 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Group Rules with AI: Human-AI Collaboration in WhatsApp Moderation
May 12, 2026WhatsApp is one of the most widely used messaging platforms globally, with billions of users sharing information in private groups. Yet, it offers little infrastructure to support moderation and group governance. In the absence of platform-level oversight, group admins bear the responsibility of governing group behavior. In this paper, we explore how WhatsApp group admins collaborate with AI tools to create, enforce, and maintain group rules. Drawing on a two-phase speculative design study with 20 admins in India, we examine how participants interacted with an AI assistant (Meta AI) to co-create rules and responded to a series of probes illustrating AI-assisted moderation features. Our findings show that while admins appreciated the AI's ability to surface overlooked rules and reduce their moderation burden, they were highly sensitive to issues of relational trust, data privacy, tone, and social context. We identify how group type and admin style shaped their willingness to delegate authority, and surface the limitations of current chatbot interfaces in supporting collaborative rule-making. We conclude with design implications for building moderation tools that center human judgment, relational nuance, contextual adaptability, and collective governance.
Fluent but Culturally Distant: Can Regional Training Teach Cultural Understanding?
May 25, 2025Large language models (LLMs) are used around the world but exhibit Western cultural tendencies. To address this cultural misalignment, many countries have begun developing "regional" LLMs tailored to local communities. Yet it remains unclear whether these models merely speak the language of their users or also reflect their cultural values and practices. Using India as a case study, we evaluate five Indic and five global LLMs along two key dimensions: values (via the Inglehart-Welzel map and GlobalOpinionQA) and practices (via CulturalBench and NormAd). Across all four tasks, we find that Indic models do not align more closely with Indian cultural norms than global models. In fact, an average American person is a better proxy for Indian cultural values than any Indic model. Even prompting strategies fail to meaningfully improve alignment. Ablations show that regional fine-tuning does not enhance cultural competence and may in fact hurt it by impeding recall of existing knowledge. We trace this failure to the scarcity of high-quality, untranslated, and culturally grounded pretraining and fine-tuning data. Our study positions cultural evaluation as a first-class requirement alongside multilingual benchmarks and offers a reusable methodology for developers. We call for deeper investments in culturally representative data to build and evaluate truly sovereign LLMs.
Think Outside the Data: Colonial Biases and Systemic Issues in Automated Moderation Pipelines for Low-Resource Languages
Jan 23, 2025
Most social media users come from non-English speaking countries in the Global South. Despite the widespread prevalence of harmful content in these regions, current moderation systems repeatedly struggle in low-resource languages spoken there. In this work, we examine the challenges AI researchers and practitioners face when building moderation tools for low-resource languages. We conducted semi-structured interviews with 22 AI researchers and practitioners specializing in automatic detection of harmful content in four diverse low-resource languages from the Global South. These are: Tamil from South Asia, Swahili from East Africa, Maghrebi Arabic from North Africa, and Quechua from South America. Our findings reveal that social media companies' restrictions on researchers' access to data exacerbate the historical marginalization of these languages, which have long lacked datasets for studying online harms. Moreover, common preprocessing techniques and language models, predominantly designed for data-rich English, fail to account for the linguistic complexity of low-resource languages. This leads to critical errors when moderating content in Tamil, Swahili, Arabic, and Quechua, which are morphologically richer than English. Based on our findings, we establish that the precarities in current moderation pipelines are rooted in deep systemic inequities and continue to reinforce historical power imbalances. We conclude by discussing multi-stakeholder approaches to improve moderation for low-resource languages.
KAHANI: Culturally-Nuanced Visual Storytelling Pipeline for Non-Western Cultures
Oct 28, 2024



Large Language Models (LLMs) and Text-To-Image (T2I) models have demonstrated the ability to generate compelling text and visual stories. However, their outputs are predominantly aligned with the sensibilities of the Global North, often resulting in an outsider's gaze on other cultures. As a result, non-Western communities have to put extra effort into generating culturally specific stories. To address this challenge, we developed a visual storytelling pipeline called KAHANI that generates culturally grounded visual stories for non-Western cultures. Our pipeline leverages off-the-shelf models GPT-4 Turbo and Stable Diffusion XL (SDXL). By using Chain of Thought (CoT) and T2I prompting techniques, we capture the cultural context from user's prompt and generate vivid descriptions of the characters and scene compositions. To evaluate the effectiveness of KAHANI, we conducted a comparative user study with ChatGPT-4 (with DALL-E3) in which participants from different regions of India compared the cultural relevance of stories generated by the two tools. Results from the qualitative and quantitative analysis performed on the user study showed that KAHANI was able to capture and incorporate more Culturally Specific Items (CSIs) compared to ChatGPT-4. In terms of both its cultural competence and visual story generation quality, our pipeline outperformed ChatGPT-4 in 27 out of the 36 comparisons.
How Toxicity Classifiers and Large Language Models Respond to Ableism
Oct 04, 2024


