 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSTC-MDA: A Unified Framework for Long-Short Term Temporal Convolution and Mixed Data Augmentation in Skeleton-Based Action Recognition
Sep 18, 2025Skeleton-based action recognition faces two longstanding challenges: the scarcity of labeled training samples and difficulty modeling short- and long-range temporal dependencies. To address these issues, we propose a unified framework, LSTC-MDA, which simultaneously improves temporal modeling and data diversity. We introduce a novel Long-Short Term Temporal Convolution (LSTC) module with parallel short- and long-term branches, these two feature branches are then aligned and fused adaptively using learned similarity weights to preserve critical long-range cues lost by conventional stride-2 temporal convolutions. We also extend Joint Mixing Data Augmentation (JMDA) with an Additive Mixup at the input level, diversifying training samples and restricting mixup operations to the same camera view to avoid distribution shifts. Ablation studies confirm each component contributes. LSTC-MDA achieves state-of-the-art results: 94.1% and 97.5% on NTU 60 (X-Sub and X-View), 90.4% and 92.0% on NTU 120 (X-Sub and X-Set),97.2% on NW-UCLA. Code: https://github.com/xiaobaoxia/LSTC-MDA.
3DM-WeConvene: Learned Image Compression with 3D Multi-Level Wavelet-Domain Convolution and Entropy Model
Apr 07, 2025



Learned image compression (LIC) has recently made significant progress, surpassing traditional methods. However, most LIC approaches operate mainly in the spatial domain and lack mechanisms for reducing frequency-domain correlations. To address this, we propose a novel framework that integrates low-complexity 3D multi-level Discrete Wavelet Transform (DWT) into convolutional layers and entropy coding, reducing both spatial and channel correlations to improve frequency selectivity and rate-distortion (R-D) performance. Our proposed 3D multi-level wavelet-domain convolution (3DM-WeConv) layer first applies 3D multi-level DWT (e.g., 5/3 and 9/7 wavelets from JPEG 2000) to transform data into the wavelet domain. Then, different-sized convolutions are applied to different frequency subbands, followed by inverse 3D DWT to restore the spatial domain. The 3DM-WeConv layer can be flexibly used within existing CNN-based LIC models. We also introduce a 3D wavelet-domain channel-wise autoregressive entropy model (3DWeChARM), which performs slice-based entropy coding in the 3D DWT domain. Low-frequency (LF) slices are encoded first to provide priors for high-frequency (HF) slices. A two-step training strategy is adopted: first balancing LF and HF rates, then fine-tuning with separate weights. Extensive experiments demonstrate that our framework consistently outperforms state-of-the-art CNN-based LIC methods in R-D performance and computational complexity, with larger gains for high-resolution images. On the Kodak, Tecnick 100, and CLIC test sets, our method achieves BD-Rate reductions of -12.24%, -15.51%, and -12.97%, respectively, compared to H.266/VVC.
SELIC: Semantic-Enhanced Learned Image Compression via High-Level Textual Guidance
Apr 02, 2025Learned image compression (LIC) techniques have achieved remarkable progress; however, effectively integrating high-level semantic information remains challenging. In this work, we present a \underline{S}emantic-\underline{E}nhanced \underline{L}earned \underline{I}mage \underline{C}ompression framework, termed \textbf{SELIC}, which leverages high-level textual guidance to improve rate-distortion performance. Specifically, \textbf{SELIC} employs a text encoder to extract rich semantic descriptions from the input image. These textual features are transformed into fixed-dimension tensors and seamlessly fused with the image-derived latent representation. By embedding the \textbf{SELIC} tensor directly into the compression pipeline, our approach enriches the bitstream without requiring additional inputs at the decoder, thereby maintaining fast and efficient decoding. Extensive experiments on benchmark datasets (e.g., Kodak) demonstrate that integrating semantic information substantially enhances compression quality. Our \textbf{SELIC}-guided method outperforms a baseline LIC model without semantic integration by approximately 0.1-0.15 dB across a wide range of bit rates in PSNR and achieves a 4.9\% BD-rate improvement over VVC. Moreover, this improvement comes with minimal computational overhead, making the proposed \textbf{SELIC} framework a practical solution for advanced image compression applications.
