 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-aware Grad-GAN for Virtual-to-Real Urban Scene Adaption
Paper and Code


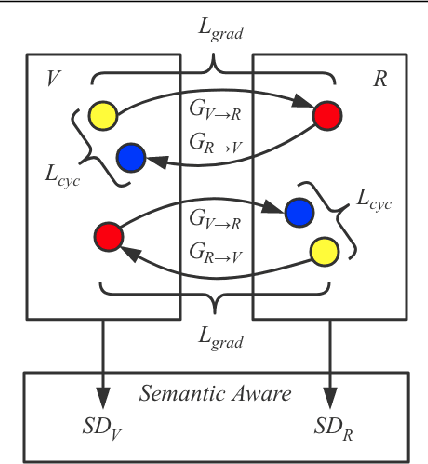
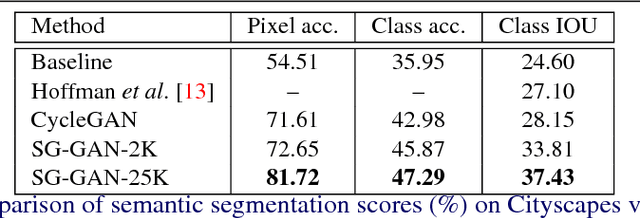
Recent advances in vision tasks (e.g., segmentation) highly depend on the availability of large-scale real-world image annotations obtained by cumbersome human labors. Moreover, the perception performance often drops significantly for new scenarios, due to the poor generalization capability of models trained on limited and biased annotations. In this work, we resort to transfer knowledge from automatically rendered scene annotations in virtual-world to facilitate real-world visual tasks. Although virtual-world annotations can be ideally diverse and unlimited, the discrepant data distributions between virtual and real-world make it challenging for knowledge transferring. We thus propose a novel Semantic-aware Grad-GAN (SG-GAN) to perform virtual-to-real domain adaption with the ability of retaining vital semantic information. Beyond the simple holistic color/texture transformation achieved by prior works, SG-GAN successfully personalizes the appearance adaption for each semantic region in order to preserve their key characteristic for better recognition. It presents two main contributions to traditional GANs: 1) a soft gradient-sensitive objective for keeping semantic boundaries; 2) a semantic-aware discriminator for validating the fidelity of personalized adaptions with respect to each semantic region. Qualitative and quantitative experiments demonstrate the superiority of our SG-GAN in scene adaption over state-of-the-art GANs. Further evaluations on semantic segmentation on Cityscapes show using adapted virtual images by SG-GAN dramatically improves segmentation performance than original virtual data. We release our code at https://github.com/Peilun-Li/SG-GAN.