 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Image Compression with Discretized Gaussian-Laplacian-Logistic Mixture Model and Concatenated Residual Modules
Jul 18, 2021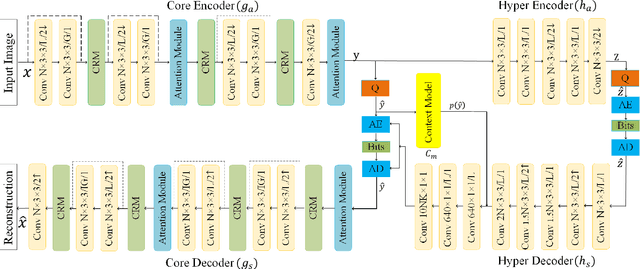
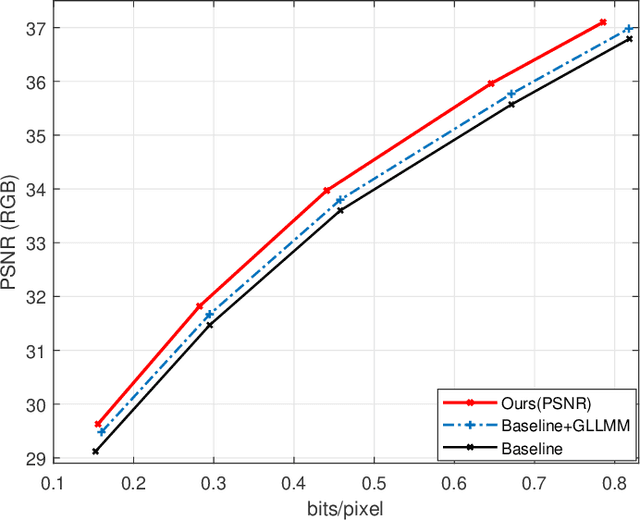
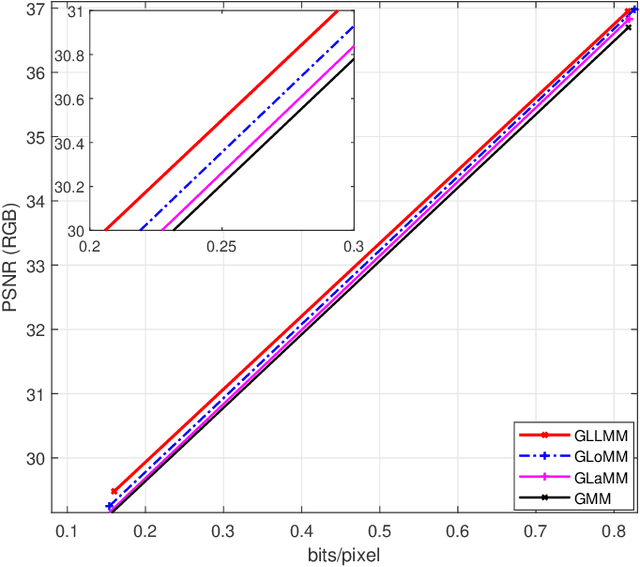
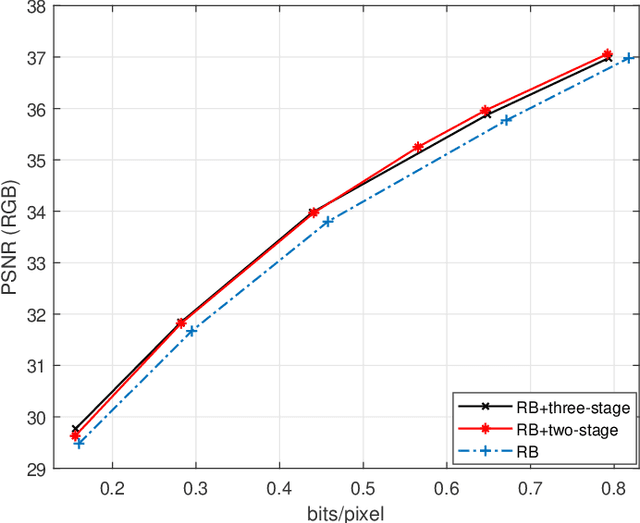
Recently deep learning-based image compression methods have achieved significant achievements and gradually outperformed traditional approaches including the latest standard Versatile Video Coding (VVC) in both PSNR and MS-SSIM metrics. Two key components of learned image compression frameworks are the entropy model of the latent representations and the encoding/decoding network architectures. Various models have been proposed, such as autoregressive, softmax, logistic mixture, Gaussian mixture, and Laplacian. Existing schemes only use one of these models. However, due to the vast diversity of images, it is not optimal to use one model for all images, even different regions of one image. In this paper, we propose a more flexible discretized Gaussian-Laplacian-Logistic mixture model (GLLMM) for the latent representations, which can adapt to different contents in different images and different regions of one image more accurately. Besides, in the encoding/decoding network design part, we propose a concatenated residual blocks (CRB), where multiple residual blocks are serially connected with additional shortcut connections. The CRB can improve the learning ability of the network, which can further improve the compression performance. Experimental results using the Kodak and Tecnick datasets show that the proposed scheme outperforms all the state-of-the-art learning-based methods and existing compression standards including VVC intra coding (4:4:4 and 4:2:0) in terms of the PSNR and MS-SSIM. The project page is at \url{https://github.com/fengyurenpingsheng/Learned-image-compression-with-GLLMM}
