 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Probabilistic Collision Detection for Motion Planning Under Sensing Uncertainty
Feb 21, 2025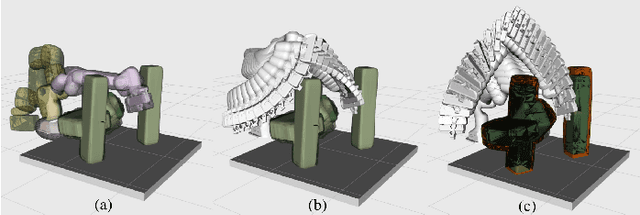

Probabilistic collision detection (PCD) is essential in motion planning for robots operating in unstructured environments, where considering sensing uncertainty helps prevent damage. Existing PCD methods mainly used simplified geometric models and addressed only position estimation errors. This paper presents an enhanced PCD method with two key advancements: (a) using superquadrics for more accurate shape approximation and (b) accounting for both position and orientation estimation errors to improve robustness under sensing uncertainty. Our method first computes an enlarged surface for each object that encapsulates its observed rotated copies, thereby addressing the orientation estimation errors. Then, the collision probability under the position estimation errors is formulated as a chance-constraint problem that is solved with a tight upper bound. Both the two steps leverage the recently developed normal parameterization of superquadric surfaces. Results show that our PCD method is twice as close to the Monte-Carlo sampled baseline as the best existing PCD method and reduces path length by 30% and planning time by 37%, respectively. A Real2Sim pipeline further validates the importance of considering orientation estimation errors, showing that the collision probability of executing the planned path in simulation is only 2%, compared to 9% and 29% when considering only position estimation errors or none at all.
Prepare the Chair for the Bear! Robot Imagination of Sitting Affordance to Reorient Previously Unseen Chairs
Jun 20, 2023



In this letter, a paradigm for the classification and manipulation of previously unseen objects is established and demonstrated through a real example of chairs. We present a novel robot manipulation method, guided by the understanding of object stability, perceptibility, and affordance, which allows the robot to prepare previously unseen and randomly oriented chairs for a teddy bear to sit on. Specifically, the robot encounters an unknown object and first reconstructs a complete 3D model from perceptual data via active and autonomous manipulation. By inserting this model into a physical simulator (i.e., the robot's "imagination"), the robot assesses whether the object is a chair and determines how to reorient it properly to be used, i.e., how to reorient it to an upright and accessible pose. If the object is classified as a chair, the robot reorients the object to this pose and seats the teddy bear onto the chair. The teddy bear is a proxy for an elderly person, hospital patient, or child. Experiment results show that our method achieves a high success rate on the real robot task of chair preparation. Also, it outperforms several baseline methods on the task of upright pose prediction for chairs.
PRIMP: PRobabilistically-Informed Motion Primitives for Efficient Affordance Learning from Demonstration
May 25, 2023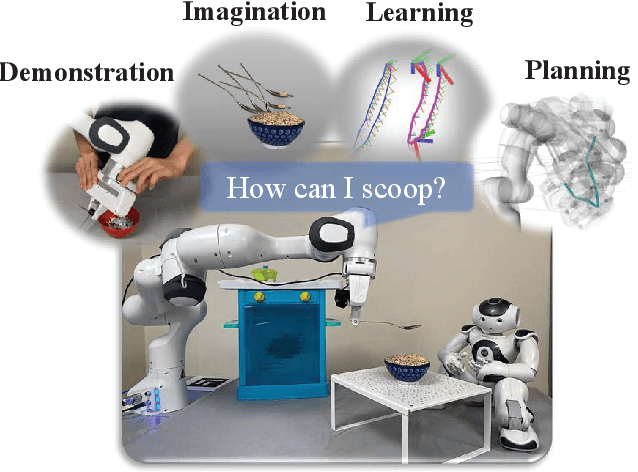



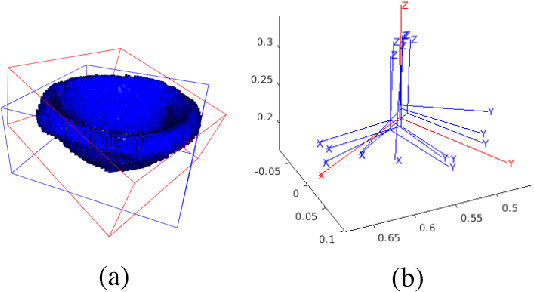
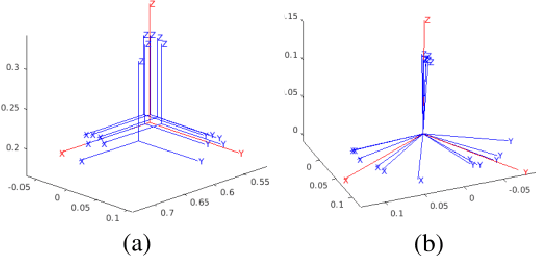
