 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling View Synthesis Transformers
Feb 24, 2026Geometry-free view synthesis transformers have recently achieved state-of-the-art performance in Novel View Synthesis (NVS), outperforming traditional approaches that rely on explicit geometry modeling. Yet the factors governing their scaling with compute remain unclear. We present a systematic study of scaling laws for view synthesis transformers and derive design principles for training compute-optimal NVS models. Contrary to prior findings, we show that encoder-decoder architectures can be compute-optimal; we trace earlier negative results to suboptimal architectural choices and comparisons across unequal training compute budgets. Across several compute levels, we demonstrate that our encoder-decoder architecture, which we call the Scalable View Synthesis Model (SVSM), scales as effectively as decoder-only models, achieves a superior performance-compute Pareto frontier, and surpasses the previous state-of-the-art on real-world NVS benchmarks with substantially reduced training compute.
* Project page: https://www.evn.kim/research/svsm
Neural Isometries: Taming Transformations for Equivariant ML
May 29, 2024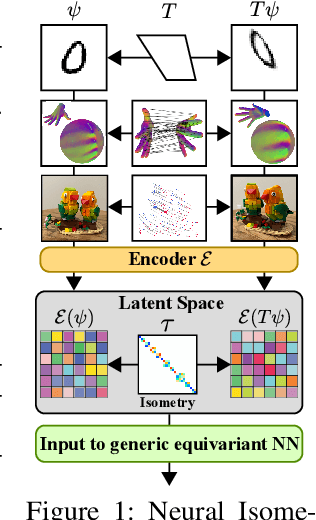

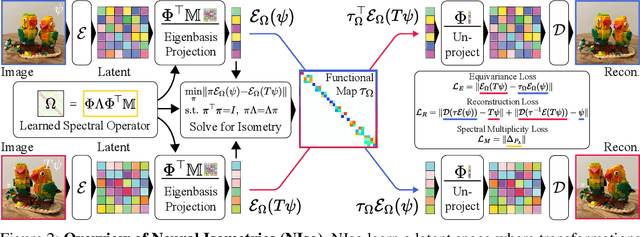

Real-world geometry and 3D vision tasks are replete with challenging symmetries that defy tractable analytical expression. In this paper, we introduce Neural Isometries, an autoencoder framework which learns to map the observation space to a general-purpose latent space wherein encodings are related by isometries whenever their corresponding observations are geometrically related in world space. Specifically, we regularize the latent space such that maps between encodings preserve a learned inner product and commute with a learned functional operator, in the same manner as rigid-body transformations commute with the Laplacian. This approach forms an effective backbone for self-supervised representation learning, and we demonstrate that a simple off-the-shelf equivariant network operating in the pre-trained latent space can achieve results on par with meticulously-engineered, handcrafted networks designed to handle complex, nonlinear symmetries. Furthermore, isometric maps capture information about the respective transformations in world space, and we show that this allows us to regress camera poses directly from the coefficients of the maps between encodings of adjacent views of a scene.
Single Mesh Diffusion Models with Field Latents for Texture Generation
Dec 14, 2023



We introduce a framework for intrinsic latent diffusion models operating directly on the surfaces of 3D shapes, with the goal of synthesizing high-quality textures. Our approach is underpinned by two contributions: field latents, a latent representation encoding textures as discrete vector fields on the mesh vertices, and field latent diffusion models, which learn to denoise a diffusion process in the learned latent space on the surface. We consider a single-textured-mesh paradigm, where our models are trained to generate variations of a given texture on a mesh. We show the synthesized textures are of superior fidelity compared those from existing single-textured-mesh generative models. Our models can also be adapted for user-controlled editing tasks such as inpainting and label-guided generation. The efficacy of our approach is due in part to the equivariance of our proposed framework under isometries, allowing our models to seamlessly reproduce details across locally similar regions and opening the door to a notion of generative texture transfer.
