 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaggeDi: Diffusion-based State Estimation of Disordered Rags, Sheets, Towels and Blankets
Sep 18, 2024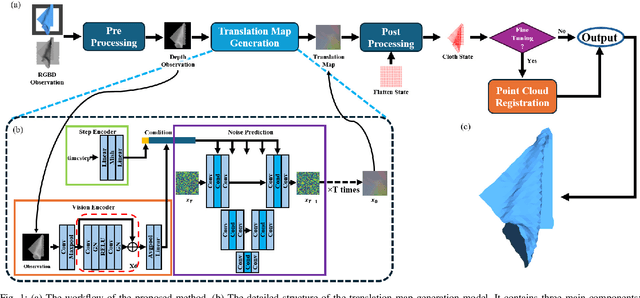
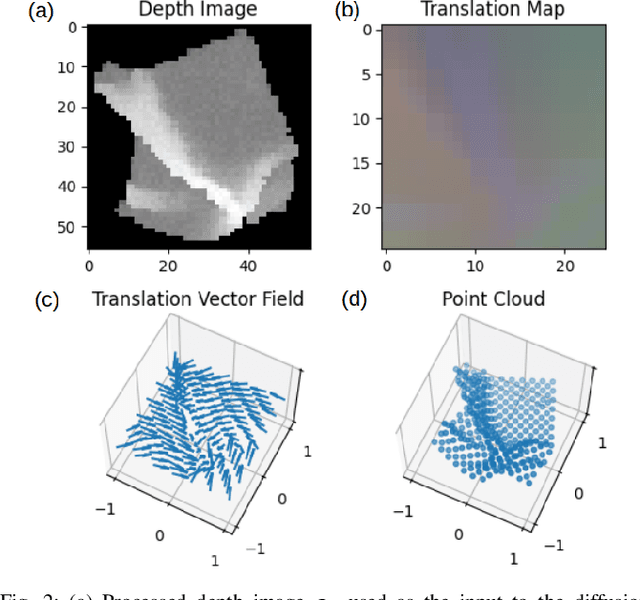

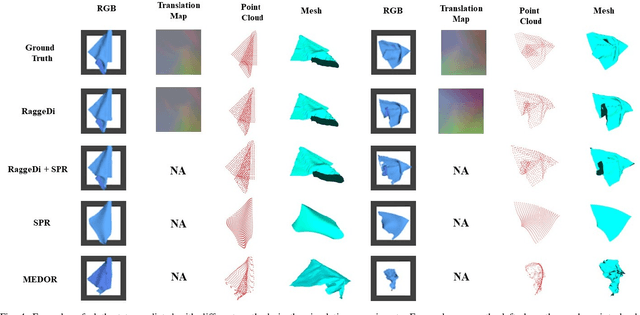
Cloth state estimation is an important problem in robotics. It is essential for the robot to know the accurate state to manipulate cloth and execute tasks such as robotic dressing, stitching, and covering/uncovering human beings. However, estimating cloth state accurately remains challenging due to its high flexibility and self-occlusion. This paper proposes a diffusion model-based pipeline that formulates the cloth state estimation as an image generation problem by representing the cloth state as an RGB image that describes the point-wise translation (translation map) between a pre-defined flattened mesh and the deformed mesh in a canonical space. Then we train a conditional diffusion-based image generation model to predict the translation map based on an observation. Experiments are conducted in both simulation and the real world to validate the performance of our method. Results indicate that our method outperforms two recent methods in both accuracy and speed.
Uncertainty Propagation on Unimodular Matrix Lie Groups
Dec 06, 2023This paper addresses uncertainty propagation on unimodular matrix Lie groups that have a surjective exponential map. We derive the exact formula for the propagation of mean and covariance in a continuous-time setting from the governing Fokker-Planck equation. Two approximate propagation methods are discussed based on the exact formula. One uses numerical quadrature and another utilizes the expansion of moments. A closed-form second-order propagation formula is derived. We apply the general theory to the joint attitude and angular momentum uncertainty propagation problem and numerical experiments demonstrate two approximation methods. These results show that our new methods have high accuracy while being computationally efficient.
Transporters with Visual Foresight for Solving Unseen Rearrangement Tasks
Feb 22, 2022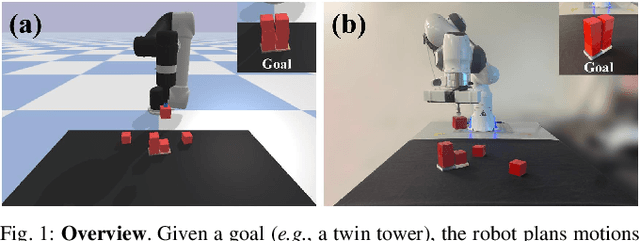
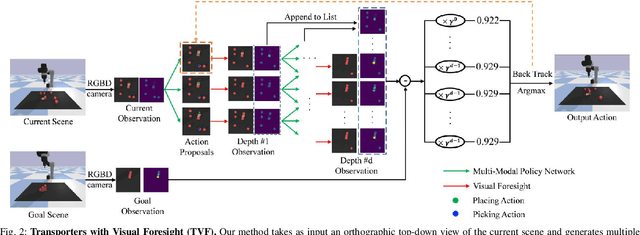
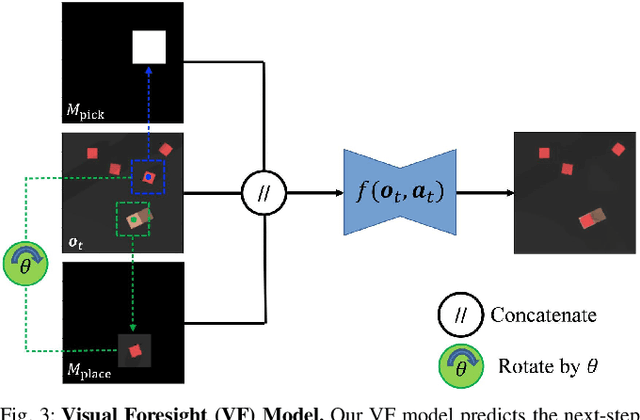

Rearrangement tasks have been identified as a crucial challenge for intelligent robotic manipulation, but few methods allow for precise construction of unseen structures. We propose a visual foresight model for pick-and-place manipulation which is able to learn efficiently. In addition, we develop a multi-modal action proposal module which builds on Goal-Conditioned Transporter Networks, a state-of-the-art imitation learning method. Our method, Transporters with Visual Foresight (TVF), enables task planning from image data and is able to achieve multi-task learning and zero-shot generalization to unseen tasks with only a handful of expert demonstrations. TVF is able to improve the performance of a state-of-the-art imitation learning method on both training and unseen tasks in simulation and real robot experiments. In particular, the average success rate on unseen tasks improves from 55.0% to 77.9% in simulation experiments and from 30% to 63.3% in real robot experiments when given only tens of expert demonstrations. More details can be found on our project website: https://chirikjianlab.github.io/tvf/