 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ComMA Dataset V0.2: Annotating Aggression and Bias in Multilingual Social Media Discourse
Nov 19, 2021
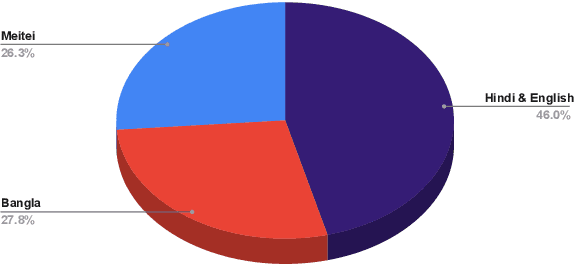
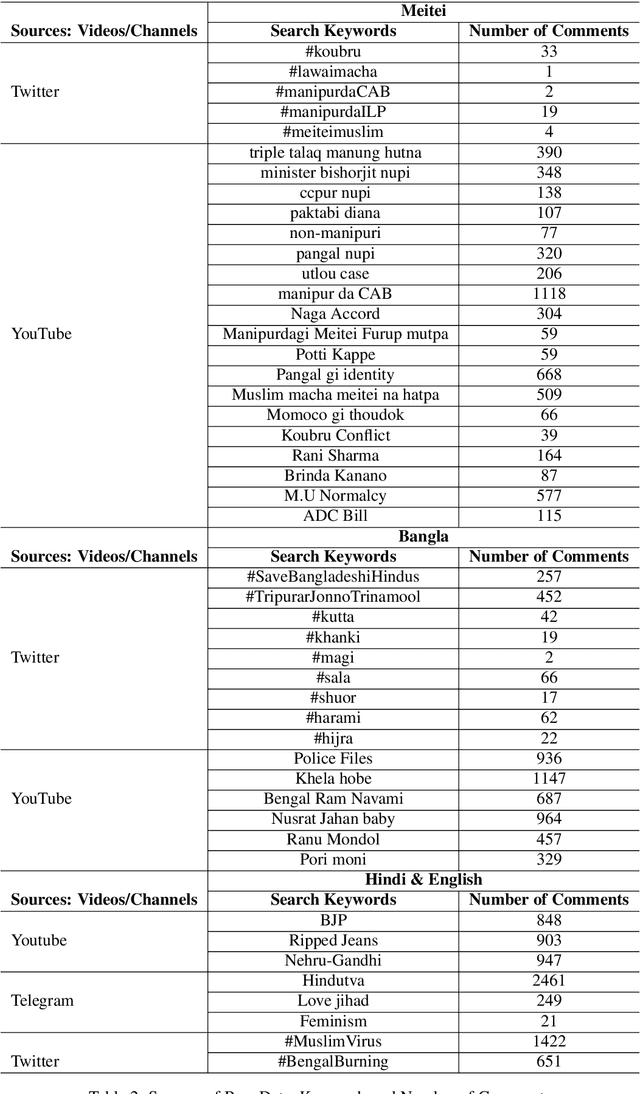

In this paper, we discuss the development of a multilingual dataset annotated with a hierarchical, fine-grained tagset marking different types of aggression and the "context" in which they occur. The context, here, is defined by the conversational thread in which a specific comment occurs and also the "type" of discursive role that the comment is performing with respect to the previous comment. The initial dataset, being discussed here (and made available as part of the ComMA@ICON shared task), consists of a total 15,000 annotated comments in four languages - Meitei, Bangla, Hindi, and Indian English - collected from various social media platforms such as YouTube, Facebook, Twitter and Telegram. As is usual on social media websites, a large number of these comments are multilingual, mostly code-mixed with English. The paper gives a detailed description of the tagset being used for annotation and also the process of developing a multi-label, fine-grained tagset that can be used for marking comments with aggression and bias of various kinds including gender bias, religious intolerance (called communal bias in the tagset), class/caste bias and ethnic/racial bias. We also define and discuss the tags that have been used for marking different the discursive role being performed through the comments, such as attack, defend, etc. We also present a statistical analysis of the dataset as well as results of our baseline experiments with developing an automatic aggression identification system using the dataset developed.
Developing a Multilingual Annotated Corpus of Misogyny and Aggression
Mar 16, 2020



In this paper, we discuss the development of a multilingual annotated corpus of misogyny and aggression in Indian English, Hindi, and Indian Bangla as part of a project on studying and automatically identifying misogyny and communalism on social media (the ComMA Project). The dataset is collected from comments on YouTube videos and currently contains a total of over 20,000 comments. The comments are annotated at two levels - aggression (overtly aggressive, covertly aggressive, and non-aggressive) and misogyny (gendered and non-gendered). We describe the process of data collection, the tagset used for annotation, and issues and challenges faced during the process of annotation. Finally, we discuss the results of the baseline experiments conducted to develop a classifier for misogyny in the three languages.