Möbius Convolutions for Spherical CNNs
Jan 28, 2022
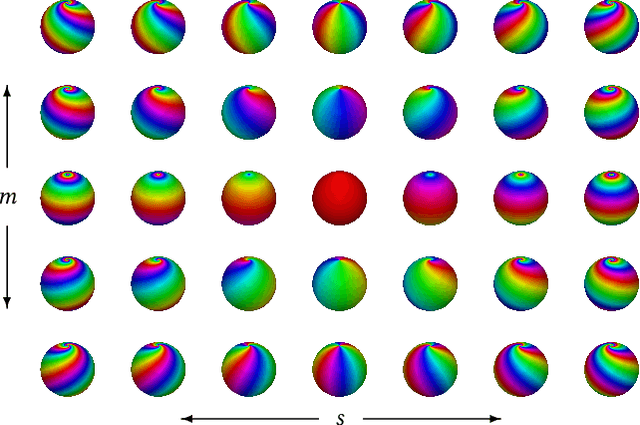

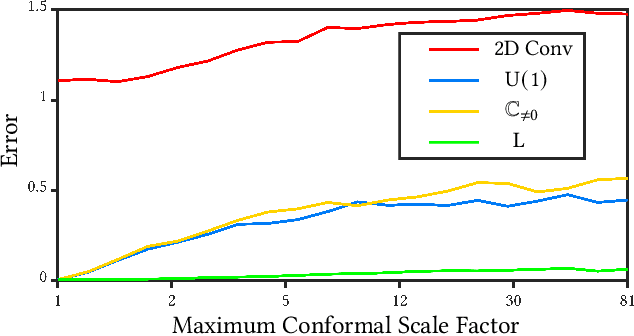
M\"{o}bius transformations play an important role in both geometry and spherical image processing -- they are the group of conformal automorphisms of 2D surfaces and the spherical equivalent of homographies. Here we present a novel, M\"{o}bius-equivariant spherical convolution operator which we call M\"{o}bius convolution, and with it, develop the foundations for M\"{o}bius-equivariant spherical CNNs. Our approach is based on a simple observation: to achieve equivariance, we only need to consider the lower-dimensional subgroup which transforms the positions of points as seen in the frames of their neighbors. To efficiently compute M\"{o}bius convolutions at scale we derive an approximation of the action of the transformations on spherical filters, allowing us to compute our convolutions in the spectral domain with the fast Spherical Harmonic Transform. The resulting framework is both flexible and descriptive, and we demonstrate its utility by achieving promising results in both shape classification and image segmentation tasks.
Field Convolutions for Surface CNNs
Apr 08, 2021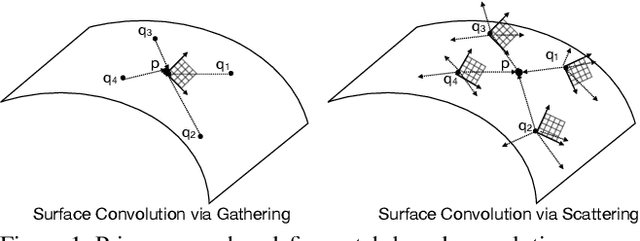

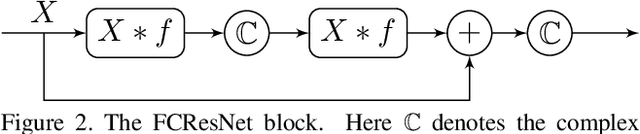

We present a novel surface convolution operator acting on vector fields that is based on a simple observation: instead of combining neighboring features with respect to a single coordinate parameterization defined at a given point, we have every neighbor describe the position of the point within its own coordinate frame. This formulation combines intrinsic spatial convolution with parallel transport in a scattering operation while placing no constraints on the filters themselves, providing a definition of convolution that commutes with the action of isometries, has increased descriptive potential, and is robust to noise and other nuisance factors. The result is a rich notion of convolution which we call field convolution, well-suited for CNNs on surfaces. Field convolutions are flexible and straight-forward to implement, and their highly discriminating nature has cascading effects throughout the learning pipeline. Using simple networks constructed from residual field convolution blocks, we achieve state-of-the-art results on standard benchmarks in fundamental geometry processing tasks, such as shape classification, segmentation, correspondence, and sparse matching.
