Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Identification of Closely-related Indian Languages: Resources and Experiments
Paper and Code
Mar 26, 2018
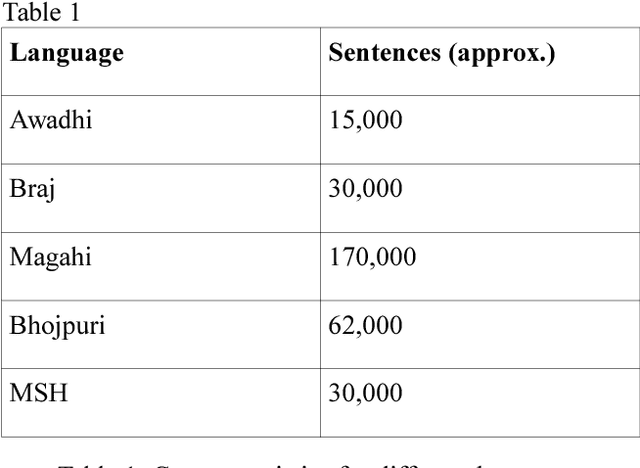
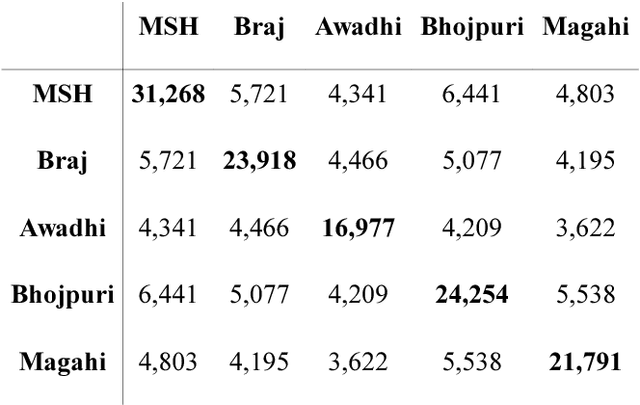
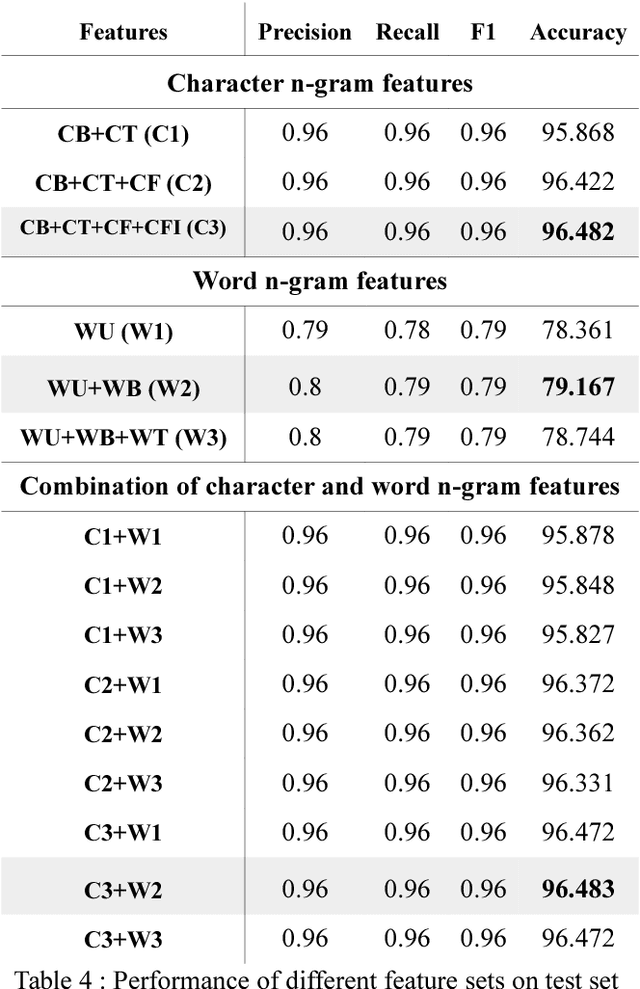
In this paper, we discuss an attempt to develop an automatic language identification system for 5 closely-related Indo-Aryan languages of India, Awadhi, Bhojpuri, Braj, Hindi and Magahi. We have compiled a comparable corpora of varying length for these languages from various resources. We discuss the method of creation of these corpora in detail. Using these corpora, a language identification system was developed, which currently gives state of the art accuracy of 96.48\%. We also used these corpora to study the similarity between the 5 languages at the lexical level, which is the first data-based study of the extent of closeness of these languages.
* Paper accepted at the 4th Workshop in Indian Languages Data and
Resources (WILDRE - 4), 11th edition of the Language Resources and Evaluation
Conference (LREC - 2018), 7-12 May 2018, Miyazaki (Japan)
View paper on