 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and High-Performance Learned Image Compression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation
Paper and Code
Sep 05, 2023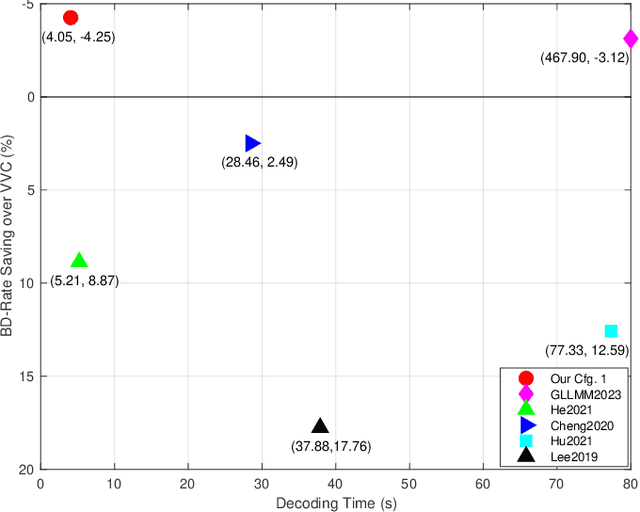



Deep learning-based image compression has made great progresses recently. However, many leading schemes use serial context-adaptive entropy model to improve the rate-distortion (R-D) performance, which is very slow. In addition, the complexities of the encoding and decoding networks are quite high and not suitable for many practical applications. In this paper, we introduce four techniques to balance the trade-off between the complexity and performance. We are the first to introduce deformable convolutional module in compression framework, which can remove more redundancies in the input image, thereby enhancing compression performance. Second, we design a checkerboard context model with two separate distribution parameter estimation networks and different probability models, which enables parallel decoding without sacrificing the performance compared to the sequential context-adaptive model. Third, we develop an improved three-step knowledge distillation and training scheme to achieve different trade-offs between the complexity and the performance of the decoder network, which transfers both the final and intermediate results of the teacher network to the student network to help its training. Fourth, we introduce $L_{1}$ regularization to make the numerical values of the latent representation more sparse. Then we only encode non-zero channels in the encoding and decoding process, which can greatly reduce the encoding and decoding time. Experiments show that compared to the state-of-the-art learned image coding scheme, our method can be about 20 times faster in encoding and 70-90 times faster in decoding, and our R-D performance is also $2.3 \%$ higher. Our method outperforms the traditional approach in H.266/VVC-intra (4:4:4) and some leading learned schemes in terms of PSNR and MS-SSIM metrics when testing on Kodak and Tecnick-40 datasets.