Automatic Identification of Closely-related Indian Languages: Resources and Experiments
Mar 26, 2018
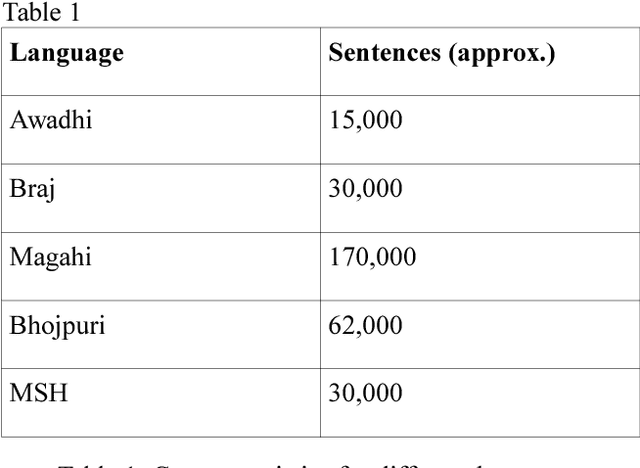
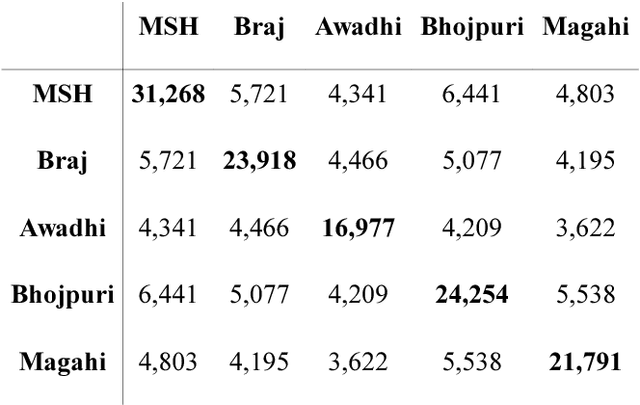
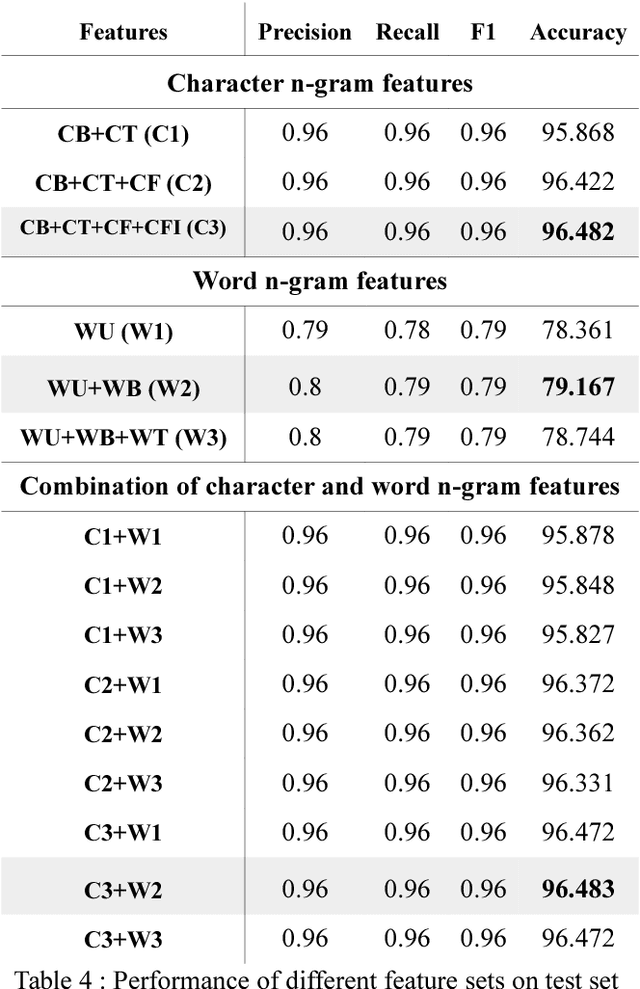
In this paper, we discuss an attempt to develop an automatic language identification system for 5 closely-related Indo-Aryan languages of India, Awadhi, Bhojpuri, Braj, Hindi and Magahi. We have compiled a comparable corpora of varying length for these languages from various resources. We discuss the method of creation of these corpora in detail. Using these corpora, a language identification system was developed, which currently gives state of the art accuracy of 96.48\%. We also used these corpora to study the similarity between the 5 languages at the lexical level, which is the first data-based study of the extent of closeness of these languages.