 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Residual SwinV2 Transformer for Learned Image Compression
Paper and Code
Aug 23, 2023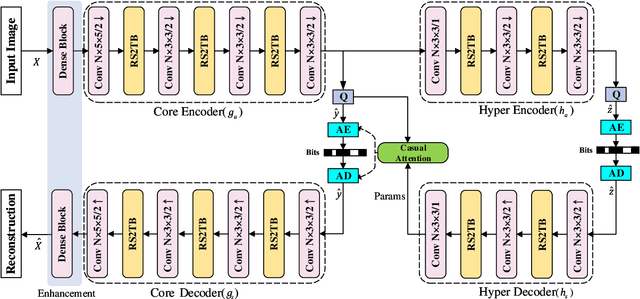
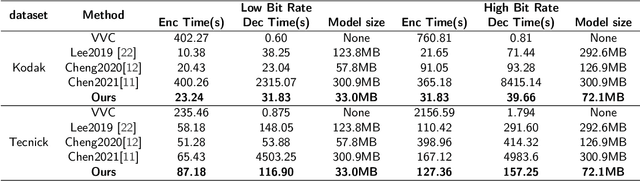
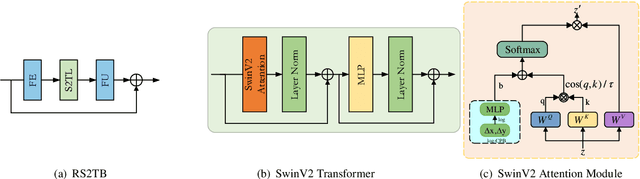

Recently, the deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. However, a challenge of many learning-based approaches is that they often achieve better performance via sacrificing complexity, which making practical deployment difficult. To alleviate this issue, in this paper, we propose an effective and efficient learned image compression framework based on an enhanced residual Swinv2 transformer. To enhance the nonlinear representation of images in our framework, we use a feature enhancement module that consists of three consecutive convolutional layers. In the subsequent coding and hyper coding steps, we utilize a SwinV2 transformer-based attention mechanism to process the input image. The SwinV2 model can help to reduce model complexity while maintaining high performance. Experimental results show that the proposed method achieves comparable performance compared to some recent learned image compression methods on Kodak and Tecnick datasets, and outperforms some traditional codecs including VVC. In particular, our method achieves comparable results while reducing model complexity by 56% compared to these recent methods.