 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Resources and Technologies for Non-Scheduled and Endangered Indian Languages
Apr 06, 2022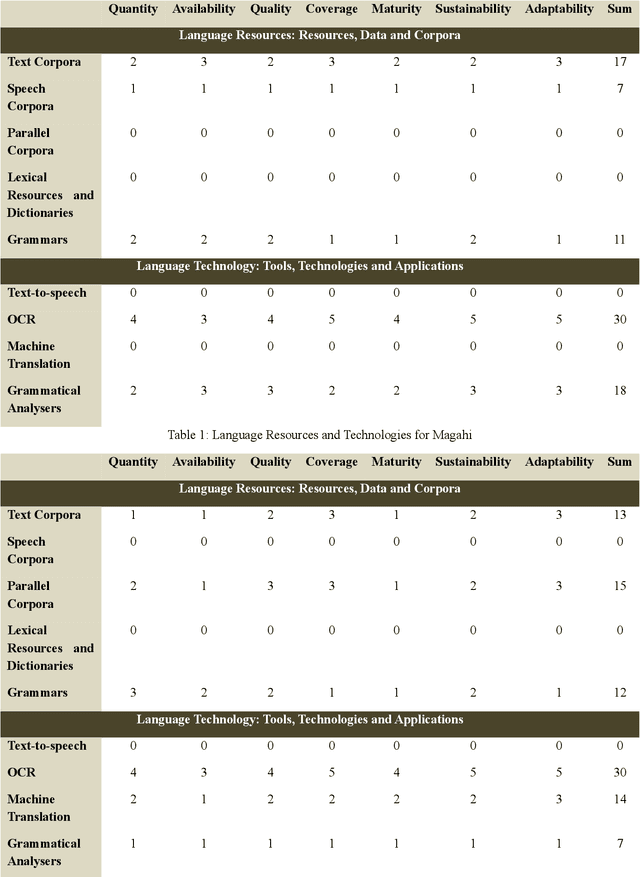
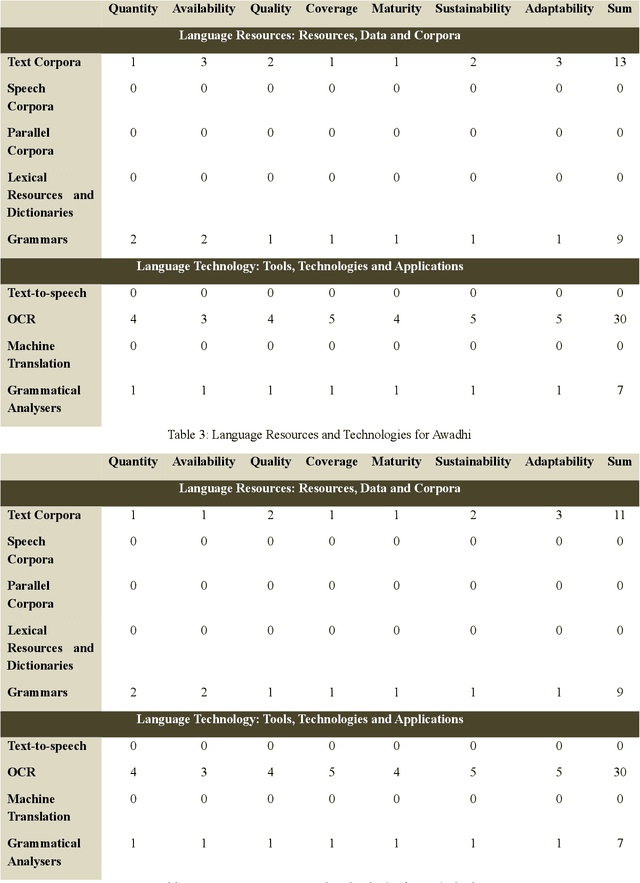
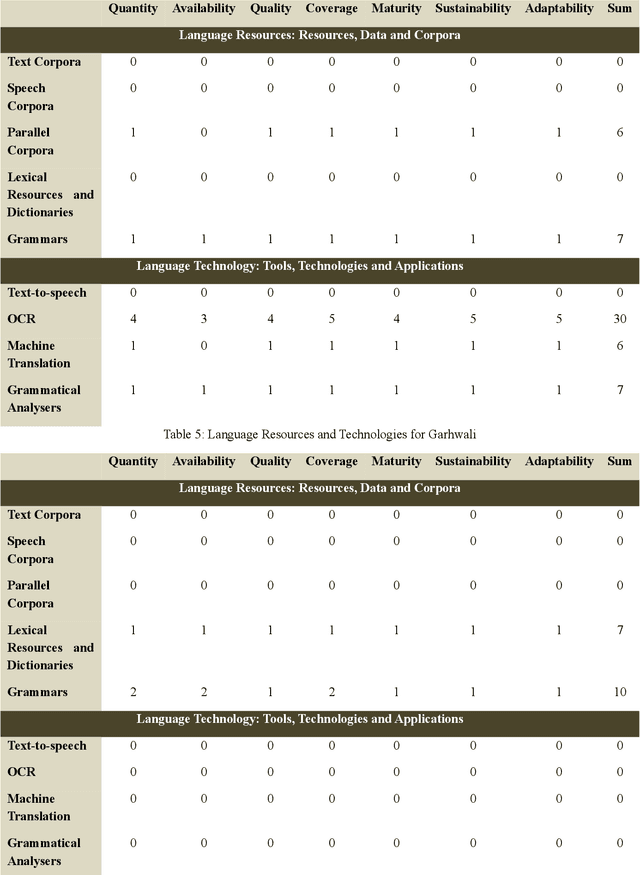
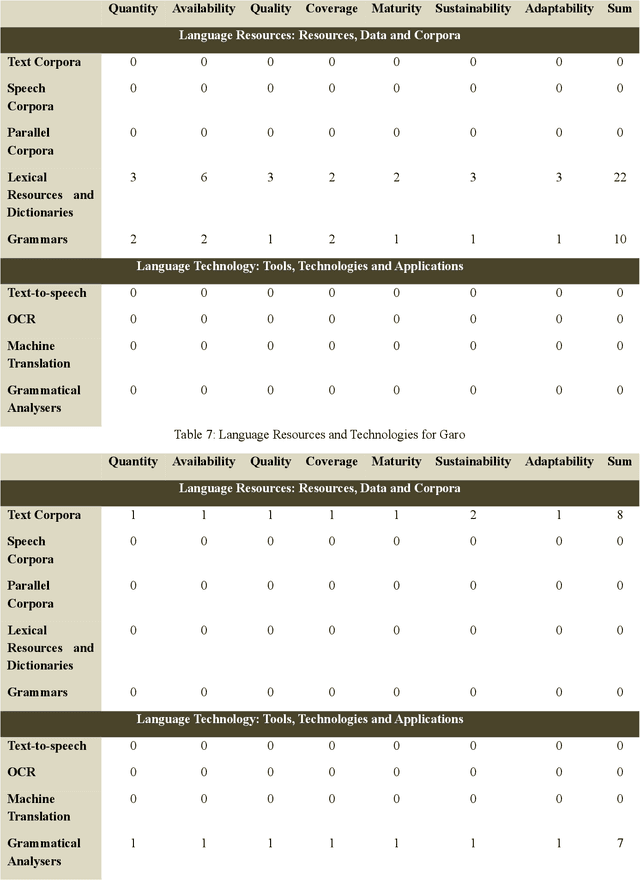
In the present paper, we will present a survey of the language resources and technologies available for the non-scheduled and endangered languages of India. While there have been different estimates from different sources about the number of languages in India, it could be assumed that there are more than 1,000 languages currently being spoken in India. However barring some of the 22 languages included in the 8th Schedule of the Indian Constitution (called the scheduled languages), there is hardly any substantial resource or technology available for the rest of the languages. Nonetheless there have been some individual attempts at developing resources and technologies for the different languages across the country. Of late, some financial support has also become available for the endangered languages. In this paper, we give a summary of the resources and technologies for those Indian languages which are not included in the 8th schedule of the Indian Constitution and/or which are endangered.
