 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge
Feb 16, 2024



Despite the remarkable strides of Large Language Models (LLMs) in various fields, the wide applications of LLMs on edge devices are limited due to their massive parameters and computations. To address this, quantization is commonly adopted to generate lightweight LLMs with efficient computations and fast inference. However, Post-Training Quantization (PTQ) methods dramatically degrade in quality when quantizing weights, activations, and KV cache together to below 8 bits. Besides, many Quantization-Aware Training (QAT) works quantize model weights, leaving the activations untouched, which do not fully exploit the potential of quantization for inference acceleration on the edge. In this paper, we propose EdgeQAT, the Entropy and Distribution Guided QAT for the optimization of lightweight LLMs to achieve inference acceleration on Edge devices. We first identify that the performance drop of quantization primarily stems from the information distortion in quantized attention maps, demonstrated by the different distributions in quantized query and key of the self-attention mechanism. Then, the entropy and distribution guided QAT is proposed to mitigate the information distortion. Moreover, we design a token importance-aware adaptive method to dynamically quantize the tokens with different bit widths for further optimization and acceleration. Our extensive experiments verify the substantial improvements with our framework across various datasets. Furthermore, we achieve an on-device speedup of up to 2.37x compared with its FP16 counterparts across multiple edge devices, signaling a groundbreaking advancement.
Quadrupedal Locomotion Control On Inclined Surfaces Using Collocation Method
Dec 14, 2023Inspired by Chukars wing-assisted incline running (WAIR), in this work, we employ a high-fidelity model of our Husky Carbon quadrupedal-legged robot to walk over steep slopes of up to 45 degrees. Chukars use the aerodynamic forces generated by their flapping wings to manipulate ground contact forces and traverse steep slopes and even overhangs. By exploiting the thrusters on Husky, we employed a collocation approach to rapidly resolving the joint and thruster actions. Our approach uses a polynomial approximation of the reduced-order dynamics of Husky, called HROM, to quickly and efficiently find optimal control actions that permit high-slope walking without violating friction cone conditions.
Auto-ViT-Acc: An FPGA-Aware Automatic Acceleration Framework for Vision Transformer with Mixed-Scheme Quantization
Aug 10, 2022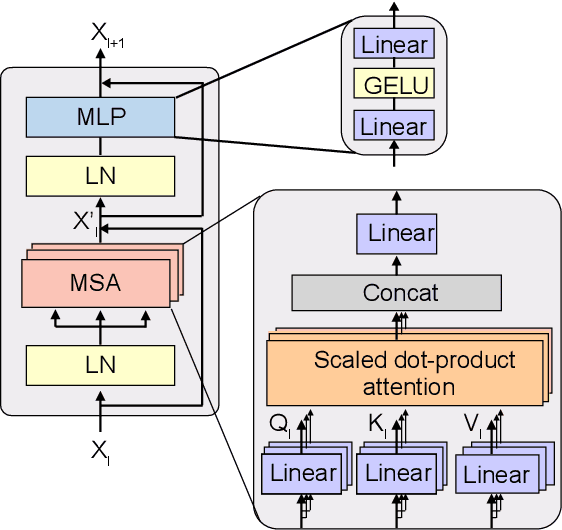
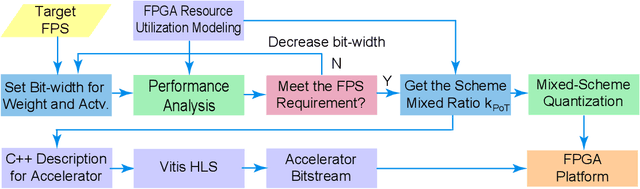
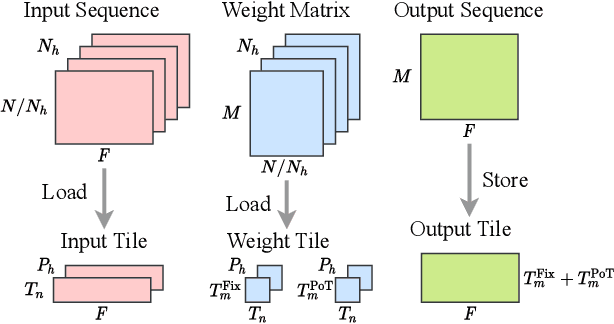
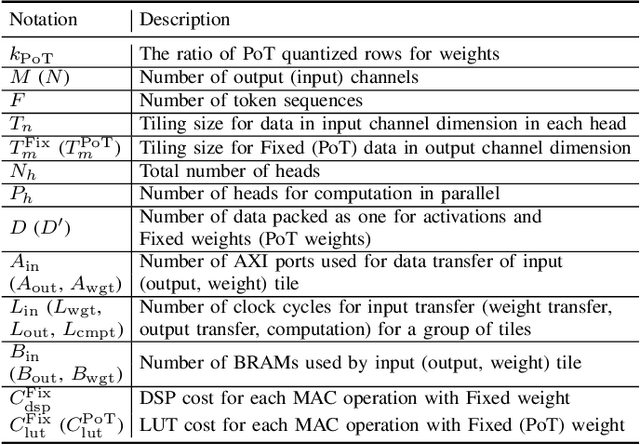
Vision transformers (ViTs) are emerging with significantly improved accuracy in computer vision tasks. However, their complex architecture and enormous computation/storage demand impose urgent needs for new hardware accelerator design methodology. This work proposes an FPGA-aware automatic ViT acceleration framework based on the proposed mixed-scheme quantization. To the best of our knowledge, this is the first FPGA-based ViT acceleration framework exploring model quantization. Compared with state-of-the-art ViT quantization work (algorithmic approach only without hardware acceleration), our quantization achieves 0.47% to 1.36% higher Top-1 accuracy under the same bit-width. Compared with the 32-bit floating-point baseline FPGA accelerator, our accelerator achieves around 5.6x improvement on the frame rate (i.e., 56.8 FPS vs. 10.0 FPS) with 0.71% accuracy drop on ImageNet dataset for DeiT-base.
Scaling Neural Network Performance through Customized Hardware Architectures on Reconfigurable Logic
Jun 26, 2018



Convolutional Neural Networks have dramatically improved in recent years, surpassing human accuracy on certain problems and performance exceeding that of traditional computer vision algorithms. While the compute pattern in itself is relatively simple, significant compute and memory challenges remain as CNNs may contain millions of floating-point parameters and require billions of floating-point operations to process a single image. These computational requirements, combined with storage footprints that exceed typical cache sizes, pose a significant performance and power challenge for modern compute architectures. One of the promising opportunities to scale performance and power efficiency is leveraging reduced precision representations for all activations and weights as this allows to scale compute capabilities, reduce weight and feature map buffering requirements as well as energy consumption. While a small reduction in accuracy is encountered, these Quantized Neural Networks have been shown to achieve state-of-the-art accuracy on standard benchmark datasets, such as MNIST, CIFAR-10, SVHN and even ImageNet, and thus provide highly attractive design trade-offs. Current research has focused mainly on the implementation of extreme variants with full binarization of weights and or activations, as well typically smaller input images. Within this paper, we investigate the scalability of dataflow architectures with respect to supporting various precisions for both weights and activations, larger image dimensions, and increasing numbers of feature map channels. Key contributions are a formalized approach to understanding the scalability of the existing hardware architecture with cost models and a performance prediction as a function of the target device size. We provide validating experimental results for an ImageNet classification on a server-class platform, namely the AWS F1 node.