 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Probabilistic Collision Detection for Motion Planning Under Sensing Uncertainty
Feb 21, 2025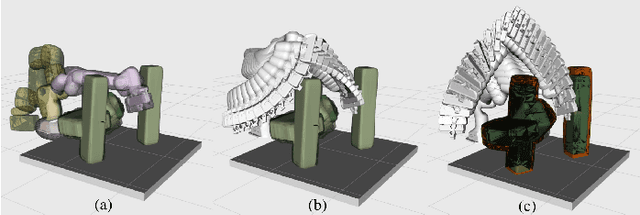
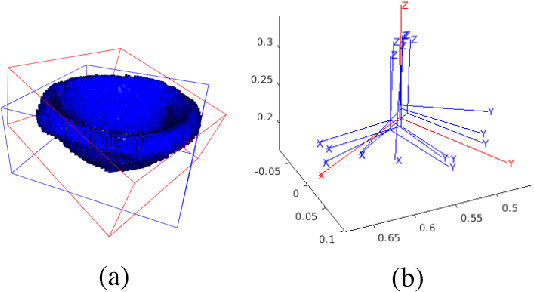
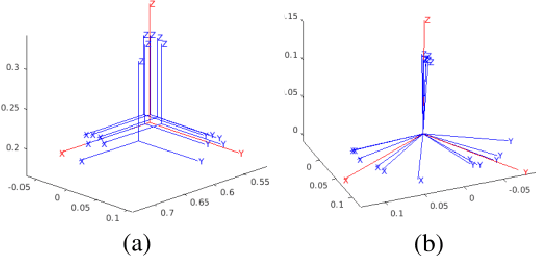

Probabilistic collision detection (PCD) is essential in motion planning for robots operating in unstructured environments, where considering sensing uncertainty helps prevent damage. Existing PCD methods mainly used simplified geometric models and addressed only position estimation errors. This paper presents an enhanced PCD method with two key advancements: (a) using superquadrics for more accurate shape approximation and (b) accounting for both position and orientation estimation errors to improve robustness under sensing uncertainty. Our method first computes an enlarged surface for each object that encapsulates its observed rotated copies, thereby addressing the orientation estimation errors. Then, the collision probability under the position estimation errors is formulated as a chance-constraint problem that is solved with a tight upper bound. Both the two steps leverage the recently developed normal parameterization of superquadric surfaces. Results show that our PCD method is twice as close to the Monte-Carlo sampled baseline as the best existing PCD method and reduces path length by 30% and planning time by 37%, respectively. A Real2Sim pipeline further validates the importance of considering orientation estimation errors, showing that the collision probability of executing the planned path in simulation is only 2%, compared to 9% and 29% when considering only position estimation errors or none at all.
Transporters with Visual Foresight for Solving Unseen Rearrangement Tasks
Feb 22, 2022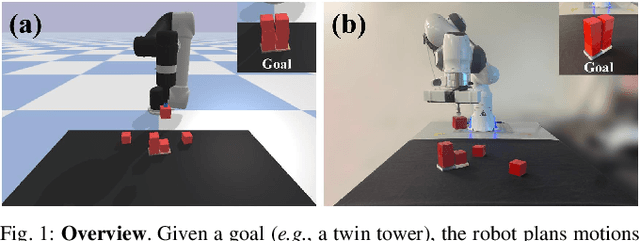
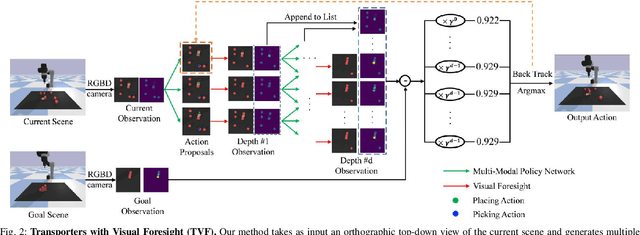
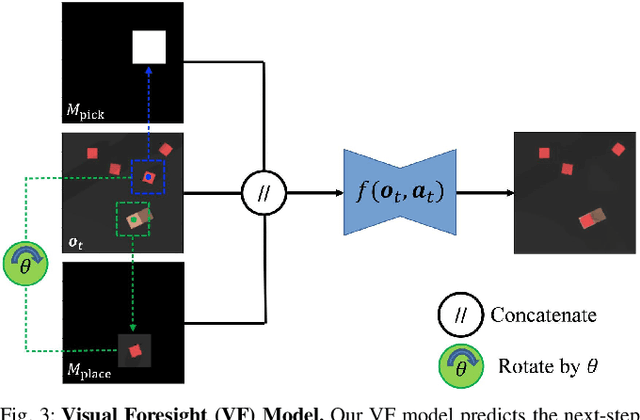

Rearrangement tasks have been identified as a crucial challenge for intelligent robotic manipulation, but few methods allow for precise construction of unseen structures. We propose a visual foresight model for pick-and-place manipulation which is able to learn efficiently. In addition, we develop a multi-modal action proposal module