FEDS: Feature and Entropy-Based Distillation Strategy for Efficient Learned Image Compression
Mar 09, 2025Learned image compression (LIC) methods have recently outperformed traditional codecs such as VVC in rate-distortion performance. However, their large models and high computational costs have limited their practical adoption. In this paper, we first construct a high-capacity teacher model by integrating Swin-Transformer V2-based attention modules, additional residual blocks, and expanded latent channels, thus achieving enhanced compression performance. Building on this foundation, we propose a \underline{F}eature and \underline{E}ntropy-based \underline{D}istillation \underline{S}trategy (\textbf{FEDS}) that transfers key knowledge from the teacher to a lightweight student model. Specifically, we align intermediate feature representations and emphasize the most informative latent channels through an entropy-based loss. A staged training scheme refines this transfer in three phases: feature alignment, channel-level distillation, and final fine-tuning. Our student model nearly matches the teacher across Kodak (1.24\% BD-Rate increase), Tecnick (1.17\%), and CLIC (0.55\%) while cutting parameters by about 63\% and accelerating encoding/decoding by around 73\%. Moreover, ablation studies indicate that FEDS generalizes effectively to transformer-based networks. The experimental results demonstrate our approach strikes a compelling balance among compression performance, speed, and model parameters, making it well-suited for real-time or resource-limited scenarios.
S2LIC: Learned Image Compression with the SwinV2 Block, Adaptive Channel-wise and Global-inter Attention Context
Mar 21, 2024
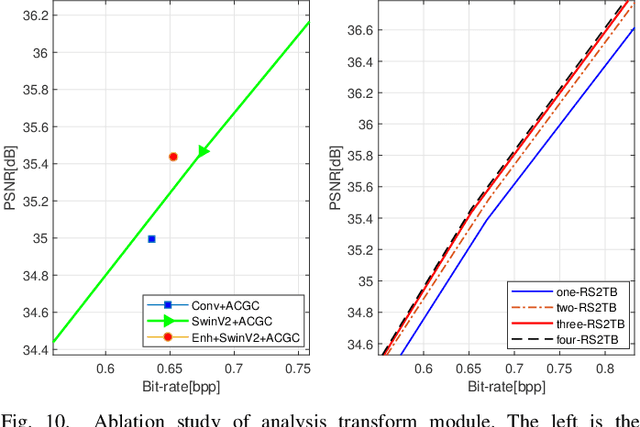


Recently, deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. It is crucial to design an effective and efficient entropy model to estimate the probability distribution of the latent representation. However, the majority of entropy models primarily focus on one-dimensional correlation processing between channel and spatial information. In this paper, we propose an Adaptive Channel-wise and Global-inter attention Context (ACGC) entropy model, which can efficiently achieve dual feature aggregation in both inter-slice and intraslice contexts. Specifically, we divide the latent representation into different slices and then apply the ACGC model in a parallel checkerboard context to achieve faster decoding speed and higher rate-distortion performance. In order to capture redundant global features across different slices, we utilize deformable attention in adaptive global-inter attention to dynamically refine the attention weights based on the actual spatial relationships and context. Furthermore, in the main transformation structure, we propose a high-performance S2LIC model. We introduce the residual SwinV2 Transformer model to capture global feature information and utilize a dense block network as the feature enhancement module to improve the nonlinear representation of the image within the transformation structure. Experimental results demonstrate that our method achieves faster encoding and decoding speeds and outperforms VTM-17.1 and some recent learned image compression methods in both PSNR and MS-SSIM metrics.