This paper proposes a learning-from-demonstration method using probability densities on the workspaces of robot manipulators. The method, named "PRobabilistically-Informed Motion Primitives (PRIMP)", learns the probability distribution of the end effector trajectories in the 6D workspace that includes both positions and orientations. It is able to adapt to new situations such as novel via poses with uncertainty and a change of viewing frame. The method itself is robot-agnostic, in which the learned distribution can be transferred to another robot with the adaptation to its workspace density. The learned trajectory distribution is then used to guide an optimization-based motion planning algorithm to further help the robot avoid novel obstacles that are unseen during the demonstration process. The proposed methods are evaluated by several sets of benchmark experiments. PRIMP runs more than 5 times faster while generalizing trajectories more than twice as close to both the demonstrations and novel desired poses. It is then combined with our robot imagination method that learns object affordances, illustrating the applicability of PRIMP to learn tool use through physical experiments.
Marching-Primitives: Shape Abstraction from Signed Distance Function
Mar 23, 2023Representing complex objects with basic geometric primitives has long been a topic in computer vision. Primitive-based representations have the merits of compactness and computational efficiency in higher-level tasks such as physics simulation, collision checking, and robotic manipulation. Unlike previous works which extract polygonal meshes from a signed distance function (SDF), in this paper, we present a novel method, named Marching-Primitives, to obtain a primitive-based abstraction directly from an SDF. Our method grows geometric primitives (such as superquadrics) iteratively by analyzing the connectivity of voxels while marching at different levels of signed distance. For each valid connected volume of interest, we march on the scope of voxels from which a primitive is able to be extracted in a probabilistic sense and simultaneously solve for the parameters of the primitive to capture the underlying local geometry. We evaluate the performance of our method on both synthetic and real-world datasets. The results show that the proposed method outperforms the state-of-the-art in terms of accuracy, and is directly generalizable among different categories and scales. The code is open-sourced at https://github.com/ChirikjianLab/Marching-Primitives.git.
Primitive-based Shape Abstraction via Nonparametric Bayesian Inference
Mar 28, 2022



3D shape abstraction has drawn great interest over the years. Apart from low-level representations such as meshes and voxels, researchers also seek to semantically abstract complex objects with basic geometric primitives. Recent deep learning methods rely heavily on datasets, with limited generality to unseen categories. Furthermore, abstracting an object accurately yet with a small number of primitives still remains a challenge. In this paper, we propose a novel non-parametric Bayesian statistical method to infer an abstraction, consisting of an unknown number of geometric primitives, from a point cloud. We model the generation of points as observations sampled from an infinite mixture of Gaussian Superquadric Taper Models (GSTM). Our approach formulates the abstraction as a clustering problem, in which: 1) each point is assigned to a cluster via the Chinese Restaurant Process (CRP); 2) a primitive representation is optimized for each cluster, and 3) a merging post-process is incorporated to provide a concise representation. We conduct extensive experiments on various datasets. The results indicate that our method outperforms the state-of-the-art in terms of accuracy and is generalizable to various types of objects.