Aggression in Hindi and English Speech: Acoustic Correlates and Automatic Identification
Apr 06, 2022

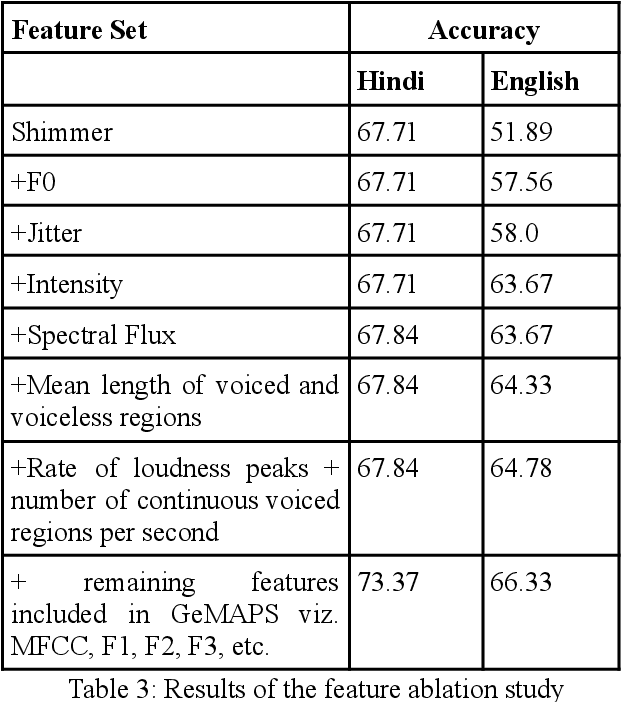

In the present paper, we will present the results of an acoustic analysis of political discourse in Hindi and discuss some of the conventionalised acoustic features of aggressive speech regularly employed by the speakers of Hindi and English. The study is based on a corpus of slightly over 10 hours of political discourse and includes debates on news channel and political speeches. Using this study, we develop two automatic classification systems for identifying aggression in English and Hindi speech, based solely on an acoustic model. The Hindi classifier, trained using 50 hours of annotated speech, and English classifier, trained using 40 hours of annotated speech, achieve a respectable accuracy of over 73% and 66% respectively. In this paper, we discuss the development of this annotated dataset, the experiments for developing the classifier and discuss the errors that it makes.
Developing a Multilingual Annotated Corpus of Misogyny and Aggression
Mar 16, 2020



In this paper, we discuss the development of a multilingual annotated corpus of misogyny and aggression in Indian English, Hindi, and Indian Bangla as part of a project on studying and automatically identifying misogyny and communalism on social media (the ComMA Project). The dataset is collected from comments on YouTube videos and currently contains a total of over 20,000 comments. The comments are annotated at two levels - aggression (overtly aggressive, covertly aggressive, and non-aggressive) and misogyny (gendered and non-gendered). We describe the process of data collection, the tagset used for annotation, and issues and challenges faced during the process of annotation. Finally, we discuss the results of the baseline experiments conducted to develop a classifier for misogyny in the three languages.