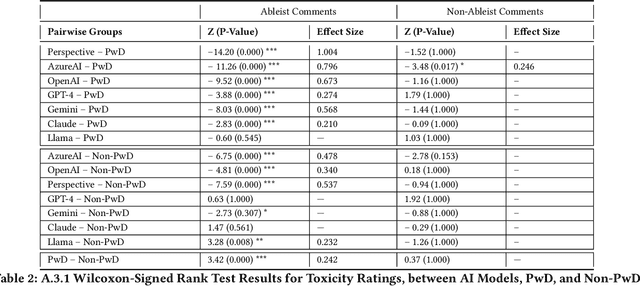
People with disabilities (PwD) regularly encounter ableist hate and microaggressions online. While online platforms use machine learning models to moderate online harm, there is little research investigating how these models interact with ableism. In this paper, we curated a dataset of 100 social media comments targeted towards PwD, and recruited 160 participants to rate and explain how toxic and ableist these comments were. We then prompted state-of-the art toxicity classifiers (TCs) and large language models (LLMs) to rate and explain the harm. Our analysis revealed that TCs and LLMs rated toxicity significantly lower than PwD, but LLMs rated ableism generally on par with PwD. However, ableism explanations by LLMs overlooked emotional harm, and lacked specificity and acknowledgement of context, important facets of PwD explanations. Going forward, we discuss challenges in designing disability-aware toxicity classifiers, and advocate for the shift from ableism detection to ableism interpretation and explanation.
AI Suggestions Homogenize Writing Toward Western Styles and Diminish Cultural Nuances
Sep 17, 2024



Large language models (LLMs) are being increasingly integrated into everyday products and services, such as coding tools and writing assistants. As these embedded AI applications are deployed globally, there is a growing concern that the AI models underlying these applications prioritize Western values. This paper investigates what happens when a Western-centric AI model provides writing suggestions to users from a different cultural background. We conducted a cross-cultural controlled experiment with 118 participants from India and the United States who completed culturally grounded writing tasks with and without AI suggestions. Our analysis reveals that AI provided greater efficiency gains for Americans compared to Indians. Moreover, AI suggestions led Indian participants to adopt Western writing styles, altering not just what is written but also how it is written. These findings show that Western-centric AI models homogenize writing toward Western norms, diminishing nuances that differentiate cultural expression.
Akal Badi ya Bias: An Exploratory Study of Gender Bias in Hindi Language Technology
May 10, 2024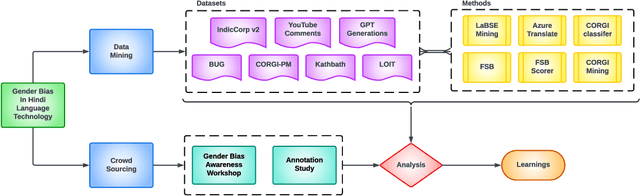

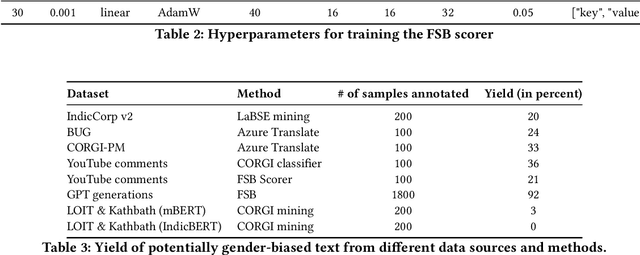
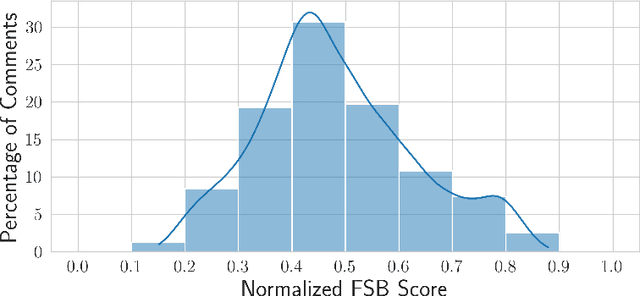
Existing research in measuring and mitigating gender bias predominantly centers on English, overlooking the intricate challenges posed by non-English languages and the Global South. This paper presents the first comprehensive study delving into the nuanced landscape of gender bias in Hindi, the third most spoken language globally. Our study employs diverse mining techniques, computational models, field studies and sheds light on the limitations of current methodologies. Given the challenges faced with mining gender biased statements in Hindi using existing methods, we conducted field studies to bootstrap the collection of such sentences. Through field studies involving rural and low-income community women, we uncover diverse perceptions of gender bias, underscoring the necessity for context-specific approaches. This paper advocates for a community-centric research design, amplifying voices often marginalized in previous studies. Our findings not only contribute to the understanding of gender bias in Hindi but also establish a foundation for further exploration of Indic languages. By exploring the intricacies of this understudied context, we call for thoughtful engagement with gender bias, promoting inclusivity and equity in linguistic and cultural contexts beyond the Global North.