Fast and High-Performance Learned Image Compression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation
Sep 05, 2023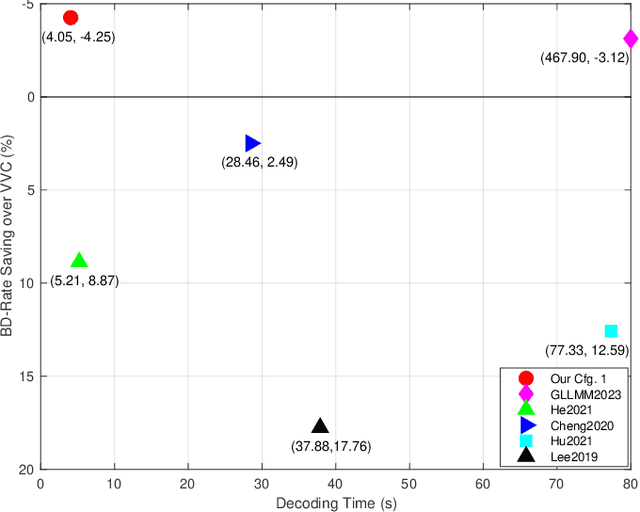



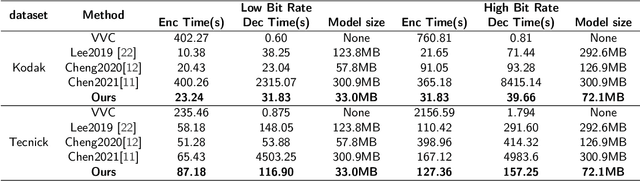
Deep learning-based image compression has made great progresses recently. However, many leading schemes use serial context-adaptive entropy model to improve the rate-distortion (R-D) performance, which is very slow. In addition, the complexities of the encoding and decoding networks are quite high and not suitable for many practical applications. In this paper, we introduce four techniques to balance the trade-off between the complexity and performance. We are the first to introduce deformable convolutional module in compression framework, which can remove more redundancies in the input image, thereby enhancing compression performance. Second, we design a checkerboard context model with two separate distribution parameter estimation networks and different probability models, which enables parallel decoding without sacrificing the performance compared to the sequential context-adaptive model. Third, we develop an improved three-step knowledge distillation and training scheme to achieve different trade-offs between the complexity and the performance of the decoder network, which transfers both the final and intermediate results of the teacher network to the student network to help its training. Fourth, we introduce $L_{1}$ regularization to make the numerical values of the latent representation more sparse. Then we only encode non-zero channels in the encoding and decoding process, which can greatly reduce the encoding and decoding time. Experiments show that compared to the state-of-the-art learned image coding scheme, our method can be about 20 times faster in encoding and 70-90 times faster in decoding, and our R-D performance is also $2.3 \%$ higher. Our method outperforms the traditional approach in H.266/VVC-intra (4:4:4) and some leading learned schemes in terms of PSNR and MS-SSIM metrics when testing on Kodak and Tecnick-40 datasets.
Enhanced Residual SwinV2 Transformer for Learned Image Compression
Aug 23, 2023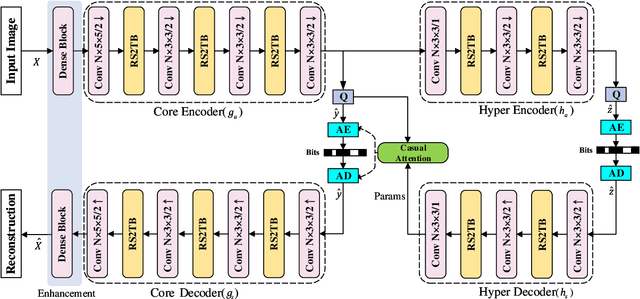
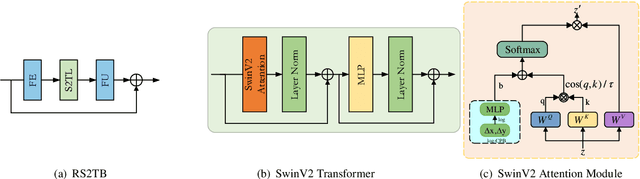

Recently, the deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. However, a challenge of many learning-based approaches is that they often achieve better performance via sacrificing complexity, which making practical deployment difficult. To alleviate this issue, in this paper, we propose an effective and efficient learned image compression framework based on an enhanced residual Swinv2 transformer. To enhance the nonlinear representation of images in our framework, we use a feature enhancement module that consists of three consecutive convolutional layers. In the subsequent coding and hyper coding steps, we utilize a SwinV2 transformer-based attention mechanism to process the input image. The SwinV2 model can help to reduce model complexity while maintaining high performance. Experimental results show that the proposed method achieves comparable performance compared to some recent learned image compression methods on Kodak and Tecnick datasets, and outperforms some traditional codecs including VVC. In particular, our method achieves comparable results while reducing model complexity by 56% compared to these recent methods.