which builds on Goal-Conditioned Transporter Networks, a state-of-the-art imitation learning method. Our method, Transporters with Visual Foresight (TVF), enables task planning from image data and is able to achieve multi-task learning and zero-shot generalization to unseen tasks with only a handful of expert demonstrations. TVF is able to improve the performance of a state-of-the-art imitation learning method on both training and unseen tasks in simulation and real robot experiments. In particular, the average success rate on unseen tasks improves from 55.0% to 77.9% in simulation experiments and from 30% to 63.3% in real robot experiments when given only tens of expert demonstrations. More details can be found on our project website: https://chirikjianlab.github.io/tvf/
Put the Bear on the Chair! Intelligent Robot Interaction with Previously Unseen Objects via Robot Imagination
Aug 12, 2021

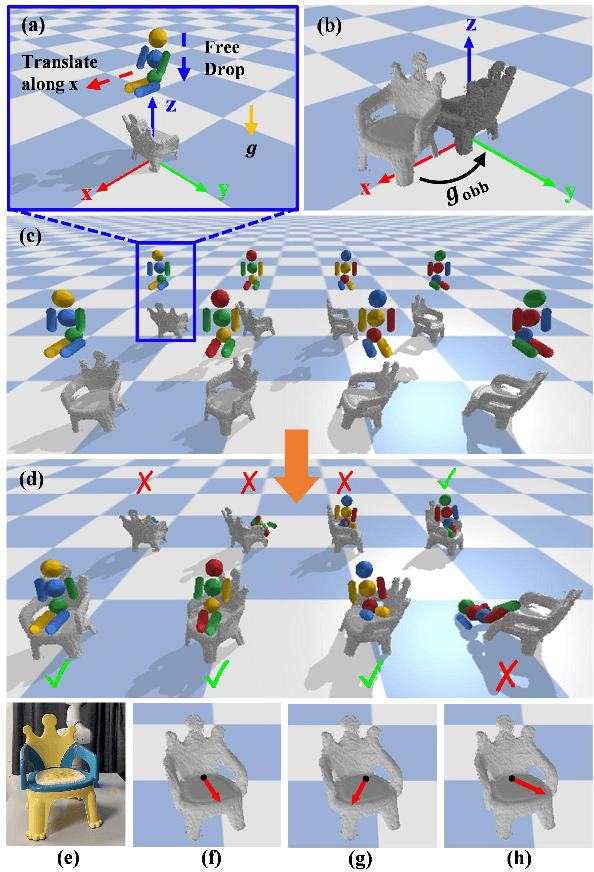

In this letter, we study the problem of autonomously placing a teddy bear on a previously unseen chair for sitting. To achieve this goal, we present a novel method for robots to imagine the sitting pose of the bear by physically simulating a virtual humanoid agent sitting on the chair. We also develop a robotic system which leverages motion planning to plan SE(2) motions for a humanoid robot to walk to the chair and whole-body motions to put the bear on it, respectively. Furthermore, to cope with the cases where the chair is not in an accessible pose for placing the bear, a human-robot interaction (HRI) framework is introduced in which a human follows language instructions given by the robot to rotate the chair and help make the chair accessible. We implement our method with a robot arm and a humanoid robot. We calibrate the proposed system with 3 chairs and test on 12 previously unseen chairs in both accessible and inaccessible poses extensively. Results show that our method enables the robot to autonomously put the teddy bear on the 12 unseen chairs with a very high success rate. The HRI framework is also shown to be very effective in changing the accessibility of the chair. Source code will be available. Video demos are available at https://chirikjianlab.github.io/putbearonchair/.