Learned Multi-Resolution Variable-Rate Image Compression with Octave-based Residual Blocks
Dec 31, 2020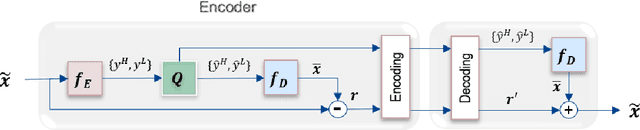
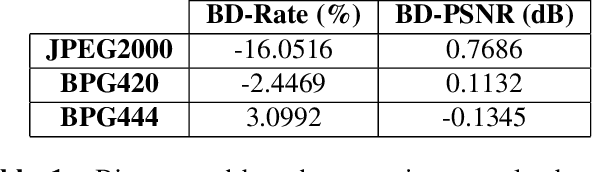
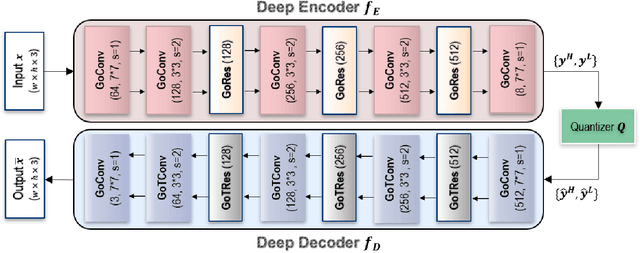
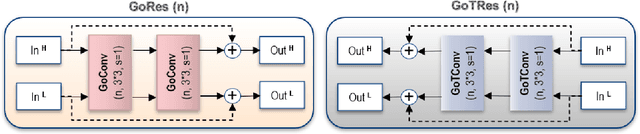
Recently deep learning-based image compression has shown the potential to outperform traditional codecs. However, most existing methods train multiple networks for multiple bit rates, which increase the implementation complexity. In this paper, we propose a new variable-rate image compression framework, which employs generalized octave convolutions (GoConv) and generalized octave transposed-convolutions (GoTConv) with built-in generalized divisive normalization (GDN) and inverse GDN (IGDN) layers. Novel GoConv- and GoTConv-based residual blocks are also developed in the encoder and decoder networks. Our scheme also uses a stochastic rounding-based scalar quantization. To further improve the performance, we encode the residual between the input and the reconstructed image from the decoder network as an enhancement layer. To enable a single model to operate with different bit rates and to learn multi-rate image features, a new objective function is introduced. Experimental results show that the proposed framework trained with variable-rate objective function outperforms the standard codecs such as H.265/HEVC-based BPG and state-of-the-art learning-based variable-rate methods.