Robust and Accurate Superquadric Recovery: a Probabilistic Approach
Nov 29, 2021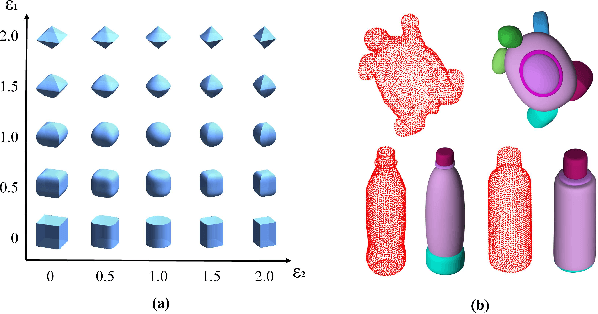


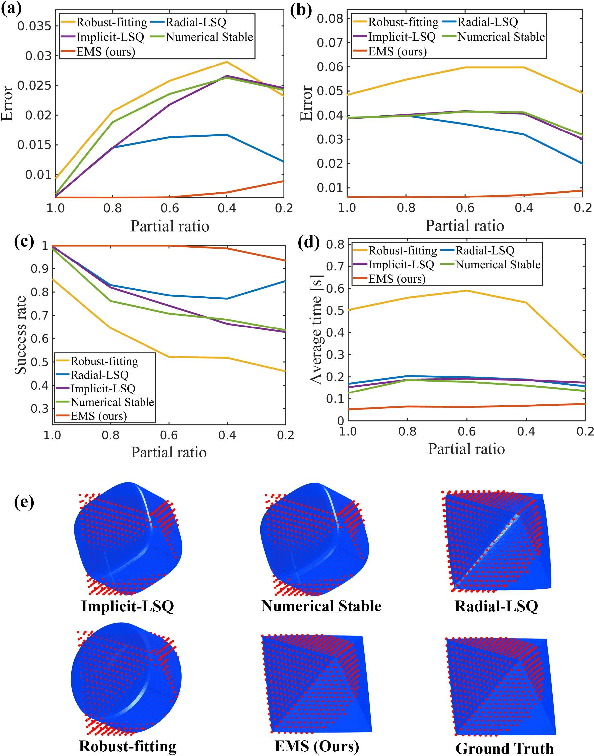
Interpreting objects with basic geometric primitives has long been studied in computer vision. Among geometric primitives, superquadrics are well known for their simple implicit expressions and capability of representing a wide range of shapes with few parameters. However, as the first and foremost step, recovering superquadrics accurately and robustly from 3D data still remains challenging. The existing methods are subject to local optima and are sensitive to noise and outliers in real-world scenarios, resulting in frequent failure in capturing geometric shapes. In this paper, we propose the first probabilistic method to recover superquadrics from point clouds. Our method builds a Gaussian-uniform mixture model (GUM) on the parametric surface of a superquadric, which explicitly models the generation of outliers and noise. The superquadric recovery is formulated as a Maximum Likelihood Estimation (MLE) problem. We propose an algorithm, Expectation, Maximization, and Switching (EMS), to solve this problem, where: (1) outliers are predicted from the posterior perspective; (2) the superquadric parameter is optimized by the trust-region reflective algorithm; and (3) local optima are avoided by globally searching and switching among parameters encoding similar superquadrics. We show that our method can be extended to the multi-superquadrics recovery for complex objects. The proposed method outperforms the state-of-the-art in terms of accuracy, efficiency, and robustness on both synthetic and real-world datasets. Codes will be released.
Put the Bear on the Chair! Intelligent Robot Interaction with Previously Unseen Objects via Robot Imagination
Aug 12, 2021

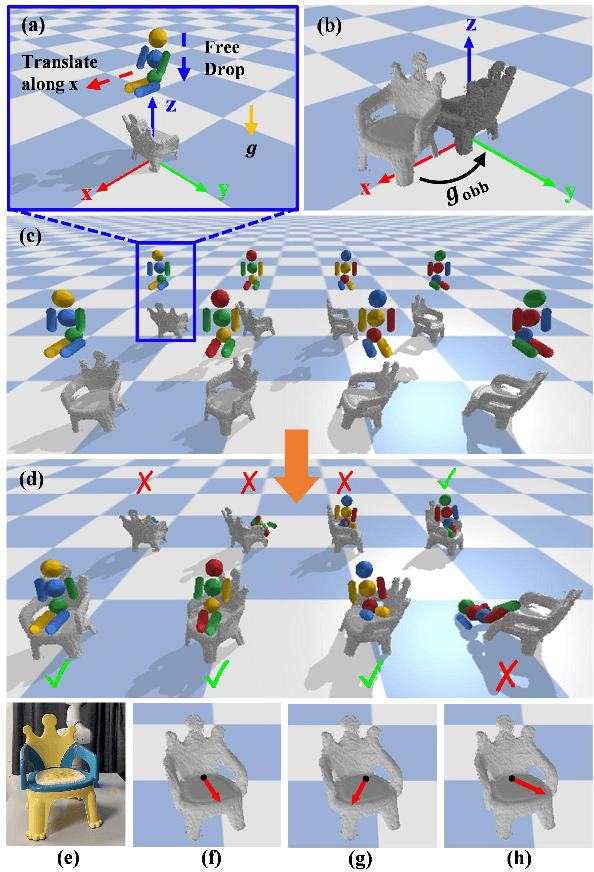

In this letter, we study the problem of autonomously placing a teddy bear on a previously unseen chair for sitting. To achieve this goal, we present a novel method for robots to imagine the sitting pose of the bear by physically simulating a virtual humanoid agent sitting on the chair. We also develop a robotic system which leverages motion planning to plan SE(2) motions for a humanoid robot to walk to the chair and whole-body motions to put the bear on it, respectively. Furthermore, to cope with the cases where