Towards Efficient Graph Convolutional Networks for Point Cloud Handling
Apr 12, 2021


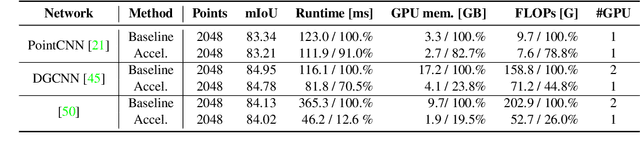
In this paper, we aim at improving the computational efficiency of graph convolutional networks (GCNs) for learning on point clouds. The basic graph convolution that is typically composed of a $K$-nearest neighbor (KNN) search and a multilayer perceptron (MLP) is examined. By mathematically analyzing the operations there, two findings to improve the efficiency of GCNs are obtained. (1) The local geometric structure information of 3D representations propagates smoothly across the GCN that relies on KNN search to gather neighborhood features. This motivates the simplification of multiple KNN searches in GCNs. (2) Shuffling the order of graph feature gathering and an MLP leads to equivalent or similar composite operations. Based on those findings, we optimize the computational procedure in GCNs. A series of experiments show that the optimized networks have reduced computational complexity, decreased memory consumption, and accelerated inference speed while maintaining comparable accuracy for learning on point clouds. Code will be available at \url{https://github.com/ofsoundof/EfficientGCN.git}.
LSG-CPD: Coherent Point Drift with Local Surface Geometry for Point Cloud Registration
Mar 28, 2021
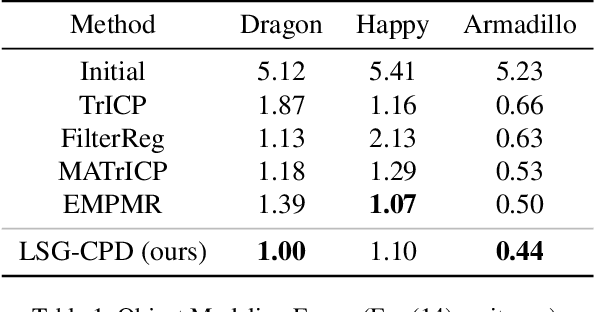
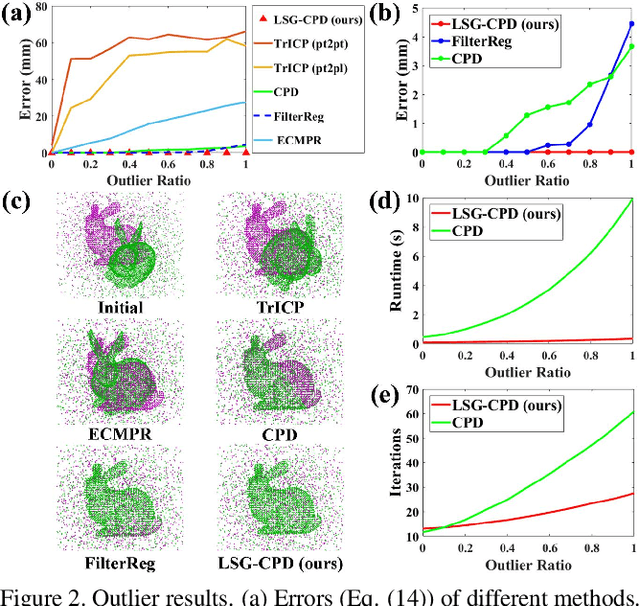
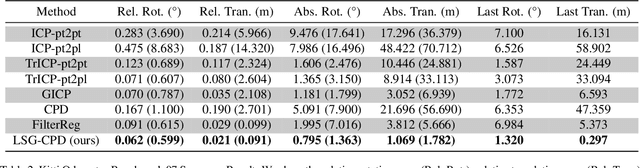
Probabilistic point cloud registration methods are becoming more popular because of their robustness. However, unlike point-to-plane variants of iterative closest point (ICP) which incorporate local surface geometric information such as surface normals, most probabilistic methods (e.g., coherent point drift (CPD)) ignore such information and build Gaussian mixture models (GMMs) with isotropic Gaussian covariances. This results in sphere-like GMM components which only penalize the point-to-point distance between the two point clouds. In this paper, we propose a novel method called CPD with Local Surface Geometry (LSG-CPD) for rigid point cloud registration. Our method adaptively adds different levels of point-to-plane penalization on top of the point-to-point penalization based on the flatness of the local surface. This results in GMM components with anisotropic covariances. We formulate point cloud registration as a maximum likelihood estimation (MLE) problem and solve it with the Expectation-Maximization (EM) algorithm. In the E step, we demonstrate that the computation can be recast into simple matrix manipulations and efficiently computed on a GPU. In the M step, we perform an unconstrained optimization on a matrix Lie group to efficiently update the rigid transformation of the registration. The proposed method outperforms state-of-the-art algorithms in terms of accuracy and robustness on various datasets captured with range scanners, RGBD cameras, and LiDARs. Also, it is significantly faster than modern implementations of CPD. The code will be released.
