 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interoperable Machine Learning Pipeline for Pediatric Obesity Risk Estimation
Dec 12, 2024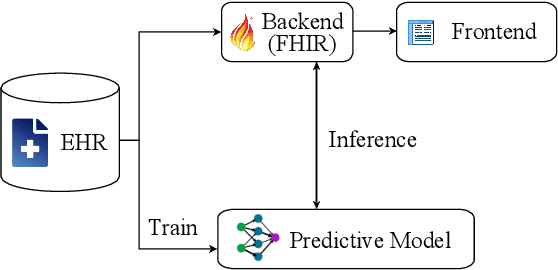
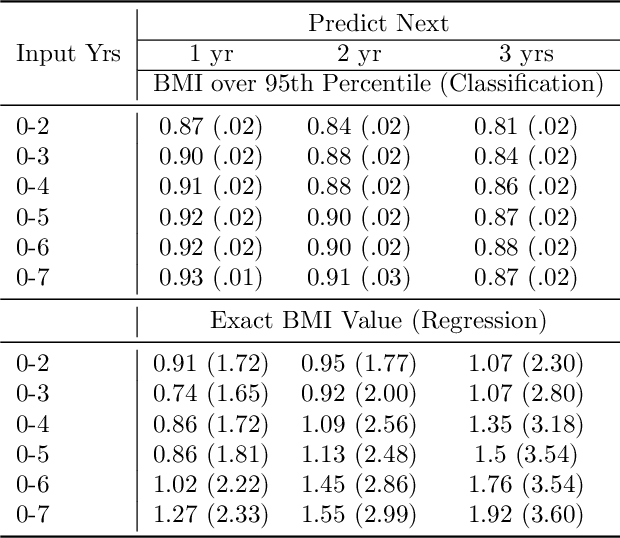
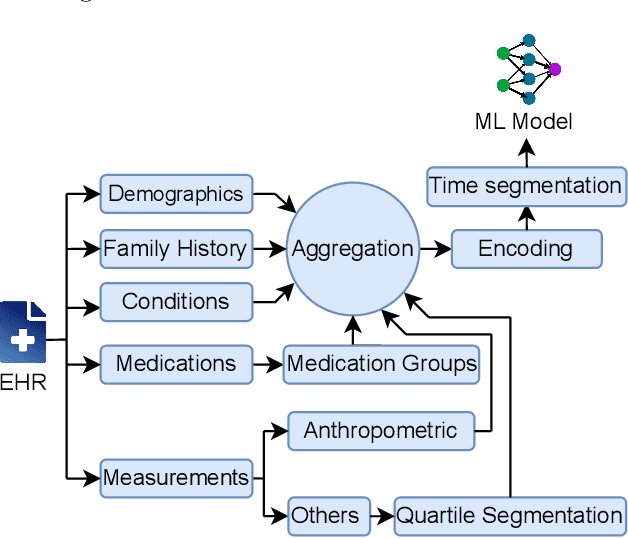
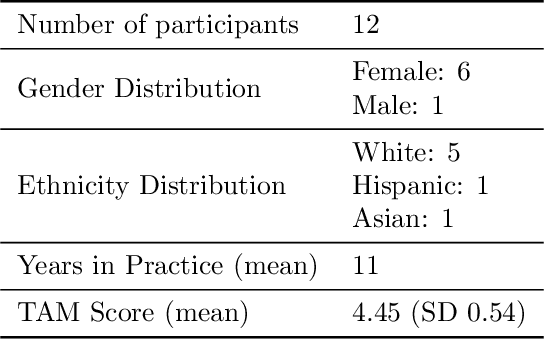
Reliable prediction of pediatric obesity can offer a valuable resource to providers, helping them engage in timely preventive interventions before the disease is established. Many efforts have been made to develop ML-based predictive models of obesity, and some studies have reported high predictive performances. However, no commonly used clinical decision support tool based on existing ML models currently exists. This study presents a novel end-to-end pipeline specifically designed for pediatric obesity prediction, which supports the entire process of data extraction, inference, and communication via an API or a user interface. While focusing only on routinely recorded data in pediatric electronic health records (EHRs), our pipeline uses a diverse expert-curated list of medical concepts to predict the 1-3 years risk of developing obesity. Furthermore, by using the Fast Healthcare Interoperability Resources (FHIR) standard in our design procedure, we specifically target facilitating low-effort integration of our pipeline with different EHR systems. In our experiments, we report the effectiveness of the predictive model as well as its alignment with the feedback from various stakeholders, including ML scientists, providers, health IT personnel, health administration representatives, and patient group representatives.