the chair is not in an accessible pose for placing the bear, a human-robot interaction (HRI) framework is introduced in which a human follows language instructions given by the robot to rotate the chair and help make the chair accessible. We implement our method with a robot arm and a humanoid robot. We calibrate the proposed system with 3 chairs and test on 12 previously unseen chairs in both accessible and inaccessible poses extensively. Results show that our method enables the robot to autonomously put the teddy bear on the 12 unseen chairs with a very high success rate. The HRI framework is also shown to be very effective in changing the accessibility of the chair. Source code will be available. Video demos are available at https://chirikjianlab.github.io/putbearonchair/.
Efficient Path Planning in Narrow Passages via Closed-Form Minkowski Operations
Apr 10, 2021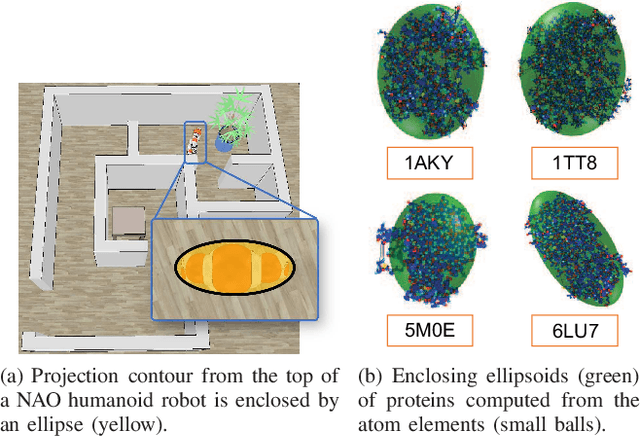
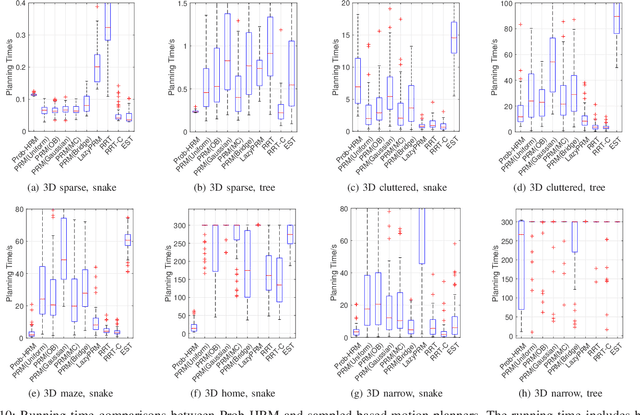

Path planning has long been one of the major research areas in robotics, with PRM and RRT being two of the most effective classes of path planners. Though generally very efficient, these sampling-based planners can become computationally expensive in the important case of "narrow passages". This paper develops a path planning paradigm specifically formulated for narrow passage problems. The core is based on planning for rigid-body robots encapsulated by unions of ellipsoids. The environmental features are enclosed geometrically using convex differentiable surfaces (e.g., superquadrics). The main benefit of doing this is that configuration-space obstacles can be parameterized explicitly in closed form, thereby allowing prior knowledge to be used to avoid sampling infeasible configurations. Then, by characterizing a tight volume bound for multiple ellipsoids, robot transitions involving rotations are guaranteed to be collision-free without traditional collision detection. Furthermore, combining the stochastic sampling strategy, the proposed planning framework can be extended to solving higher dimensional problems in which the robot has a moving base and articulated appendages. Benchmark results show that, remarkably, the proposed framework outperforms the popular sampling-based planners in terms of computational time and success rate in finding a path through narrow corridors and in higher dimensional configuration spaces.