Efficient Spatially Adaptive Convolution and Correlation
Jun 23, 2020
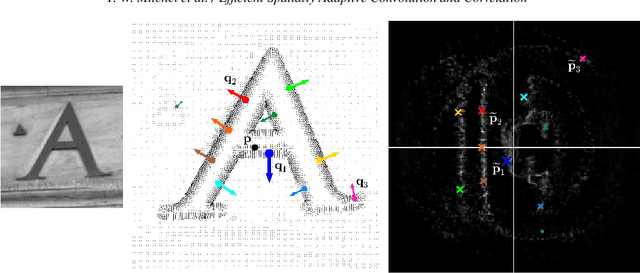

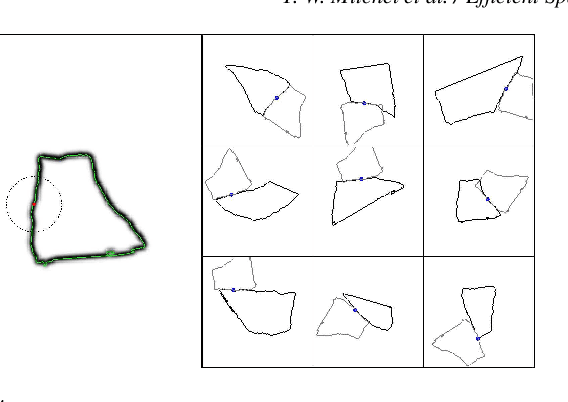
Fast methods for convolution and correlation underlie a variety of applications in computer vision and graphics, including efficient filtering, analysis, and simulation. However, standard convolution and correlation are inherently limited to fixed filters: spatial adaptation is impossible without sacrificing efficient computation. In early work, Freeman and Adelson have shown how steerable filters can address this limitation, providing a way for rotating the filter as it is passed over the signal. In this work, we provide a general, representation-theoretic, framework that allows for spatially varying linear transformations to be applied to the filter. This framework allows for efficient implementation of extended convolution and correlation for transformation groups such as rotation (in 2D and 3D) and scale, and provides a new interpretation for previous methods including steerable filters and the generalized Hough transform. We present applications to pattern matching, image feature description, vector field visualization, and adaptive image filtering.
Quotienting Impertinent Camera Kinematics for 3D Video Stabilization
Mar 21, 2019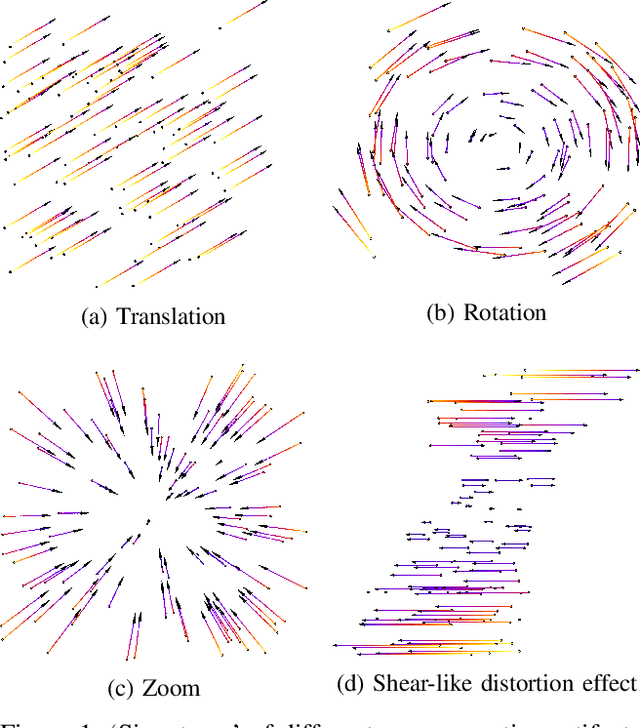
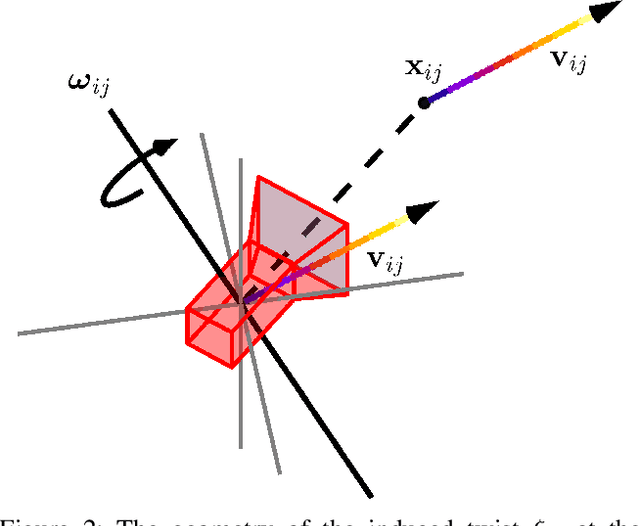
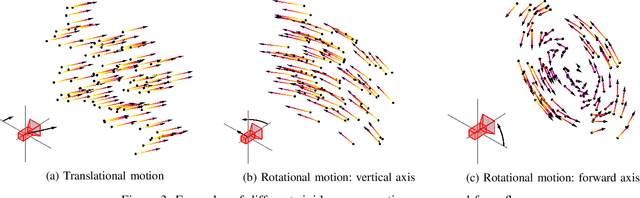