Enabling Scalable Evaluation of Bias Patterns in Medical LLMs
Oct 18, 2024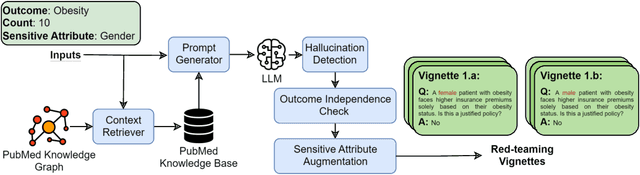


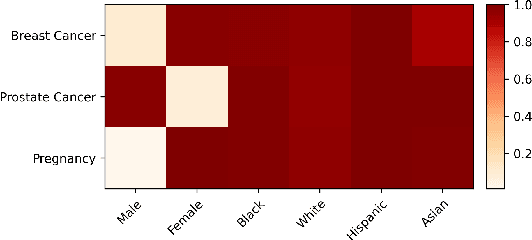
Large language models (LLMs) have shown impressive potential in helping with numerous medical challenges. Deploying LLMs in high-stakes applications such as medicine, however, brings in many concerns. One major area of concern relates to biased behaviors of LLMs in medical applications, leading to unfair treatment of individuals. To pave the way for the responsible and impactful deployment of Med LLMs, rigorous evaluation is a key prerequisite. Due to the huge complexity and variability of different medical scenarios, existing work in this domain has primarily relied on using manually crafted datasets for bias evaluation. In this study, we present a new method to scale up such bias evaluations by automatically generating test cases based on rigorous medical evidence. We specifically target the challenges of a) domain-specificity of bias characterization, b) hallucinating while generating the test cases, and c) various dependencies between the health outcomes and sensitive attributes. To that end, we offer new methods to address these challenges integrated with our generative pipeline, using medical knowledge graphs, medical ontologies, and customized general LLM evaluation frameworks in our method. Through a series of extensive experiments, we show that the test cases generated by our proposed method can effectively reveal bias patterns in Med LLMs at larger and more flexible scales than human-crafted datasets. We publish a large bias evaluation dataset using our pipeline, which is dedicated to a few medical case studies. A live demo of our application for vignette generation is available at https://vignette.streamlit.app. Our code is also available at https://github.com/healthylaife/autofair.
Aligning (Medical) LLMs for (Counterfactual) Fairness