Multi-person 3D Pose Estimation in Crowded Scenes Based on Multi-View Geometry
Jul 21, 2020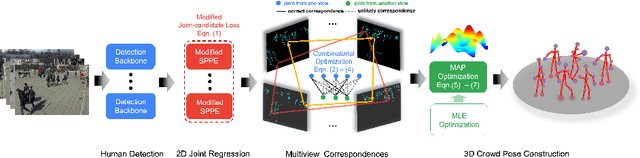

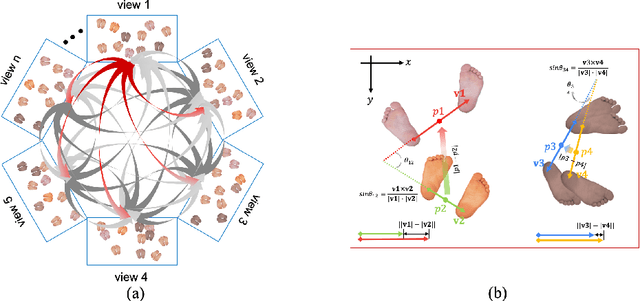

Epipolar constraints are at the core of feature matching and depth estimation in current multi-person multi-camera 3D human pose estimation methods. Despite the satisfactory performance of this formulation in sparser crowd scenes, its effectiveness is frequently challenged under denser crowd circumstances mainly due to two sources of ambiguity. The first is the mismatch of human joints resulting from the simple cues provided by the Euclidean distances between joints and epipolar lines. The second is the lack of robustness from the naive formulation of the problem as a least squares minimization. In this paper, we depart from the multi-person 3D pose estimation formulation, and instead reformulate it as crowd pose estimation. Our method consists of two key components: a graph model for fast cross-view matching, and a maximum a posteriori (MAP) estimator for the reconstruction of the 3D human poses. We demonstrate the effectiveness and superiority of our proposed method on four benchmark datasets.