ROI-based Deep Image Compression with Swin Transformers
May 12, 2023Encoding the Region Of Interest (ROI) with better quality than the background has many applications including video conferencing systems, video surveillance and object-oriented vision tasks. In this paper, we propose a ROI-based image compression framework with Swin transformers as main building blocks for the autoencoder network. The binary ROI mask is integrated into different layers of the network to provide spatial information guidance. Based on the ROI mask, we can control the relative importance of the ROI and non-ROI by modifying the corresponding Lagrange multiplier $ \lambda $ for different regions. Experimental results show our model achieves higher ROI PSNR than other methods and modest average PSNR for human evaluation. When tested on models pre-trained with original images, it has superior object detection and instance segmentation performance on the COCO validation dataset.
Learned Image Compression with Generalized Octave Convolution and Cross-Resolution Parameter Estimation
Sep 07, 2022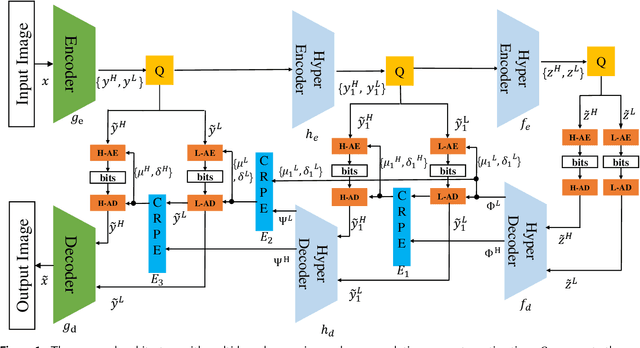

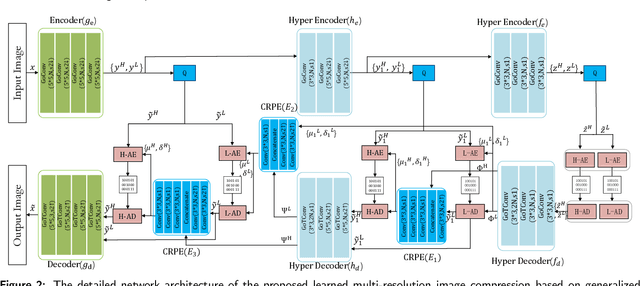
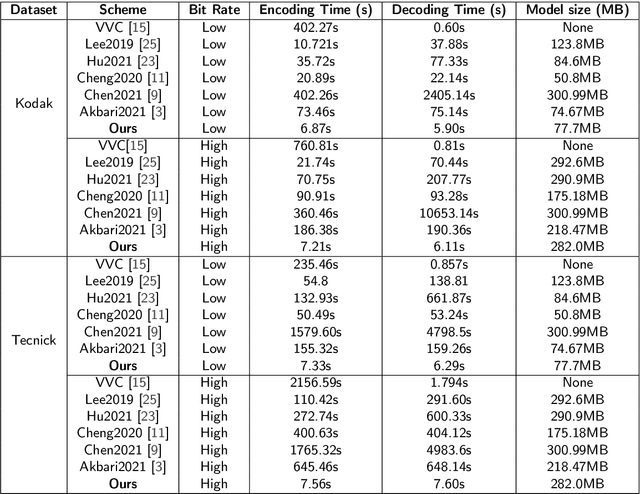
The application of the context-adaptive entropy model significantly improves the rate-distortion (R-D) performance, in which hyperpriors and autoregressive models are jointly utilized to effectively capture the spatial redundancy of the latent representations. However, the latent representations still contain some spatial correlations. In addition, these methods based on the context-adaptive entropy model cannot be accelerated in the decoding process by parallel computing devices, e.g. FPGA or GPU. To alleviate these limitations, we propose a learned multi-resolution image compression framework, which exploits the recently developed octave convolutions to factorize the latent representations into the high-resolution (HR) and low-resolution (LR) parts, similar to wavelet transform, which further improves the R-D performance. To speed up the decoding, our scheme does not use context-adaptive entropy model. Instead, we exploit an additional hyper layer including hyper encoder and hyper decoder to further remove the spatial redundancy of the latent representation. Moreover, the cross-resolution parameter estimation (CRPE) is introduced into the proposed framework to enhance the flow of information and further improve the rate-distortion performance. An additional information-fidelity loss