 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Image Compression with Generalized Octave Convolution and Cross-Resolution Parameter Estimation
Paper and Code
Sep 07, 2022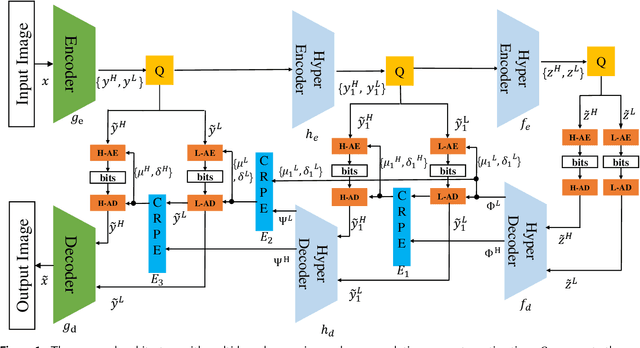

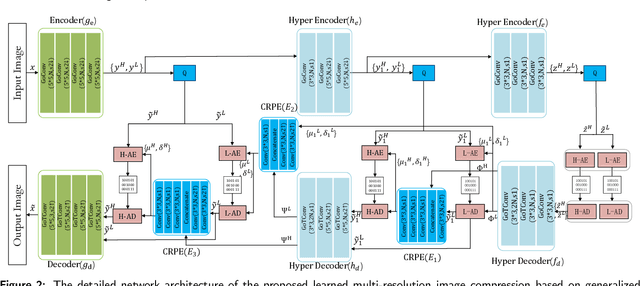
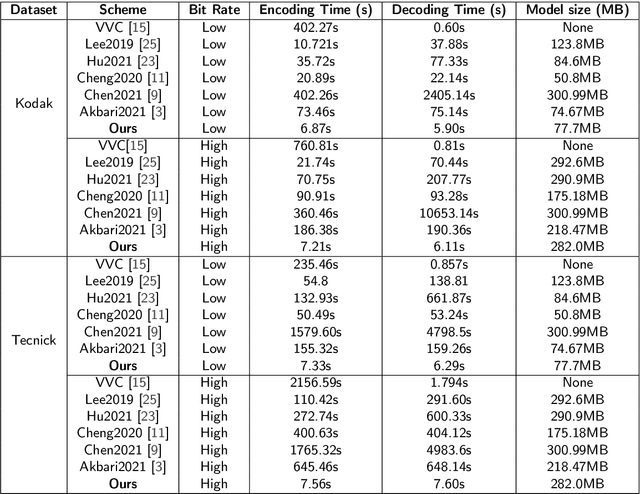
The application of the context-adaptive entropy model significantly improves the rate-distortion (R-D) performance, in which hyperpriors and autoregressive models are jointly utilized to effectively capture the spatial redundancy of the latent representations. However, the latent representations still contain some spatial correlations. In addition, these methods based on the context-adaptive entropy model cannot be accelerated in the decoding process by parallel computing devices, e.g. FPGA or GPU. To alleviate these limitations, we propose a learned multi-resolution image compression framework, which exploits the recently developed octave convolutions to factorize the latent representations into the high-resolution (HR) and low-resolution (LR) parts, similar to wavelet transform, which further improves the R-D performance. To speed up the decoding, our scheme does not use context-adaptive entropy model. Instead, we exploit an additional hyper layer including hyper encoder and hyper decoder to further remove the spatial redundancy of the latent representation. Moreover, the cross-resolution parameter estimation (CRPE) is introduced into the proposed framework to enhance the flow of information and further improve the rate-distortion performance. An additional information-fidelity loss is proposed to the total loss function to adjust the contribution of the LR part to the final bit stream. Experimental results show that our method separately reduces the decoding time by approximately 73.35 % and 93.44 % compared with that of state-of-the-art learned image compression methods, and the R-D performance is still better than H.266/VVC(4:2:0) and some learning-based methods on both PSNR and MS-SSIM metrics across a wide bit rates.