 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Optimal Energy Shaping Control for a Backdrivable Hip Exoskeleton
Oct 07, 2022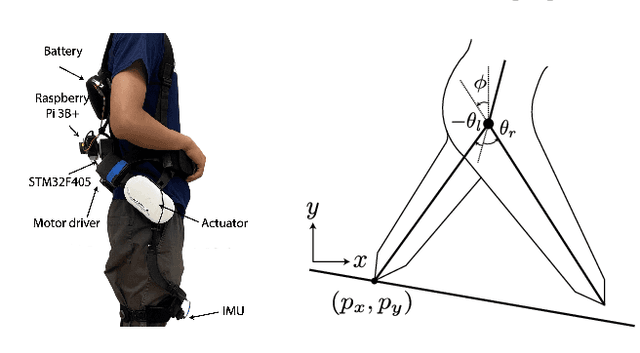

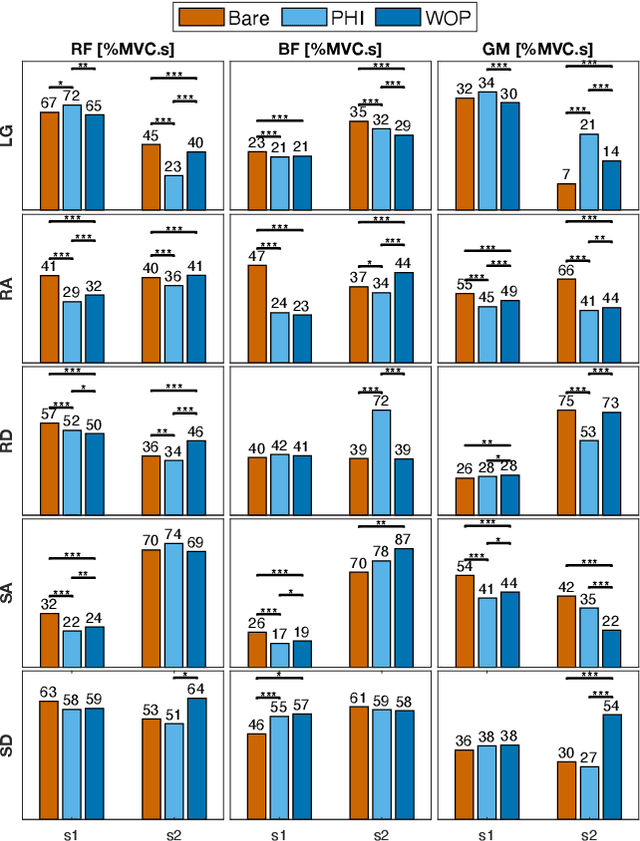

Task-dependent controllers widely used in exoskeletons track predefined trajectories, which overly constrain the volitional motion of individuals with remnant voluntary mobility. Energy shaping, on the other hand, provides task-invariant assistance by altering the human body's dynamic characteristics in the closed loop. While human-exoskeleton systems are often modeled using Euler-Lagrange equations, in our previous work we modeled the system as a port-controlled-Hamiltonian system, and a task-invariant controller was designed for a knee-ankle exoskeleton using interconnection-damping assignment passivity-based control. In this paper, we extend this framework to design a controller for a backdrivable hip exoskeleton to assist multiple tasks. A set of basis functions that contains information of kinematics is selected and corresponding coefficients are optimized, which allows the controller to provide torque that fits normative human torque for different activities of daily life. Human-subject experiments with two able-bodied subjects demonstrated the controller's capability to reduce muscle effort across different tasks.
Learned Image Compression with Discretized Gaussian-Laplacian-Logistic Mixture Model and Concatenated Residual Modules
Jul 18, 2021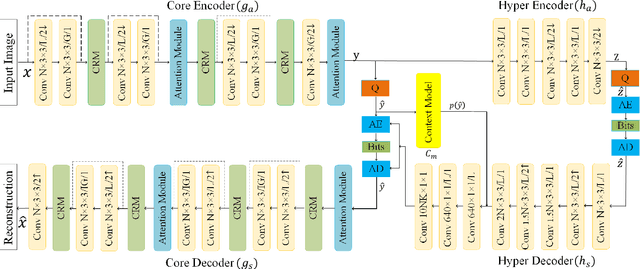
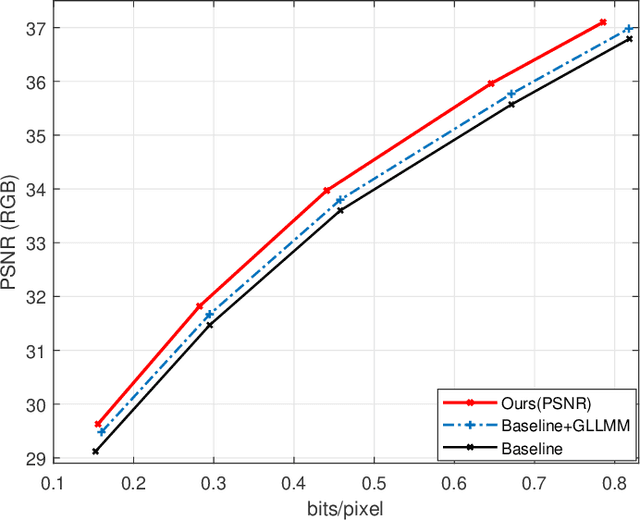
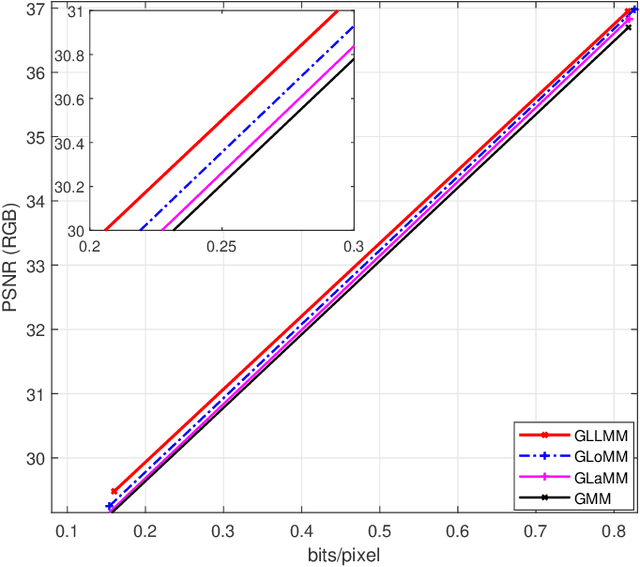
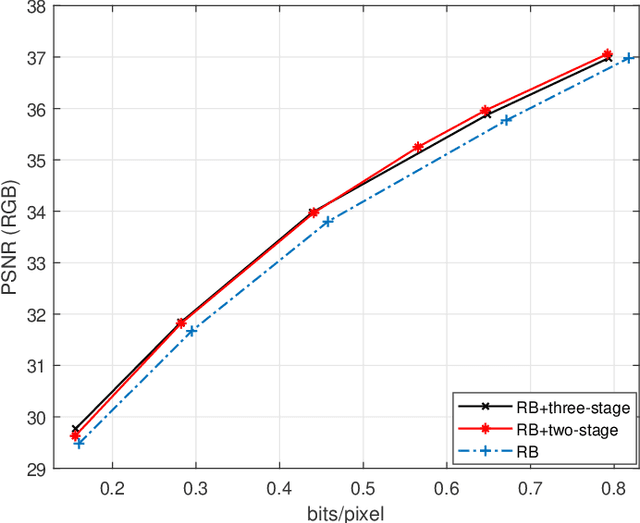
Recently deep learning-based image compression methods have achieved significant achievements and gradually outperformed traditional approaches including the latest standard Versatile Video Coding (VVC) in both PSNR and MS-SSIM metrics. Two key components of learned image compression frameworks are the entropy model of the latent representations and the encoding/decoding network architectures. Various models have been proposed, such as autoregressive, softmax, logistic mixture, Gaussian mixture, and Laplacian. Existing schemes only use one of these models. However, due to the vast diversity of images, it is not optimal to use one model for all images, even different regions of one image. In this paper, we