Closed-Form Minkowski Sums of Convex Bodies with Smooth Positively Curved Boundaries
Dec 31, 2020
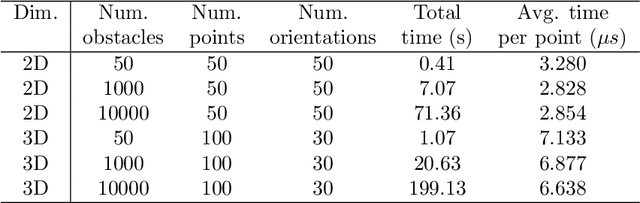
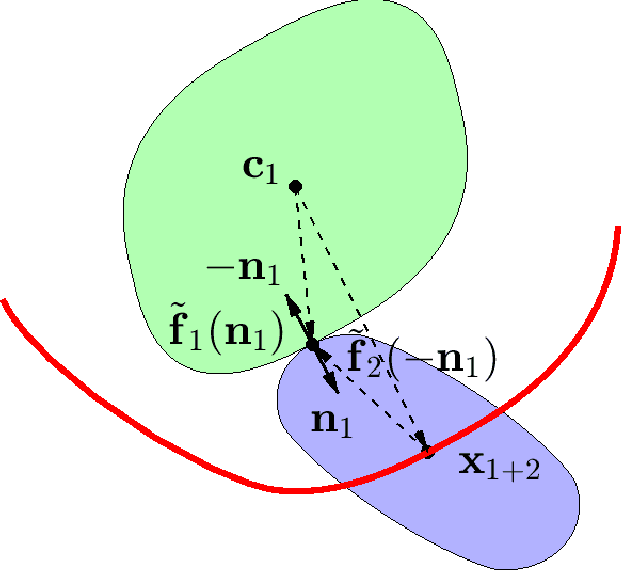
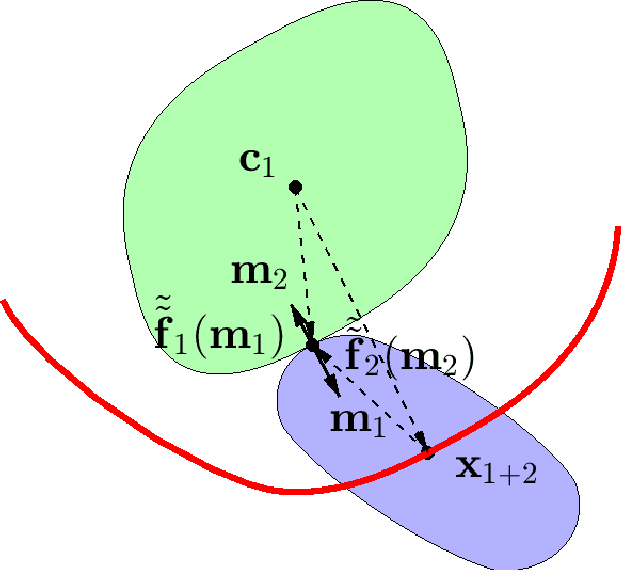
This paper proposes a closed-form parametric formula of the Minkowski sum boundary for broad classes of convex bodies in d-dimensional Euclidean space. With positive sectional curvatures at every point, the boundary that encloses each body can be characterized by the surface gradient. The first theorem directly parameterizes the Minkowski sums using the unit normal vector at each body surface. Although simple to express mathematically, such a parameterization is not always practical to obtain computationally. Therefore, the second theorem derives a more useful parametric closed-form expression using the gradient that is not normalized. In the special case of two ellipsoids, the proposed expressions are identical to those derived previously using geometric interpretations. In order to further examine the results, numerical verifications and comparisons of the Minkowski sums between two superquadric bodies are conducted. The application for the generation of configuration space obstacles in motion planning problems is introduced and demonstrated.
