 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECVL-ROUTER: Scenario-Aware Routing for Vision-Language Models
Oct 31, 2025Vision-Language Models (VLMs) excel in diverse multimodal tasks. However, user requirements vary across scenarios, which can be categorized into fast response, high-quality output, and low energy consumption. Relying solely on large models deployed in the cloud for all queries often leads to high latency and energy cost, while small models deployed on edge devices are capable of handling simpler tasks with low latency and energy cost. To fully leverage the strengths of both large and small models, we propose ECVL-ROUTER, the first scenario-aware routing framework for VLMs. Our approach introduces a new routing strategy and evaluation metrics that dynamically select the appropriate model for each query based on user requirements, maximizing overall utility. We also construct a multimodal response-quality dataset tailored for router training and validate the approach through extensive experiments. Results show that our approach successfully routes over 80\% of queries to the small model while incurring less than 10\% drop in problem solving probability.
Enabling Flexible Multi-LLM Integration for Scalable Knowledge Aggregation
May 28, 2025



Large language models (LLMs) have shown remarkable promise but remain challenging to continually improve through traditional finetuning, particularly when integrating capabilities from other specialized LLMs. Popular methods like ensemble and weight merging require substantial memory and struggle to adapt to changing data environments. Recent efforts have transferred knowledge from multiple LLMs into a single target model; however, they suffer from interference and degraded performance among tasks, largely due to limited flexibility in candidate selection and training pipelines. To address these issues, we propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. Specifically, we design an adaptive selection network that identifies the most relevant source LLMs based on their scores, thereby reducing knowledge interference. We further propose a dynamic weighted fusion strategy that accounts for the inherent strengths of candidate LLMs, along with a feedback-driven loss function that prevents the selector from converging on a single subset of sources. Experimental results demonstrate that our method can enable a more stable and scalable knowledge aggregation process while reducing knowledge interference by up to 50% compared to existing approaches. Code is avaliable at https://github.com/ZLKong/LLM_Integration
Cross-organ all-in-one parallel compressed sensing magnetic resonance imaging
May 07, 2025Recent advances in deep learning-based parallel compressed sensing magnetic resonance imaging (p-CSMRI) have significantly improved reconstruction quality. However, current p-CSMRI methods often require training separate deep neural network (DNN) for each organ due to anatomical variations, creating a barrier to developing generalized medical image reconstruction systems. To address this, we propose CAPNet (cross-organ all-in-one deep unfolding p-CSMRI network), a unified framework that implements a p-CSMRI iterative algorithm via three specialized modules: auxiliary variable module, prior module, and data consistency module. Recognizing that p-CSMRI systems often employ varying sampling ratios for different organs, resulting in organ-specific artifact patterns, we introduce an artifact generation submodule, which extracts and integrates artifact features into the data consistency module to enhance the discriminative capability of the overall network. For the prior module, we design an organ structure-prompt generation submodule that leverages structural features extracted from the segment anything model (SAM) to create cross-organ prompts. These prompts are strategically incorporated into the prior module through an organ structure-aware Mamba submodule. Comprehensive evaluations on a cross-organ dataset confirm that CAPNet achieves state-of-the-art reconstruction performance across multiple anatomical structures using a single unified model. Our code will be published at https://github.com/shibaoshun/CAPNet.
GRN+: A Simplified Generative Reinforcement Network for Tissue Layer Analysis in 3D Ultrasound Images for Chronic Low-back Pain
Mar 25, 20253D ultrasound delivers high-resolution, real-time images of soft tissues, which is essential for pain research. However, manually distinguishing various tissues for quantitative analysis is labor-intensive. To streamline this process, we developed and validated GRN+, a novel multi-model framework that automates layer segmentation with minimal annotated data. GRN+ combines a ResNet-based generator and a U-Net segmentation model. Through a method called Segmentation-guided Enhancement (SGE), the generator produces new images and matching masks under the guidance of the segmentation model, with its weights adjusted according to the segmentation loss gradient. To prevent gradient explosion and secure stable training, a two-stage backpropagation strategy was implemented: the first stage propagates the segmentation loss through both the generator and segmentation model, while the second stage concentrates on optimizing the segmentation model alone, thereby refining mask prediction using the generated images. Tested on 69 fully annotated 3D ultrasound scans from 29 subjects with six manually labeled tissue layers, GRN+ outperformed all other semi-supervised methods in terms of the Dice coefficient using only 5% labeled data, despite not using unlabeled data for unsupervised training. Additionally, when applied to fully annotated datasets, GRN+ with SGE achieved a 2.16% higher Dice coefficient while incurring lower computational costs compared to other models. Overall, GRN+ provides accurate tissue segmentation while reducing both computational expenses and the dependency on extensive annotations, making it an effective tool for 3D ultrasound analysis in cLBP patients.