Generalized Octave Convolutions for Learned Multi-Frequency Image Compression
Feb 24, 2020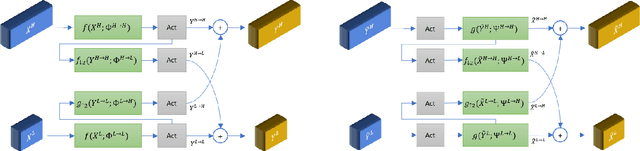

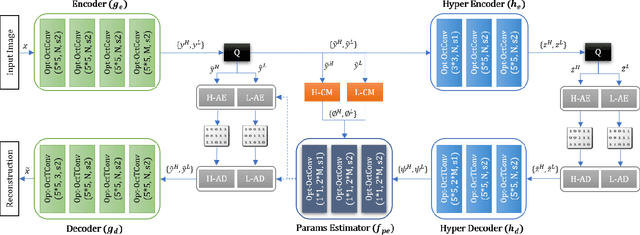
Learned image compression has recently shown the potential to outperform all standard codecs. The state-of-the-art rate-distortion performance has been achieved by context-adaptive entropy approaches in which hyperprior and autoregressive models are jointly utilized to effectively capture the spatial dependencies in the latent representations. However, the latents contain a mixture of high and low frequency information, which has inefficiently been represented by features maps of the same spatial resolution in previous works. In this paper, we propose the first learned multi-frequency image compression approach that uses the recently developed octave convolutions to factorize the latents into high and low frequencies. Since the low frequency is represented by a lower resolution, their spatial redundancy is reduced, which improves the compression rate. Moreover, octave convolutions impose effective high and low frequency communication, which can improve the reconstruction quality. We also develop novel generalized octave convolution and octave transposed-convolution architectures with internal activation layers to preserve the spatial structure of the information. Our experiments show that the proposed scheme outperforms all standard codecs and learning-based methods in both PSNR and MS-SSIM metrics, and establishes the new state of the art for learned image compression.
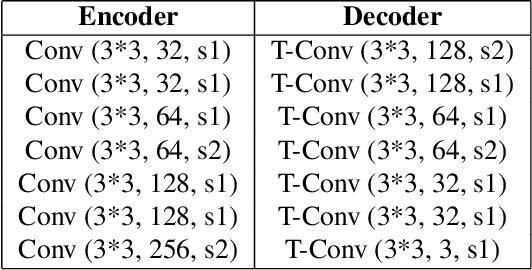
Learned Variable-Rate Image Compression with Residual Divisive Normalization
Dec 11, 2019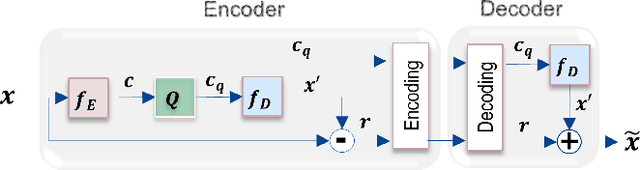
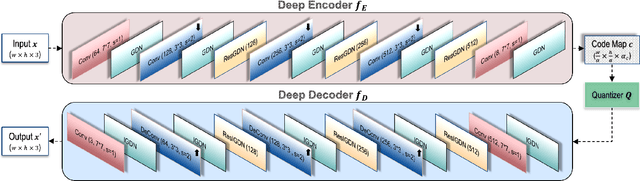
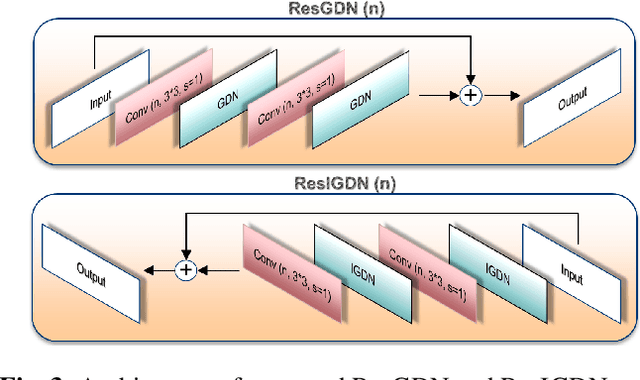
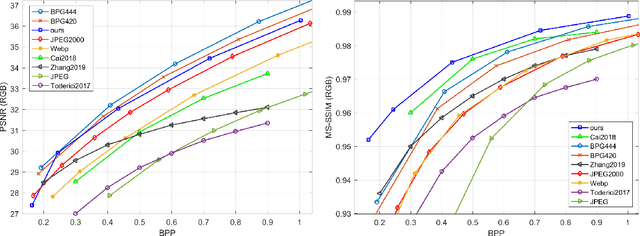
Recently it has been shown that deep learning-based image compression has shown the potential to outperform traditional codecs. However, most existing methods train multiple networks for multiple bit rates, which increases the implementation complexity. In this paper, we propose a variable-rate image compression framework, which employs more Generalized Divisive Normalization (GDN) layers than previous GDN-based methods. Novel GDN-based residual sub-networks are also developed in the encoder and decoder networks. Our scheme also uses a stochastic rounding-based scalable quantization. To further improve the performance, we encode the residual between the input and the reconstructed image from the decoder network as an enhancement layer. To enable a single model to operate with different bit rates and to learn multi-rate image features, a new objective function is introduced. Experimental results show that the proposed framework trained with variable-rate objective function outperforms all standard codecs such as H.265/HEVC-based BPG and state-of-the-art learning-based variable-rate methods.
