 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSE-SFP: Enabling Unsupervised Sentence Representation Learning via a Single Forward Pass
May 01, 2025As a fundamental task in Information Retrieval and Computational Linguistics, sentence representation has profound implications for a wide range of practical applications such as text clustering, content analysis, question-answering systems, and web search. Recent advances in pre-trained language models (PLMs) have driven remarkable progress in this field, particularly through unsupervised embedding derivation methods centered on discriminative PLMs like BERT. However, due to time and computational constraints, few efforts have attempted to integrate unsupervised sentence representation with generative PLMs, which typically possess much larger parameter sizes. Given that state-of-the-art models in both academia and industry are predominantly based on generative architectures, there is a pressing need for an efficient unsupervised text representation framework tailored to decoder-only PLMs. To address this concern, we propose CSE-SFP, an innovative method that exploits the structural characteristics of generative models. Compared to existing strategies, CSE-SFP requires only a single forward pass to perform effective unsupervised contrastive learning. Rigorous experimentation demonstrates that CSE-SFP not only produces higher-quality embeddings but also significantly reduces both training time and memory consumption. Furthermore, we introduce two ratio metrics that jointly assess alignment and uniformity, thereby providing a more robust means for evaluating the semantic spatial properties of encoding models.
Pcc-tuning: Breaking the Contrastive Learning Ceiling in Semantic Textual Similarity
Jun 14, 2024Semantic Textual Similarity (STS) constitutes a critical research direction in computational linguistics and serves as a key indicator of the encoding capabilities of embedding models. Driven by advances in pre-trained language models and contrastive learning techniques, leading sentence representation methods can already achieved average Spearman's correlation scores of approximately 86 across seven STS benchmarks in SentEval. However, further improvements have become increasingly marginal, with no existing method attaining an average score higher than 87 on these tasks. This paper conducts an in-depth analysis of this phenomenon and concludes that the upper limit for Spearman's correlation scores using contrastive learning is 87.5. To transcend this ceiling, we propose an innovative approach termed Pcc-tuning, which employs Pearson's correlation coefficient as a loss function to refine model performance beyond contrastive learning. Experimental results demonstrate that Pcc-tuning markedly surpasses previous state-of-the-art strategies, raising the Spearman's correlation score to above 90.
Advancing Semantic Textual Similarity Modeling: A Regression Framework with Translated ReLU and Smooth K2 Loss
Jun 08, 2024Since the introduction of BERT and RoBERTa, research on Semantic Textual Similarity (STS) has made groundbreaking progress. Particularly, the adoption of contrastive learning has substantially elevated state-of-the-art performance across various STS benchmarks. However, contrastive learning categorizes text pairs as either semantically similar or dissimilar, failing to leverage fine-grained annotated information and necessitating large batch sizes to prevent model collapse. These constraints pose challenges for researchers engaged in STS tasks that require nuanced similarity levels or those with limited computational resources, compelling them to explore alternatives like Sentence-BERT. Nonetheless, Sentence-BERT tackles STS tasks from a classification perspective, overlooking the progressive nature of semantic relationships, which results in suboptimal performance. To bridge this gap, this paper presents an innovative regression framework and proposes two simple yet effective loss functions: Translated ReLU and Smooth K2 Loss. Experimental analyses demonstrate that our method achieves convincing performance across seven established STS benchmarks, especially when supplemented with task-specific training data.
Simple Techniques for Enhancing Sentence Embeddings in Generative Language Models
Apr 05, 2024Sentence Embedding stands as a fundamental task within the realm of Natural Language Processing, finding extensive application in search engines, expert systems, and question-and-answer platforms. With the continuous evolution of large language models such as LLaMA and Mistral, research on sentence embedding has recently achieved notable breakthroughs. However, these advancements mainly pertain to fine-tuning scenarios, leaving explorations into computationally efficient direct inference methods for sentence representation in a nascent stage. This paper endeavors to bridge this research gap. Through comprehensive experimentation, we challenge the widely held belief in the necessity of an Explicit One-word Limitation for deriving sentence embeddings from Pre-trained Language Models (PLMs). We demonstrate that this approach, while beneficial for generative models under direct inference scenario, is not imperative for discriminative models or the fine-tuning of generative PLMs. This discovery sheds new light on the design of manual templates in future studies. Building upon this insight, we propose two innovative prompt engineering techniques capable of further enhancing the expressive power of PLMs' raw embeddings: Pretended Chain of Thought and Knowledge Enhancement. We confirm their effectiveness across various PLM types and provide a detailed exploration of the underlying factors contributing to their success.
CoT-BERT: Enhancing Unsupervised Sentence Representation through Chain-of-Thought
Sep 20, 2023Unsupervised sentence representation learning aims to transform input sentences into fixed-length vectors enriched with intricate semantic information while obviating the reliance on labeled data. Recent progress within this field, propelled by contrastive learning and prompt engineering, has significantly bridged the gap between unsupervised and supervised strategies. Nonetheless, the potential utilization of Chain-of-Thought, remains largely untapped within this trajectory. To unlock latent capabilities within pre-trained models, such as BERT, we propose a two-stage approach for sentence representation: comprehension and summarization. Subsequently, the output of the latter phase is harnessed as the vectorized representation of the input sentence. For further performance enhancement, we meticulously refine both the contrastive learning loss function and the template denoising technique for prompt engineering. Rigorous experimentation substantiates our method, CoT-BERT, transcending a suite of robust baselines without necessitating other text representation models or external databases.
Entity Matching by Pool-based Active Learning
Nov 01, 2022The goal of entity matching is to find the corresponding records representing the same real-world entity from different data sources. At present, in the mainstream methods, rule-based entity matching methods need tremendous domain knowledge. The machine-learning based or deep-learning based entity matching methods need a large number of labeled samples to build the model, which is difficult to achieve in some applications. In addition, learning-based methods are easy to over-fitting, so the quality requirements of training samples are very high. In this paper, we present an active learning method ALMatcher for the entity matching tasks. This method needs to manually label only a small number of valuable samples, and use these samples to build a model with high quality. This paper proposes a hybrid uncertainty as query strategy to find those valuable samples for labeling, which can minimize the number of labeled training samples meanwhile meet the task requirements. The proposed method has been validated on seven data sets in different fields. The experiment shows that ALMatcher uses only a small number of labeled samples and achieves better results compared to existing approaches.
A Strong Baseline for Crowd Counting and Unsupervised People Localization
Nov 07, 2020
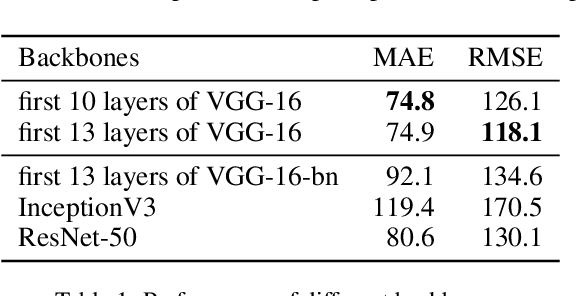