Quotienting Impertinent Camera Kinematics for 3D Video Stabilization
Mar 21, 2019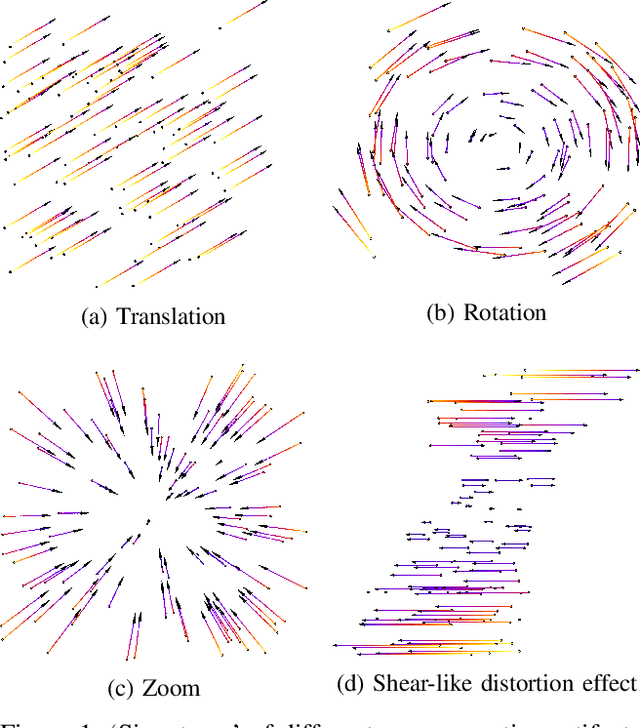
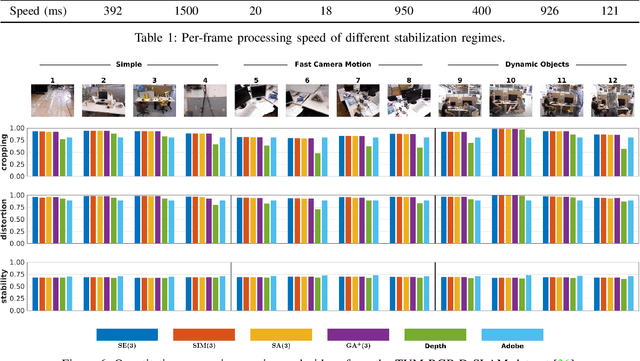
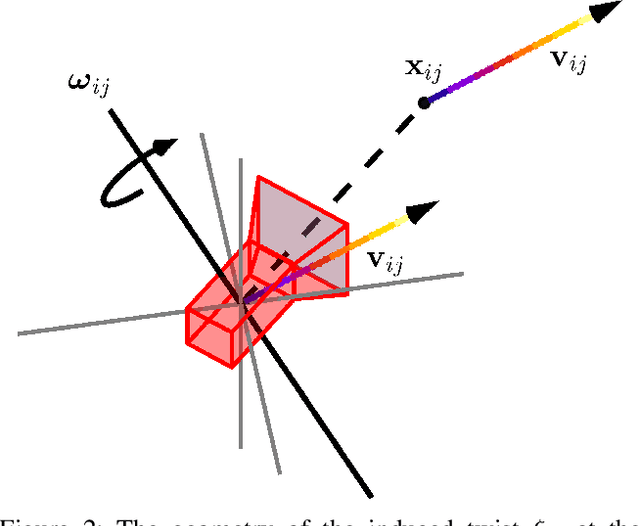
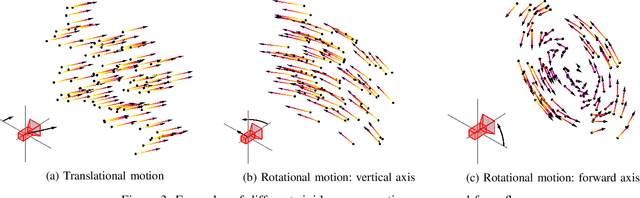
With the recent advent of methods that allow for real-time computation, dense 3D flows have become a viable basis for fast camera motion estimation. Most importantly, dense flows are more robust than the sparse feature matching techniques used by existing 3D stabilization methods, able to better handle large camera displacements and occlusions similar to those often found in consumer videos. Here we introduce a framework for 3D video stabilization that relies on dense scene flow alone. The foundation of this approach is a novel camera motion model that allows for real-world camera poses to be recovered directly from 3D motion fields. Moreover, this model can be extended to describe certain types of non-rigid artifacts that are commonly found in videos, such as those resulting from zooms. This framework gives rise to several robust regimes that produce high-quality stabilization of the kind achieved by prior full 3D methods while avoiding the fragility typically present in feature-based approaches. As an added benefit, our framework is fast: the simplicity of our motion model and efficient flow calculations combine to enable stabilization at a high frame rate.