Improved Hybrid Layered Image Compression using Deep Learning and Traditional Codecs
Jul 15, 2019
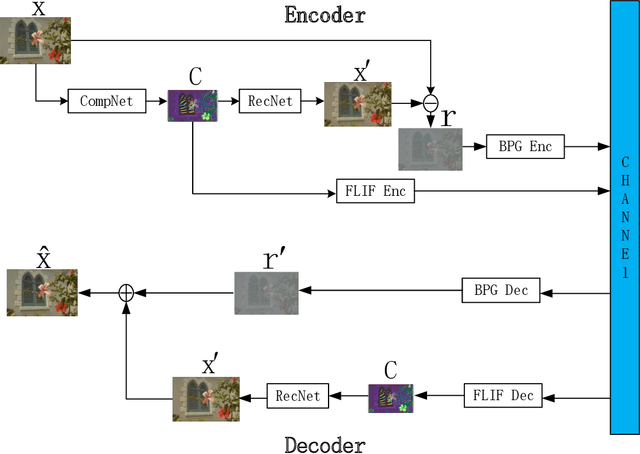
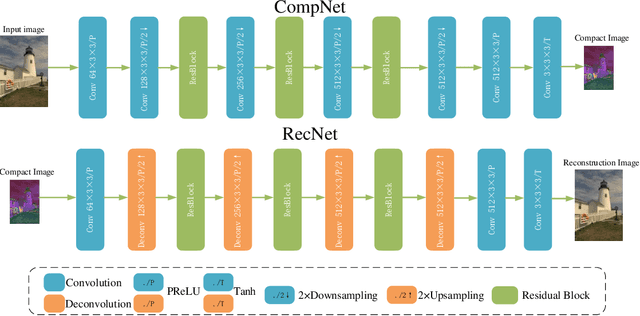
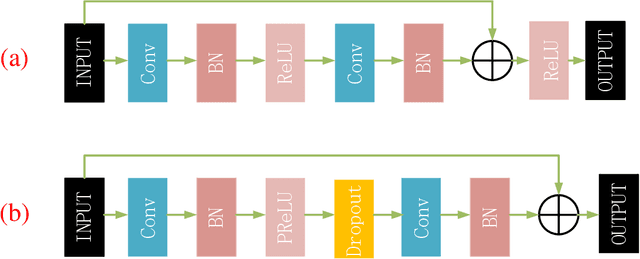
Recently deep learning-based methods have been applied in image compression and achieved many promising results. In this paper, we propose an improved hybrid layered image compression framework by combining deep learning and the traditional image codecs. At the encoder, we first use a convolutional neural network (CNN) to obtain a compact representation of the input image, which is losslessly encoded by the FLIF codec as the base layer of the bit stream. A coarse reconstruction of the input is obtained by another CNN from the reconstructed compact representation. The residual between the input and the coarse reconstruction is then obtained and encoded by the H.265/HEVC-based BPG codec as the enhancement layer of the bit stream. Experimental results using the Kodak and Tecnick datasets show that the proposed scheme outperforms the state-of-the-art deep learning-based layered coding scheme and traditional codecs including BPG in both PSNR and MS-SSIM metrics across a wide range of bit rates, when the images are coded in the RGB444 domain.