propose a more flexible discretized Gaussian-Laplacian-Logistic mixture model (GLLMM) for the latent representations, which can adapt to different contents in different images and different regions of one image more accurately. Besides, in the encoding/decoding network design part, we propose a concatenated residual blocks (CRB), where multiple residual blocks are serially connected with additional shortcut connections. The CRB can improve the learning ability of the network, which can further improve the compression performance. Experimental results using the Kodak and Tecnick datasets show that the proposed scheme outperforms all the state-of-the-art learning-based methods and existing compression standards including VVC intra coding (4:4:4 and 4:2:0) in terms of the PSNR and MS-SSIM. The project page is at \url{https://github.com/fengyurenpingsheng/Learned-image-compression-with-GLLMM}
M-LVC: Multiple Frames Prediction for Learned Video Compression
Apr 21, 2020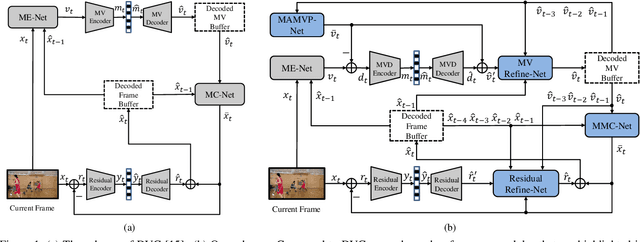

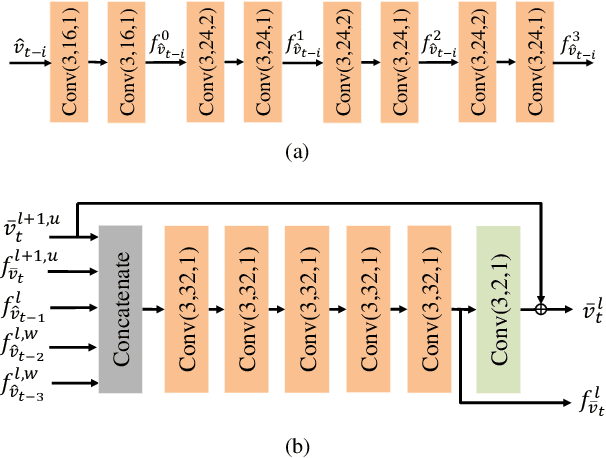

We propose an end-to-end learned video compression scheme for low-latency scenarios. Previous methods are limited in using the previous one frame as reference. Our method introduces the usage of the previous multiple frames as references. In our scheme, the motion vector (MV) field is calculated between the current frame and the previous one. With multiple reference frames and associated multiple MV fields, our designed network can generate more accurate prediction of the current frame, yielding less residual. Multiple reference frames also help generate MV prediction, which reduces the coding cost of MV field. We use two deep auto-encoders to compress the residual and the MV, respectively. To compensate for the compression error of the auto-encoders, we further design a MV refinement network and a residual refinement network, taking use of the multiple reference frames as well. All the modules in our scheme are jointly optimized through a single rate-distortion loss function. We use a step-by-step training strategy to optimize the entire scheme. Experimental results show that the proposed method outperforms the existing learned video compression methods for low-latency mode. Our method also performs better than H.265 in both PSNR and MS-SSIM. Our code and models are publicly available.