 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHDME: Physics-Informed Diffusion Models without Explicit Governing Equations
Jan 29, 2026Diffusion models provide expressive priors for forecasting trajectories of dynamical systems, but are typically unreliable in the sparse data regime. Physics-informed machine learning (PIML) improves reliability in such settings; however, most methods require \emph{explicit governing equations} during training, which are often only partially known due to complex and nonlinear dynamics. We introduce \textbf{PHDME}, a port-Hamiltonian diffusion framework designed for \emph{sparse observations} and \emph{incomplete physics}. PHDME leverages port-Hamiltonian structural prior but does not require full knowledge of the closed-form governing equations. Our approach first trains a Gaussian process distributed Port-Hamiltonian system (GP-dPHS) on limited observations to capture an energy-based representation of the dynamics. The GP-dPHS is then used to generate a physically consistent artificial dataset for diffusion training, and to inform the diffusion model with a structured physics residual loss. After training, the diffusion model acts as an amortized sampler and forecaster for fast trajectory generation. Finally, we apply split conformal calibration to provide uncertainty statements for the generated predictions. Experiments on PDE benchmarks and a real-world spring system show improved accuracy and physical consistency under data scarcity.
Plug-and-Play Physics-informed Learning using Uncertainty Quantified Port-Hamiltonian Models
Apr 24, 2025



The ability to predict trajectories of surrounding agents and obstacles is a crucial component in many robotic applications. Data-driven approaches are commonly adopted for state prediction in scenarios where the underlying dynamics are unknown. However, the performance, reliability, and uncertainty of data-driven predictors become compromised when encountering out-of-distribution observations relative to the training data. In this paper, we introduce a Plug-and-Play Physics-Informed Machine Learning (PnP-PIML) framework to address this challenge. Our method employs conformal prediction to identify outlier dynamics and, in that case, switches from a nominal predictor to a physics-consistent model, namely distributed Port-Hamiltonian systems (dPHS). We leverage Gaussian processes to model the energy function of the dPHS, enabling not only the learning of system dynamics but also the quantification of predictive uncertainty through its Bayesian nature. In this way, the proposed framework produces reliable physics-informed predictions even for the out-of-distribution scenarios.
Physics-Constrained Learning for PDE Systems with Uncertainty Quantified Port-Hamiltonian Models
Jun 17, 2024



Modeling the dynamics of flexible objects has become an emerging topic in the community as these objects become more present in many applications, e.g., soft robotics. Due to the properties of flexible materials, the movements of soft objects are often highly nonlinear and, thus, complex to predict. Data-driven approaches seem promising for modeling those complex dynamics but often neglect basic physical principles, which consequently makes them untrustworthy and limits generalization. To address this problem, we propose a physics-constrained learning method that combines powerful learning tools and reliable physical models. Our method leverages the data collected from observations by sending them into a Gaussian process that is physically constrained by a distributed Port-Hamiltonian model. Based on the Bayesian nature of the Gaussian process, we not only learn the dynamics of the system, but also enable uncertainty quantification. Furthermore, the proposed approach preserves the compositional nature of Port-Hamiltonian systems.
Semantic-aware Grad-GAN for Virtual-to-Real Urban Scene Adaption
Jul 14, 2018

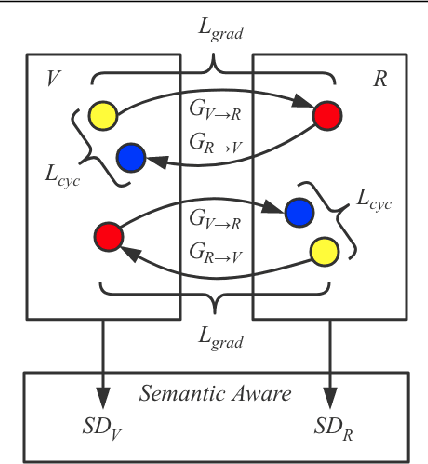
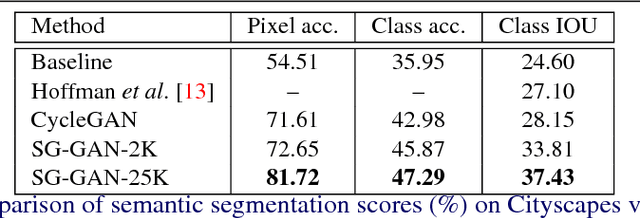
Recent advances in vision tasks (e.g., segmentation) highly depend on the availability of large-scale real-world image annotations obtained by cumbersome human labors. Moreover, the perception performance often drops significantly for new scenarios, due to the poor generalization capability of models trained on limited and biased annotations. In this work, we resort to transfer knowledge from automatically rendered scene annotations in virtual-world to facilitate real-world visual tasks. Although virtual-world annotations can be ideally diverse and unlimited, the discrepant data distributions between virtual and real-world make it challenging for knowledge transferring. We thus propose a novel Semantic-aware Grad-GAN (SG-GAN) to perform virtual-to-real domain adaption with the ability of retaining vital semantic information. Beyond the simple holistic color/texture transformation achieved by prior works, SG-GAN successfully personalizes the appearance adaption for each semantic region in order to preserve their key characteristic for better recognition. It presents two main contributions to traditional GANs: 1) a soft gradient-sensitive objective for keeping semantic boundaries; 2) a semantic-aware discriminator for validating the fidelity of personalized adaptions with respect to each semantic region. Qualitative and quantitative experiments demonstrate the superiority of our SG-GAN in scene adaption over state-of-the-art GANs. Further evaluations on semantic segmentation on Cityscapes show using adapted virtual images by SG-GAN dramatically improves segmentation performance than original virtual data. We release our code at https://github.com/Peilun-Li/SG-GAN.