 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoNER: Few shot Incremental Learning for Named Entity Recognition using Prototypical Networks
Paper and Code
Oct 03, 2023

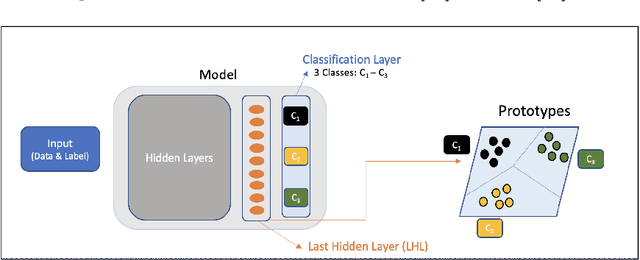
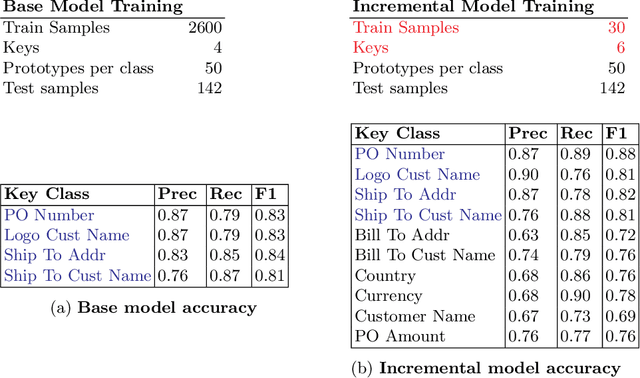
Key value pair (KVP) extraction or Named Entity Recognition(NER) from visually rich documents has been an active area of research in document understanding and data extraction domain. Several transformer based models such as LayoutLMv2, LayoutLMv3, and LiLT have emerged achieving state of the art results. However, addition of even a single new class to the existing model requires (a) re-annotation of entire training dataset to include this new class and (b) retraining the model again. Both of these issues really slow down the deployment of updated model. \\ We present \textbf{ProtoNER}: Prototypical Network based end-to-end KVP extraction model that allows addition of new classes to an existing model while requiring minimal number of newly annotated training samples. The key contributions of our model are: (1) No dependency on dataset used for initial training of the model, which alleviates the need to retain original training dataset for longer duration as well as data re-annotation which is very time consuming task, (2) No intermediate synthetic data generation which tends to add noise and results in model's performance degradation, and (3) Hybrid loss function which allows model to retain knowledge about older classes as well as learn about newly added classes.\\ Experimental results show that ProtoNER finetuned with just 30 samples is able to achieve similar results for the newly added classes as that of regular model finetuned with 2600 samples.