 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECVL-ROUTER: Scenario-Aware Routing for Vision-Language Models
Oct 31, 2025Vision-Language Models (VLMs) excel in diverse multimodal tasks. However, user requirements vary across scenarios, which can be categorized into fast response, high-quality output, and low energy consumption. Relying solely on large models deployed in the cloud for all queries often leads to high latency and energy cost, while small models deployed on edge devices are capable of handling simpler tasks with low latency and energy cost. To fully leverage the strengths of both large and small models, we propose ECVL-ROUTER, the first scenario-aware routing framework for VLMs. Our approach introduces a new routing strategy and evaluation metrics that dynamically select the appropriate model for each query based on user requirements, maximizing overall utility. We also construct a multimodal response-quality dataset tailored for router training and validate the approach through extensive experiments. Results show that our approach successfully routes over 80\% of queries to the small model while incurring less than 10\% drop in problem solving probability.
High-speed Low-consumption sEMG-based Transient-state micro-Gesture Recognition
Mar 13, 2024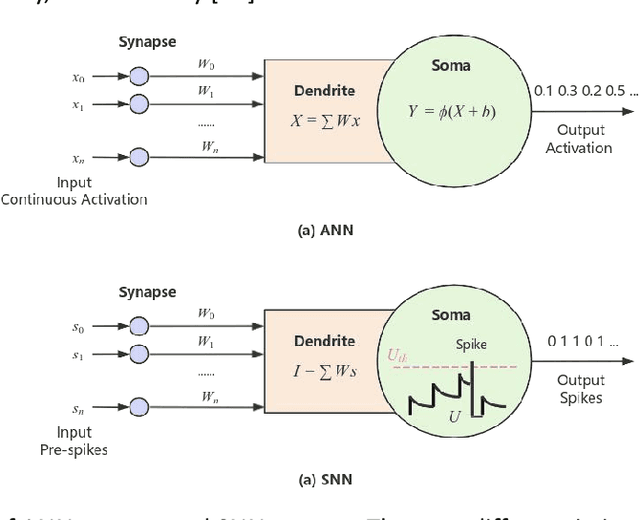
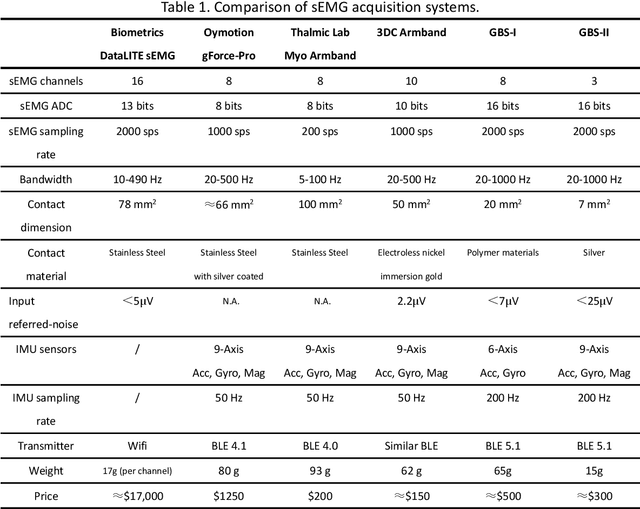
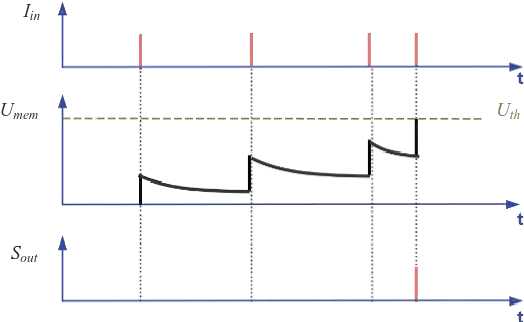
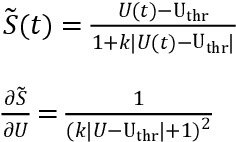
Gesture recognition on wearable devices is extensively applied in human-computer interaction. Electromyography (EMG) has been used in many gesture recognition systems for its rapid perception of muscle signals. However, analyzing EMG signals on devices, like smart wristbands, usually needs inference models to have high performances, such as low inference latency, low power consumption, and low memory occupation. Therefore, this paper proposes an improved spiking neural network (SNN) to achieve these goals. We propose an adaptive multi-delta coding as a spiking coding method to improve recognition accuracy. We propose two additive solvers for SNN, which can reduce inference energy consumption and amount of parameters significantly, and improve the robustness of temporal differences. In addition, we propose a linear action detection method TAD-LIF, which is suitable for SNNs. TAD-LIF is an improved LIF neuron that can detect transient-state gestures quickly and accurately. We collected two datasets from 20 subjects including 6 micro gestures. The collection devices are two designed lightweight consumer-level sEMG wristbands (3 and 8 electrode channels respectively). Compared to CNN, FCN, and normal SNN-based methods, the proposed SNN has higher recognition accuracy. The accuracy of the proposed SNN is 83.85% and 93.52% on the two datasets respectively. In addition, the inference latency of the proposed SNN is about 1% of CNN, the power consumption is about 0.1% of CNN, and the memory occupation is about 20% of CNN. The proposed methods can be used for precise, high-speed, and low-power micro-gesture recognition tasks, and are suitable for consumer-level intelligent wearable devices, which is a general way to achieve ubiquitous computing.
Entity Matching by Pool-based Active Learning
Nov 01, 2022The goal of entity matching is to find the corresponding records representing the same real-world entity from different data sources. At present, in the mainstream methods, rule-based entity matching methods need tremendous domain knowledge. The machine-learning based or deep-learning based entity matching methods need a large number of labeled samples to build the model, which is difficult to achieve in some applications. In addition, learning-based methods are easy to over-fitting, so the quality requirements of training samples are very high. In this paper, we present an active learning method ALMatcher for the entity matching tasks. This method needs to manually label only a small number of valuable samples, and use these samples to build a model with high quality. This paper proposes a hybrid uncertainty as query strategy to find those valuable samples for labeling, which can minimize the number of labeled training samples meanwhile meet the task requirements. The proposed method has been validated on seven data sets in different fields. The experiment shows that ALMatcher uses only a small number of labeled samples and achieves better results compared to existing approaches.