With the recent advent of methods that allow for real-time computation, dense 3D flows have become a viable basis for fast camera motion estimation. Most importantly, dense flows are more robust than the sparse feature matching techniques used by existing 3D stabilization methods, able to better handle large camera displacements and occlusions similar to those often found in consumer videos. Here we introduce a framework for 3D video stabilization that relies on dense scene flow alone. The foundation of this approach is a novel camera motion model that allows for real-world camera poses to be recovered directly from 3D motion fields. Moreover, this model can be extended to describe certain types of non-rigid artifacts that are commonly found in videos, such as those resulting from zooms. This framework gives rise to several robust regimes that produce high-quality stabilization of the kind achieved by prior full 3D methods while avoiding the fragility typically present in feature-based approaches. As an added benefit, our framework is fast: the simplicity of our motion model and efficient flow calculations combine to enable stabilization at a high frame rate.
Signal Alignment for Humanoid Skeletons via the Globally Optimal Reparameterization Algorithm
Jul 20, 2018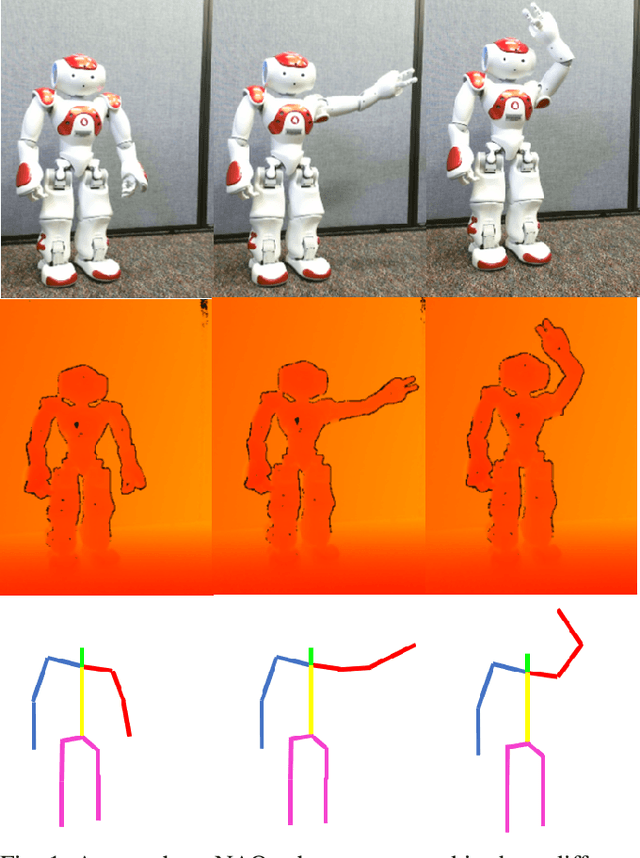
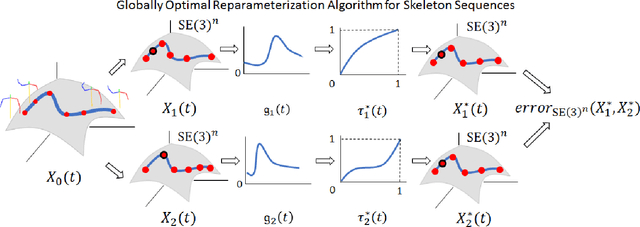
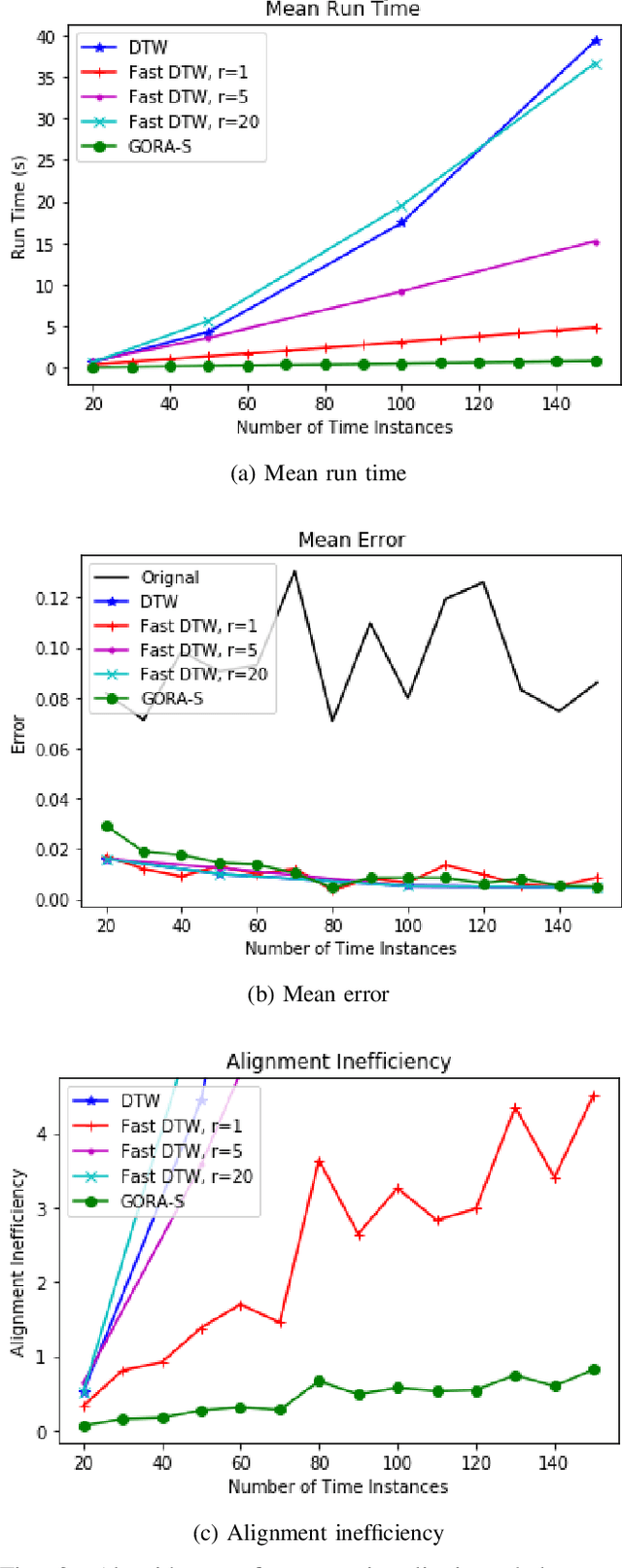
