PSNR than other methods and modest average PSNR for human evaluation. When tested on models pre-trained with original images, it has superior object detection and instance segmentation performance on the COCO validation dataset.
Asymmetric Learned Image Compression with Multi-Scale Residual Block, Importance Map, and Post-Quantization Filtering
Jun 21, 2022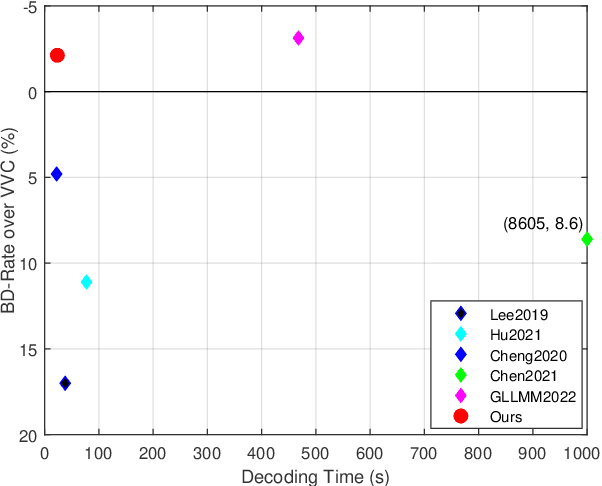



Recently, deep learning-based image compression has made signifcant progresses, and has achieved better ratedistortion (R-D) performance than the latest traditional method, H.266/VVC, in both subjective metric and the more challenging objective metric. However, a major problem is that many leading learned schemes cannot maintain a good trade-off between performance and complexity. In this paper, we propose an effcient and effective image coding framework, which achieves similar R-D performance with lower complexity than the state of the art. First, we develop an improved multi-scale residual block (MSRB) that can expand the receptive feld and is easier to obtain global information. It can further capture and reduce the spatial correlation of the latent representations. Second, a more advanced importance map network is introduced to adaptively allocate bits to different regions of the image. Third, we apply a 2D post-quantization flter (PQF) to reduce the quantization error, motivated by the Sample Adaptive Offset (SAO) flter in video coding. Moreover, We fnd that the complexity of encoder and decoder have different effects on image compression performance. Based on this observation, we design an asymmetric paradigm, in which the encoder employs three stages of MSRBs to improve the learning capacity, whereas the decoder only needs one stage of MSRB to yield satisfactory reconstruction, thereby reducing the decoding complexity without sacrifcing performance. Experimental results show that compared to the state-of-the-art method, the encoding and decoding time of the proposed method are about 17 times faster, and the R-D performance is only reduced by less than 1% on both Kodak and Tecnick datasets, which is still better than H.266/VVC(4:4:4) and other recent learning-based methods. Our source code is publicly available at https://github.com/fengyurenpingsheng.
Reproducing Kernels and New Approaches in Compositional Data Analysis
May 02, 2022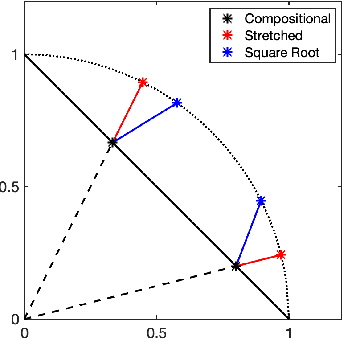

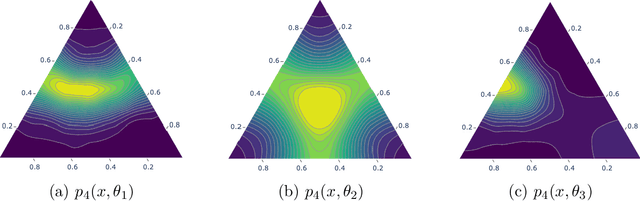
Compositional data, such as human gut microbiomes, consist of non-negative variables whose only the relative values to other variables are available. Analyzing compositional data such as human gut microbiomes needs a careful treatment of the geometry of the data. A common geometrical understanding of compositional data is via a regular simplex. Majority of existing approaches rely on a log-ratio or power transformations to overcome the innate simplicial geometry. In this work, based on the key observation that a compositional data are projective in nature, and on the intrinsic connection between projective and spherical geometry, we re-interpret the compositional domain as the quotient topology of a sphere modded out by a group action. This re-interpretation allows us to understand the function space on compositional domains in terms of that on spheres and to use spherical harmonics theory along with reflection group actions for constructing a compositional Reproducing Kernel Hilbert Space (RKHS). This construction of RKHS for compositional data will widely open research avenues for future methodology developments. In particular, well-developed kernel embedding methods can be now introduced to compositional data analysis. The polynomial nature of compositional RKHS has both theoretical and computational benefits. The wide applicability of the proposed theoretical framework is exemplified with nonparametric density estimation and kernel exponential family for compositional data.