In this paper, we explore a strong baseline for crowd counting and an unsupervised people localization algorithm based on estimated density maps. Firstly, existing methods achieve state-of-the-art performance based on different backbones and kinds of training tricks. We collect different backbones and training tricks and evaluate the impact of changing them and develop an efficient pipeline for crowd counting, which decreases MAE and RMSE significantly on multiple datasets. We also propose a clustering algorithm named isolated KMeans to locate the heads in density maps. This method can divide the density maps into subregions and find the centers under local count constraints without training any parameter and can be integrated with existing methods easily.
Coarse- and Fine-grained Attention Network with Background-aware Loss for Crowd Density Map Estimation
Nov 07, 2020



In this paper, we present a novel method Coarse- and Fine-grained Attention Network (CFANet) for generating high-quality crowd density maps and people count estimation by incorporating attention maps to better focus on the crowd area. We devise a from-coarse-to-fine progressive attention mechanism by integrating Crowd Region Recognizer (CRR) and Density Level Estimator (DLE) branch, which can suppress the influence of irrelevant background and assign attention weights according to the crowd density levels, because generating accurate fine-grained attention maps directly is normally difficult. We also employ a multi-level supervision mechanism to assist the backpropagation of gradient and reduce overfitting. Besides, we propose a Background-aware Structural Loss (BSL) to reduce the false recognition ratio while improving the structural similarity to groundtruth. Extensive experiments on commonly used datasets show that our method can not only outperform previous state-of-the-art methods in terms of count accuracy but also improve the image quality of density maps as well as reduce the false recognition ratio.
Deep Convolutional Neural Network for 6-DOF Image Localization
Nov 08, 2016

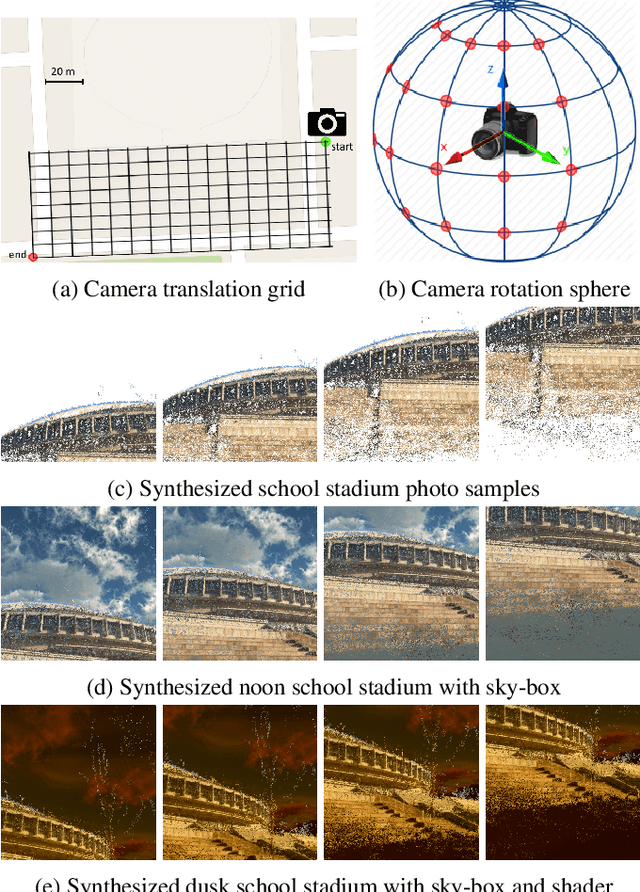

We present an accurate and robust method for six degree of freedom image localization. There are two key-points of our method, 1. automatic immense photo synthesis and labeling from point cloud model and, 2. pose estimation with deep convolutional neural networks regression. Our model can directly regresses 6-DOF camera poses from images, accurately describing where and how it was captured. We achieved an accuracy within 1 meters and 1 degree on our out-door dataset, which covers about 2 acres on our school campus.