The general ability to analyze and classify the 3D kinematics of the human form is an essential step in the development of socially adept humanoid robots. A variety of different types of signals can be used by machines to represent and characterize actions such as RGB videos, infrared maps, and optical flow. In particular, skeleton sequences provide a natural 3D kinematic description of human motions and can be acquired in real time using RGB+D cameras. Moreover, skeleton sequences are generalizable to characterize the motions of both humans and humanoid robots. The Globally Optimal Reparameterization Algorithm (GORA) is a novel, recently proposed algorithm for signal alignment in which signals are reparameterized to a globally optimal universal standard timescale (UST). Here, we introduce a variant of GORA for humanoid action recognition with skeleton sequences, which we call GORA-S. We briefly review the algorithm's mathematical foundations and contextualize them in the problem of action recognition with skeleton sequences. Subsequently, we introduce GORA-S and discuss parameters and numerical techniques for its effective implementation. We then compare its performance with that of the DTW and FastDTW algorithms, in terms of computational efficiency and accuracy in matching skeletons. Our results show that GORA-S attains a complexity that is significantly less than that of any tested DTW method. In addition, it displays a favorable balance between speed and accuracy that remains invariant under changes in skeleton sampling frequency, lending it a degree of versatility that could make it well-suited for a variety of action recognition tasks.