InterSliceBoost: Identifying Tissue Layers in Three-dimensional Ultrasound Images for Chronic Lower Back Pain (cLBP) Assessment
Mar 25, 2025Available studies on chronic lower back pain (cLBP) typically focus on one or a few specific tissues rather than conducting a comprehensive layer-by-layer analysis. Since three-dimensional (3-D) images often contain hundreds of slices, manual annotation of these anatomical structures is both time-consuming and error-prone. We aim to develop and validate a novel approach called InterSliceBoost to enable the training of a segmentation model on a partially annotated dataset without compromising segmentation performance. The architecture of InterSliceBoost includes two components: an inter-slice generator and a segmentation model. The generator utilizes residual block-based encoders to extract features from adjacent image-mask pairs (IMPs). Differential features are calculated and input into a decoder to generate inter-slice IMPs. The segmentation model is trained on partially annotated datasets (e.g., skipping 1, 2, 3, or 7 images) and the generated inter-slice IMPs. To validate the performance of InterSliceBoost, we utilized a dataset of 76 B-mode ultrasound scans acquired on 29 subjects enrolled in an ongoing cLBP study. InterSliceBoost, trained on only 33% of the image slices, achieved a mean Dice coefficient of 80.84% across all six layers on the independent test set, with Dice coefficients of 73.48%, 61.11%, 81.87%, 95.74%, 83.52% and 88.74% for segmenting dermis, superficial fat, superficial fascial membrane, deep fat, deep fascial membrane, and muscle. This performance is significantly higher than the conventional model trained on fully annotated images (p<0.05). InterSliceBoost can effectively segment the six tissue layers depicted on 3-D B-model ultrasound images in settings with partial annotations.
Safe-VAR: Safe Visual Autoregressive Model for Text-to-Image Generative Watermarking
Mar 14, 2025With the success of autoregressive learning in large language models, it has become a dominant approach for text-to-image generation, offering high efficiency and visual quality. However, invisible watermarking for visual autoregressive (VAR) models remains underexplored, despite its importance in misuse prevention. Existing watermarking methods, designed for diffusion models, often struggle to adapt to the sequential nature of VAR models. To bridge this gap, we propose Safe-VAR, the first watermarking framework specifically designed for autoregressive text-to-image generation. Our study reveals that the timing of watermark injection significantly impacts generation quality, and watermarks of different complexities exhibit varying optimal injection times. Motivated by this observation, we propose an Adaptive Scale Interaction Module, which dynamically determines the optimal watermark embedding strategy based on the watermark information and the visual characteristics of the generated image. This ensures watermark robustness while minimizing its impact on image quality. Furthermore, we introduce a Cross-Scale Fusion mechanism, which integrates mixture of both heads and experts to effectively fuse multi-resolution features and handle complex interactions between image content and watermark patterns. Experimental results demonstrate that Safe-VAR achieves state-of-the-art performance, significantly surpassing existing counterparts regarding image quality, watermarking fidelity, and robustness against perturbations. Moreover, our method exhibits strong generalization to an out-of-domain watermark dataset QR Codes.
Enhanced Probabilistic Collision Detection for Motion Planning Under Sensing Uncertainty
Feb 21, 2025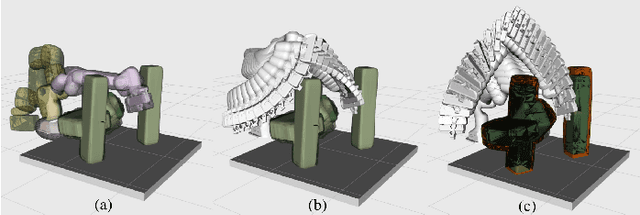
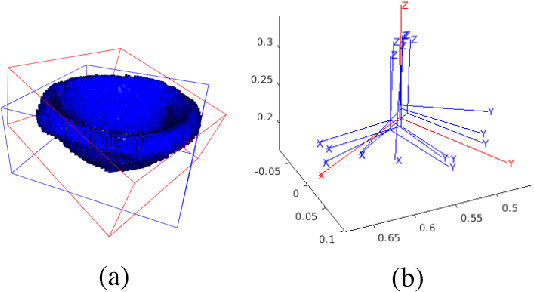
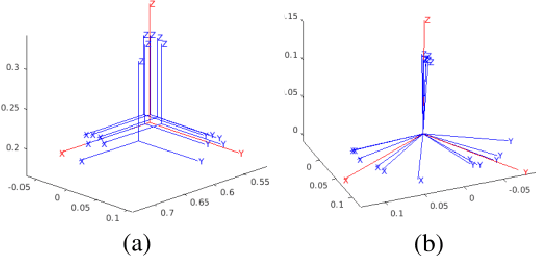

Probabilistic collision detection (PCD) is essential in motion planning for robots operating in unstructured environments, where considering sensing uncertainty helps prevent damage. Existing PCD methods mainly used simplified geometric models and addressed only position estimation errors. This paper presents an enhanced PCD method with two key advancements: (a) using superquadrics for more accurate shape approximation and (b) accounting for both position and orientation estimation errors to improve robustness under sensing uncertainty. Our method first computes an enlarged surface for each object that encapsulates its observed rotated copies, thereby addressing the orientation estimation errors. Then, the collision probability under the position estimation errors is formulated as a chance-constraint problem that is solved with a tight upper bound. Both the two steps leverage the recently developed normal parameterization of superquadric surfaces. Results show that our PCD method is twice as close to the Monte-Carlo sampled baseline as the best existing PCD method and reduces path length by 30% and planning time by 37%, respectively. A Real2Sim pipeline further validates the importance of considering orientation estimation errors, showing that the collision probability of executing the planned path in simulation is only 2%, compared to 9% and 29% when considering only position estimation errors or none at all.