Skeleton-based Approaches based on Machine Vision: A Survey
Dec 23, 2020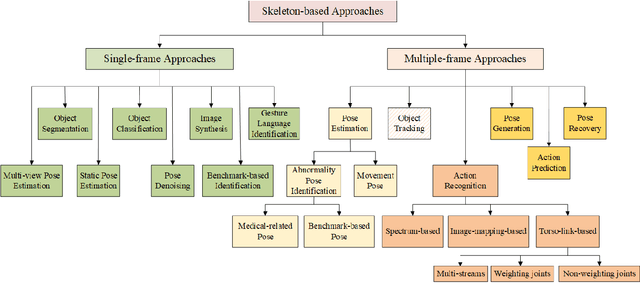
Recently, skeleton-based approaches have achieved rapid progress on the basis of great success in skeleton representation. Plenty of researches focus on solving specific problems according to skeleton features. Some skeleton-based approaches have been mentioned in several overviews on object detection as a non-essential part. Nevertheless, there has not been any thorough analysis of skeleton-based approaches attentively. Instead of describing these techniques in terms of theoretical constructs, we devote to summarizing skeleton-based approaches with regard to application fields and given tasks as comprehensively as possible. This paper is conducive to further understanding of skeleton-based application and dealing with particular issues.
Deep Learning-based Image Compression with Trellis Coded Quantization
Jan 26, 2020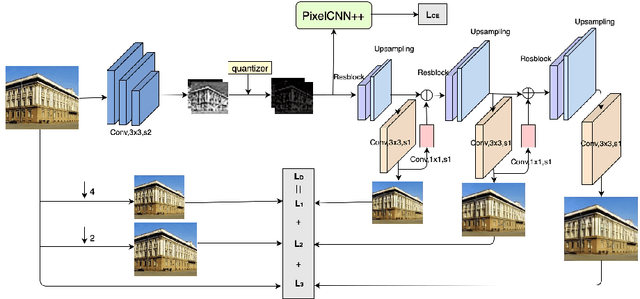
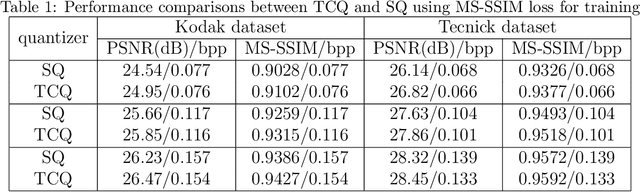
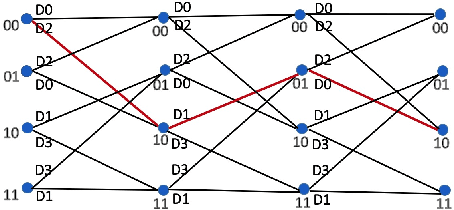
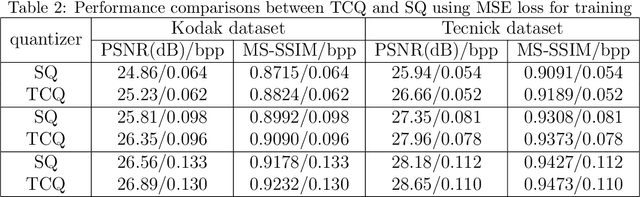
Recently many works attempt to develop image compression models based on deep learning architectures, where the uniform scalar quantizer (SQ) is commonly applied to the feature maps between the encoder and decoder. In this paper, we propose to incorporate trellis coded quantizer (TCQ) into a deep learning based image compression framework. A soft-to-hard strategy is applied to allow for back propagation during training. We develop a simple image compression model that consists of three subnetworks (encoder, decoder and entropy estimation), and optimize all of the components in an end-to-end manner. We experiment on two high resolution image datasets and both show that our model can achieve superior performance at low bit rates. We also show the comparisons between TCQ and SQ based on our proposed baseline model and demonstrate the advantage of TCQ.