 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Autonomous Driving
Mar 19, 2019
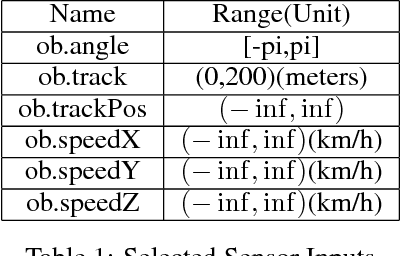
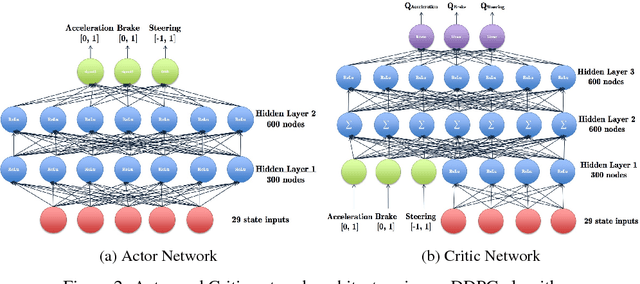

Reinforcement learning has steadily improved and outperform human in lots of traditional games since the resurgence of deep neural network. However, these success is not easy to be copied to autonomous driving because the state spaces in real world are extreme complex and action spaces are continuous and fine control is required. Moreover, the autonomous driving vehicles must also keep functional safety under the complex environments. To deal with these challenges, we first adopt the deep deterministic policy gradient (DDPG) algorithm, which has the capacity to handle complex state and action spaces in continuous domain. We then choose The Open Racing Car Simulator (TORCS) as our environment to avoid physical damage. Meanwhile, we select a set of appropriate sensor information from TORCS and design our own rewarder. In order to fit DDPG algorithm to TORCS, we design our network architecture for both actor and critic inside DDPG paradigm. To demonstrate the effectiveness of our model, We evaluate on different modes in TORCS and show both quantitative and qualitative results.
Semantic-aware Grad-GAN for Virtual-to-Real Urban Scene Adaption
Jul 14, 2018

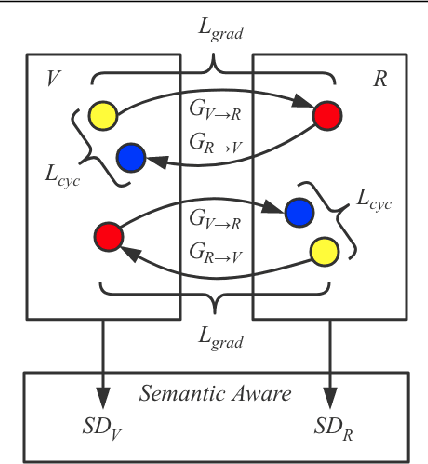
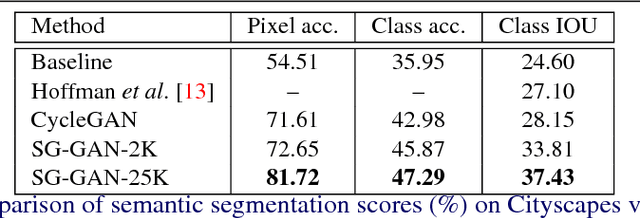
Recent advances in vision tasks (e.g., segmentation) highly depend on the availability of large-scale real-world image annotations obtained by cumbersome human labors. Moreover, the perception performance often drops significantly for new scenarios, due to the poor generalization capability of models trained on limited and biased annotations. In this work, we resort to transfer knowledge from automatically rendered scene annotations in virtual-world to facilitate real-world visual tasks. Although virtual-world annotations can be ideally diverse and unlimited, the discrepant data distributions between virtual and real-world make it challenging for knowledge transferring. We thus propose a novel Semantic-aware Grad-GAN (SG-GAN) to perform virtual-to-real domain adaption with the ability of retaining vital semantic information. Beyond the simple holistic color/texture transformation achieved by prior works, SG-GAN successfully personalizes the appearance adaption for each semantic region in order to preserve their key characteristic for better recognition. It presents two main contributions to traditional GANs: 1) a soft gradient-sensitive objective for keeping semantic boundaries; 2) a semantic-aware discriminator for validating the fidelity of personalized adaptions with respect to each semantic region. Qualitative and quantitative experiments demonstrate the superiority of our SG-GAN in scene adaption over state-of-the-art GANs. Further evaluations on semantic segmentation on Cityscapes show using adapted virtual images by SG-GAN dramatically improves segmentation performance than original virtual data. We release our code at https://github.com/Peilun-Li/SG-GAN.
Deep Convolutional Neural Network for 6-DOF Image Localization
Nov 08, 2016

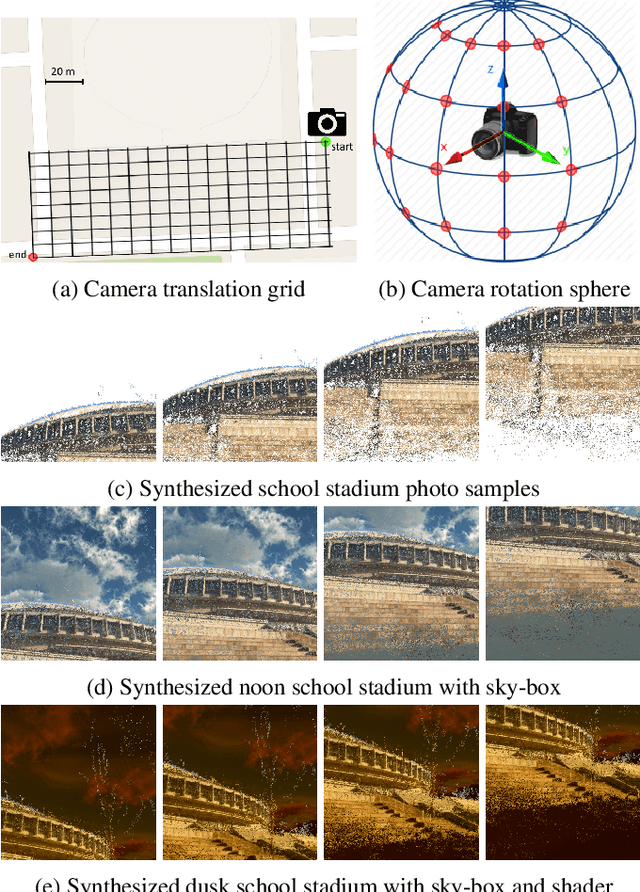

We present an accurate and robust method for six degree of freedom image localization. There are two key-points of our method, 1. automatic immense photo synthesis and labeling from point cloud model and, 2. pose estimation with deep convolutional neural networks regression. Our model can directly regresses 6-DOF camera poses from images, accurately describing where and how it was captured. We achieved an accuracy within 1 meters and 1 degree on our out-door dataset, which covers about 2 acres on our school campus.