Segmentation-Aware Generative Reinforcement Network (GRN) for Tissue Layer Segmentation in 3-D Ultrasound Images for Chronic Low-back Pain (cLBP) Assessment
Jan 29, 2025We introduce a novel segmentation-aware joint training framework called generative reinforcement network (GRN) that integrates segmentation loss feedback to optimize both image generation and segmentation performance in a single stage. An image enhancement technique called segmentation-guided enhancement (SGE) is also developed, where the generator produces images tailored specifically for the segmentation model. Two variants of GRN were also developed, including GRN for sample-efficient learning (GRN-SEL) and GRN for semi-supervised learning (GRN-SSL). GRN's performance was evaluated using a dataset of 69 fully annotated 3D ultrasound scans from 29 subjects. The annotations included six anatomical structures: dermis, superficial fat, superficial fascial membrane (SFM), deep fat, deep fascial membrane (DFM), and muscle. Our results show that GRN-SEL with SGE reduces labeling efforts by up to 70% while achieving a 1.98% improvement in the Dice Similarity Coefficient (DSC) compared to models trained on fully labeled datasets. GRN-SEL alone reduces labeling efforts by 60%, GRN-SSL with SGE decreases labeling requirements by 70%, and GRN-SSL alone by 60%, all while maintaining performance comparable to fully supervised models. These findings suggest the effectiveness of the GRN framework in optimizing segmentation performance with significantly less labeled data, offering a scalable and efficient solution for ultrasound image analysis and reducing the burdens associated with data annotation.
EventGPT: Event Stream Understanding with Multimodal Large Language Models
Dec 01, 2024



Event cameras record visual information as asynchronous pixel change streams, excelling at scene perception under unsatisfactory lighting or high-dynamic conditions. Existing multimodal large language models (MLLMs) concentrate on natural RGB images, failing in scenarios where event data fits better. In this paper, we introduce EventGPT, the first MLLM for event stream understanding, to the best of our knowledge, marking a pioneering attempt to integrate large language models (LLMs) with event stream comprehension. To mitigate the huge domain gaps, we develop a three-stage optimization paradigm to gradually equip a pre-trained LLM with the capability of understanding event-based scenes. Our EventGPT comprises an event encoder, followed by a spatio-temporal aggregator, a linear projector, an event-language adapter, and an LLM. Firstly, RGB image-text pairs generated by GPT are leveraged to warm up the linear projector, referring to LLaVA, as the gap between natural image and language modalities is relatively smaller. Secondly, we construct a synthetic yet large dataset, N-ImageNet-Chat, consisting of event frames and corresponding texts to enable the use of the spatio-temporal aggregator and to train the event-language adapter, thereby aligning event features more closely with the language space. Finally, we gather an instruction dataset, Event-Chat, which contains extensive real-world data to fine-tune the entire model, further enhancing its generalization ability. We construct a comprehensive benchmark, and experiments show that EventGPT surpasses previous state-of-the-art MLLMs in generation quality, descriptive accuracy, and reasoning capability.
RAIL: Robot Affordance Imagination with Large Language Models
Mar 28, 2024This paper introduces an automatic affordance reasoning paradigm tailored to minimal semantic inputs, addressing the critical challenges of classifying and manipulating unseen classes of objects in household settings. Inspired by human cognitive processes, our method integrates generative language models and physics-based simulators to foster analytical thinking and creative imagination of novel affordances. Structured with a tripartite framework consisting of analysis, imagination, and evaluation, our system "analyzes" the requested affordance names into interaction-based definitions, "imagines" the virtual scenarios, and "evaluates" the object affordance. If an object is recognized as possessing the requested affordance, our method also predicts the optimal pose for such functionality, and how a potential user can interact with it. Tuned on only a few synthetic examples across 3 affordance classes, our pipeline achieves a very high success rate on affordance classification and functional pose prediction of 8 classes of novel objects, outperforming learning-based baselines. Validation through real robot manipulating experiments demonstrates the practical applicability of the imagined user interaction, showcasing the system's ability to independently conceptualize unseen affordances and interact with new objects and scenarios in everyday settings.