is proposed to the total loss function to adjust the contribution of the LR part to the final bit stream. Experimental results show that our method separately reduces the decoding time by approximately 73.35 % and 93.44 % compared with that of state-of-the-art learned image compression methods, and the R-D performance is still better than H.266/VVC(4:2:0) and some learning-based methods on both PSNR and MS-SSIM metrics across a wide bit rates.
Asymmetric Learned Image Compression with Multi-Scale Residual Block, Importance Map, and Post-Quantization Filtering
Jun 21, 2022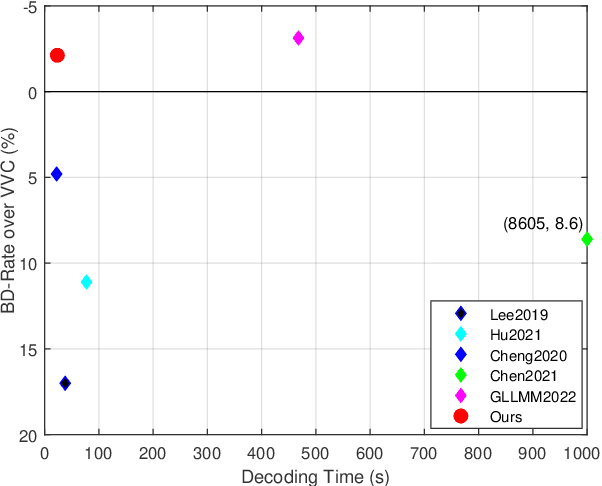



Recently, deep learning-based image compression has made signifcant progresses, and has achieved better ratedistortion (R-D) performance than the latest traditional method, H.266/VVC, in both subjective metric and the more challenging objective metric. However, a major problem is that many leading learned schemes cannot maintain a good trade-off between performance and complexity. In this paper, we propose an effcient and effective image coding framework, which achieves similar R-D performance with lower complexity than the state of the art. First, we develop an improved multi-scale residual block (MSRB) that can expand the receptive feld and is easier to obtain global information. It can further capture and reduce the spatial correlation of the latent representations. Second, a more advanced importance map network is introduced to adaptively allocate bits to different regions of the image. Third, we apply a 2D post-quantization flter (PQF) to reduce the quantization error, motivated by the Sample Adaptive Offset (SAO) flter in video coding. Moreover, We fnd that the complexity of encoder and decoder have different effects on image compression performance. Based on this observation, we design an asymmetric paradigm, in which the encoder employs three stages of MSRBs to improve the learning capacity, whereas the decoder only needs one stage of MSRB to yield satisfactory reconstruction, thereby reducing the decoding complexity without sacrifcing performance. Experimental results show that compared to the state-of-the-art method, the encoding and decoding time of the proposed method are about 17 times faster, and the R-D performance is only reduced by less than 1% on both Kodak and Tecnick datasets, which is still better than H.266/VVC(4:4:4) and other recent learning-based methods. Our source code is publicly available at https://github.com/fengyurenpingsheng.