 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransporters with Visual Foresight for Solving Unseen Rearrangement Tasks
Paper and Code
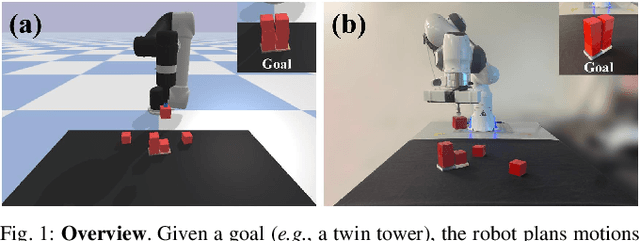
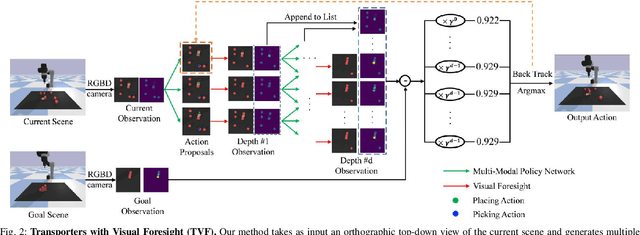
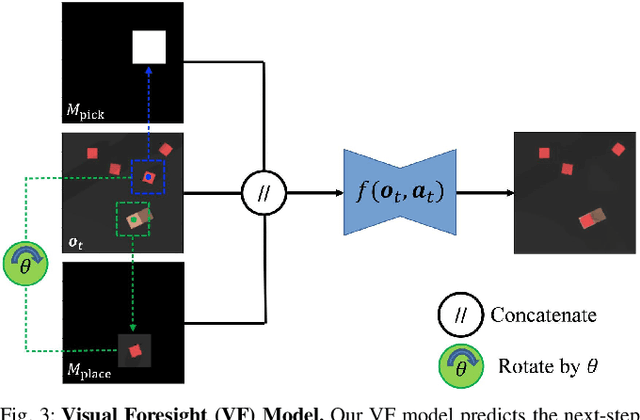

Rearrangement tasks have been identified as a crucial challenge for intelligent robotic manipulation, but few methods allow for precise construction of unseen structures. We propose a visual foresight model for pick-and-place manipulation which is able to learn efficiently. In addition, we develop a multi-modal action proposal module which builds on Goal-Conditioned Transporter Networks, a state-of-the-art imitation learning method. Our method, Transporters with Visual Foresight (TVF), enables task planning from image data and is able to achieve multi-task learning and zero-shot generalization to unseen tasks with only a handful of expert demonstrations. TVF is able to improve the performance of a state-of-the-art imitation learning method on both training and unseen tasks in simulation and real robot experiments. In particular, the average success rate on unseen tasks improves from 55.0% to 77.9% in simulation experiments and from 30% to 63.3% in real robot experiments when given only tens of expert demonstrations. More details can be found on our project website: https://chirikjianlab.github.io/tvf/