Automatic Identification of Closely-related Indian Languages: Resources and Experiments
Mar 26, 2018
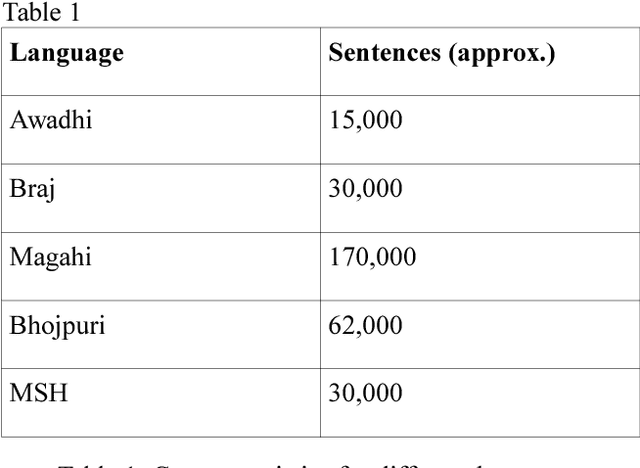
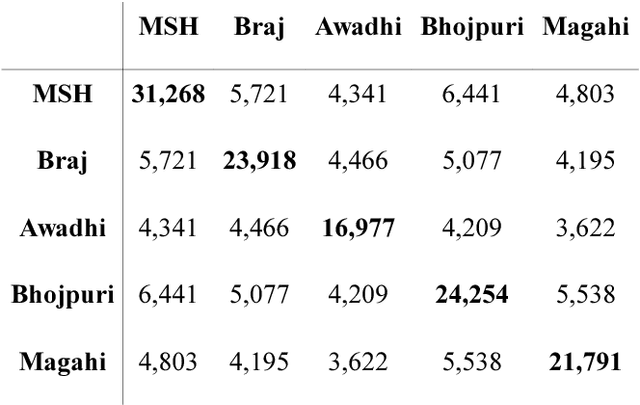
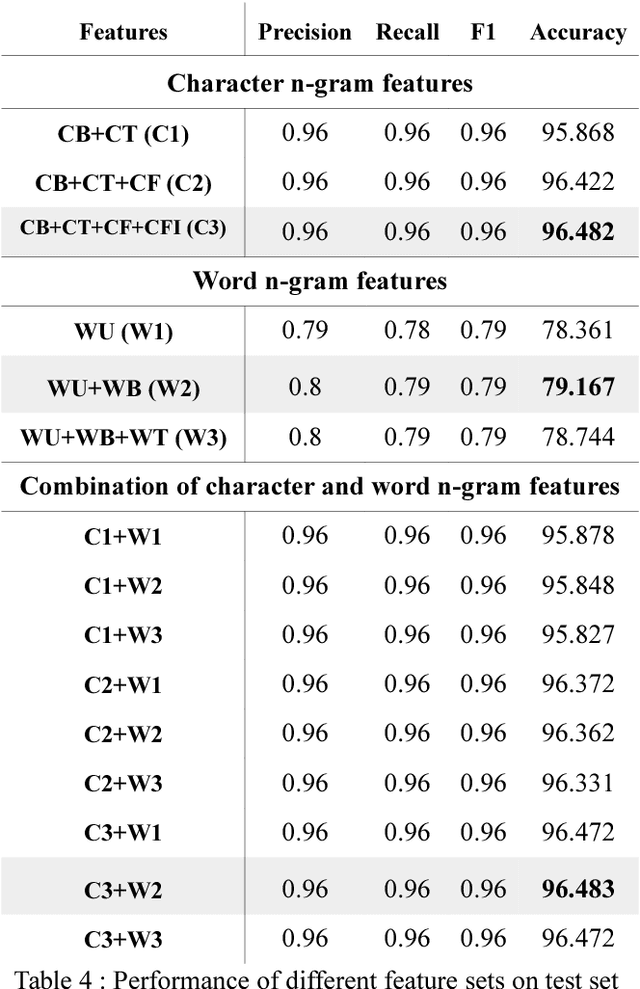
In this paper, we discuss an attempt to develop an automatic language identification system for 5 closely-related Indo-Aryan languages of India, Awadhi, Bhojpuri, Braj, Hindi and Magahi. We have compiled a comparable corpora of varying length for these languages from various resources. We discuss the method of creation of these corpora in detail. Using these corpora, a language identification system was developed, which currently gives state of the art accuracy of 96.48\%. We also used these corpora to study the similarity between the 5 languages at the lexical level, which is the first data-based study of the extent of closeness of these languages.