Sensorless Pose Determination using Randomized Action Sequences
Dec 04, 2018
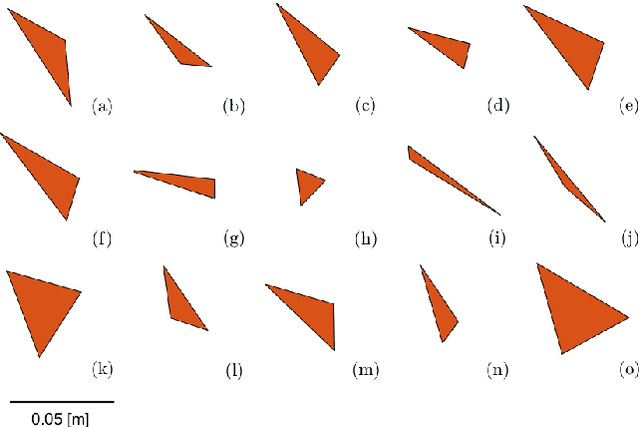
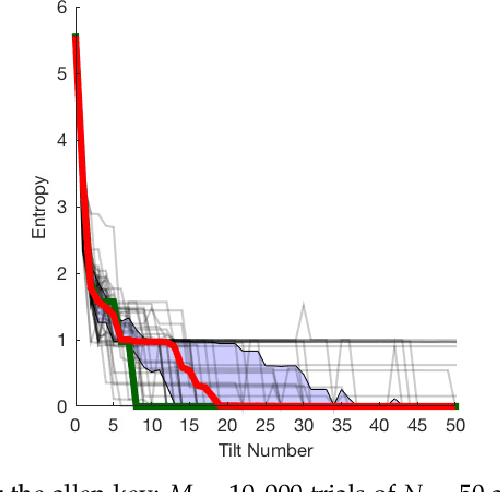
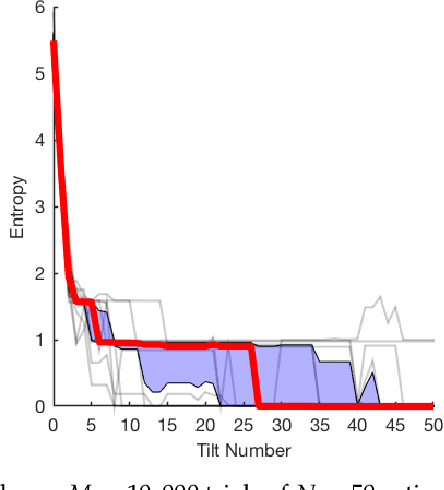
This paper is a study of 2D manipulation without sensing and planning, by exploring the effects of unplanned randomized action sequences on 2D object pose uncertainty. Our approach follows the work of Erdmann and Mason's sensorless reorienting of an object into a completely determined pose, regardless of its initial pose. While Erdmann and Mason proposed a method using Newtonian mechanics, this paper shows that under some circumstances, a long enough sequence of random actions will also converge toward a determined final pose of the object. This is verified through several simulation and real robot experiments where randomized action sequences are shown to reduce entropy of the object pose distribution. The effects of varying object shapes, action sequences, and surface friction are also explored.
Proceedings of the 1st International Workshop on Robot Learning and Planning
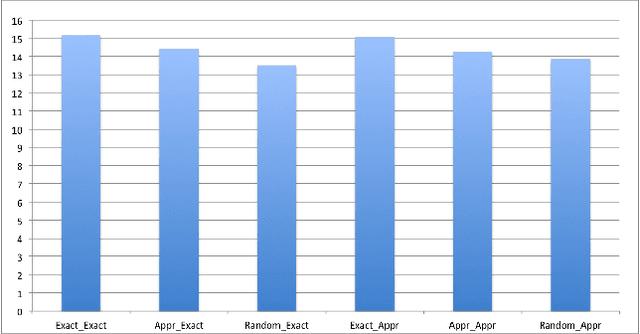
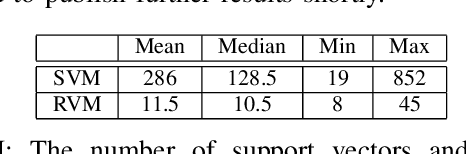
Oct 08, 2016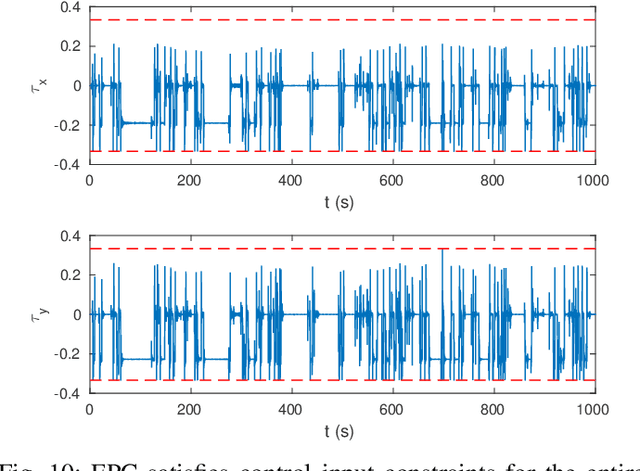

Proceedings of the 1st International Workshop on Robot Learning and Planning (RLP 2016)