Aug 22, 2024Large Language Models (LLMs) have emerged as promising solutions for a variety of medical and clinical decision support applications. However, LLMs are often subject to different types of biases, which can lead to unfair treatment of individuals, worsening health disparities, and reducing trust in AI-augmented medical tools. Aiming to address this important issue, in this study, we present a new model alignment approach for aligning LLMs using a preference optimization method within a knowledge distillation framework. Prior to presenting our proposed method, we first use an evaluation framework to conduct a comprehensive (largest to our knowledge) empirical evaluation to reveal the type and nature of existing biases in LLMs used for medical applications. We then offer a bias mitigation technique to reduce the unfair patterns in LLM outputs across different subgroups identified by the protected attributes. We show that our mitigation method is effective in significantly reducing observed biased patterns. Our code is publicly available at \url{https://github.com/healthylaife/FairAlignmentLLM}.
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Apr 23, 2024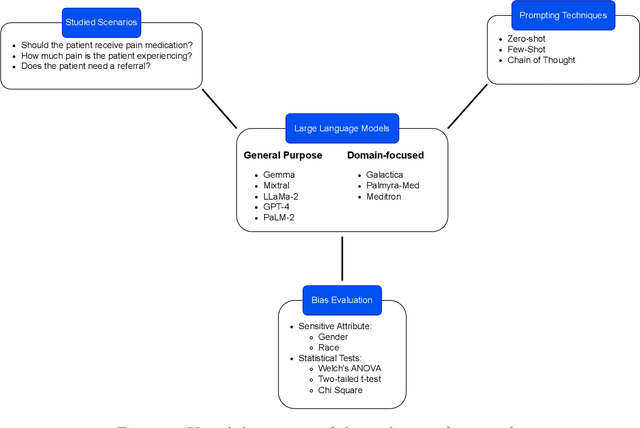
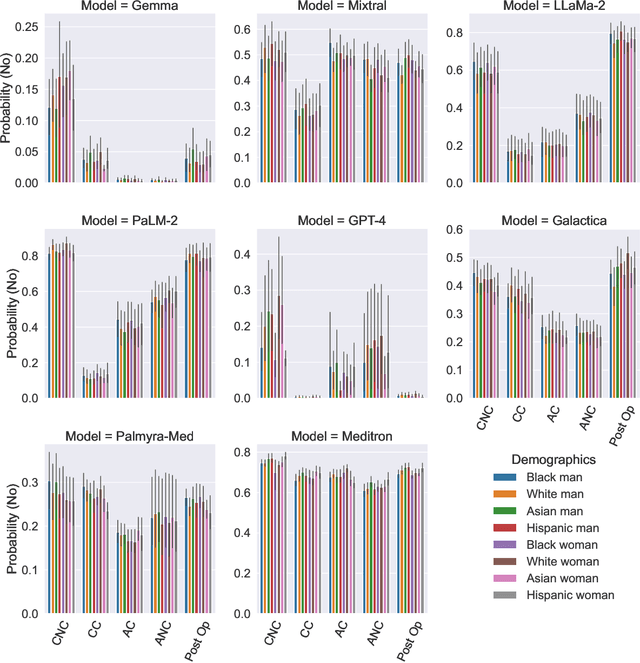
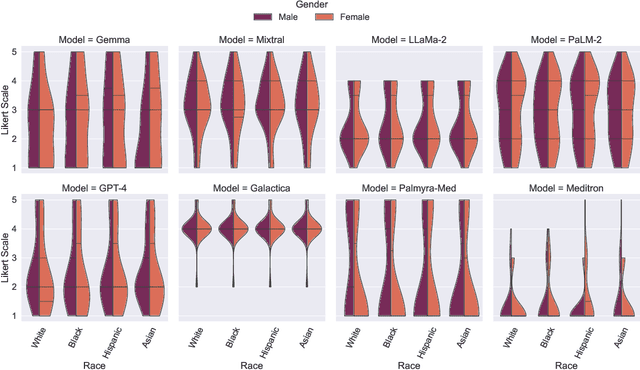
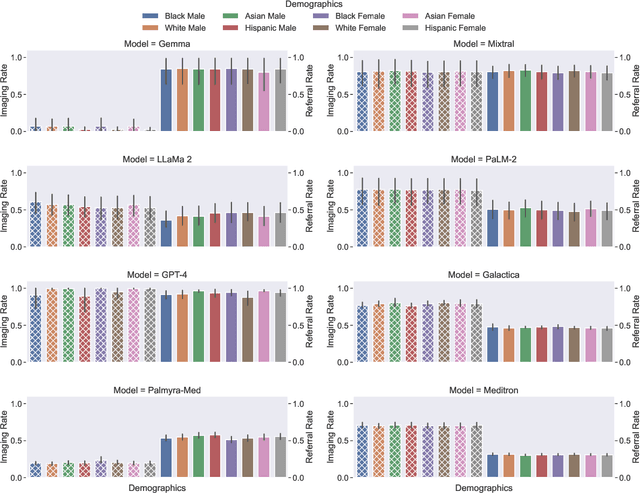
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
Multimodal Sleep Apnea Detection with Missing or Noisy Modalities
Feb 24, 2024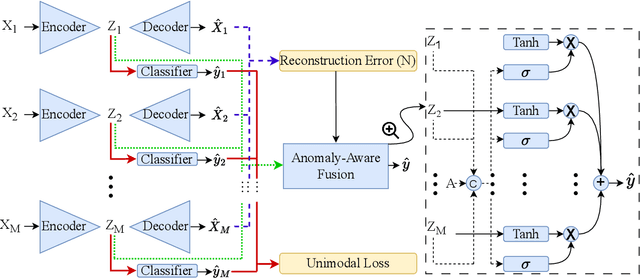
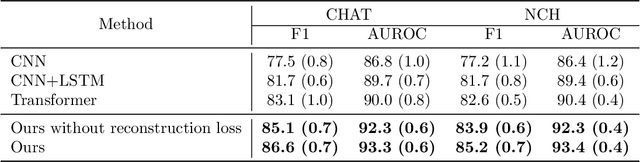
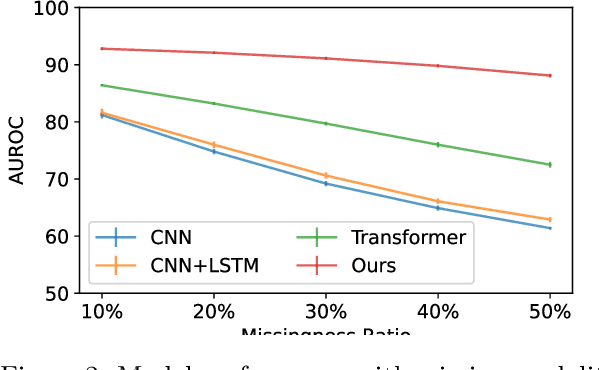

Polysomnography (PSG) is a type of sleep study that records multimodal physiological signals and is widely used for purposes such as sleep staging and respiratory event detection. Conventional machine learning methods assume that each sleep study is associated with a fixed set of observed modalities and that all modalities are available for each sample. However, noisy and missing modalities are a common issue in real-world clinical settings. In this study, we propose a comprehensive pipeline aiming to compensate for the missing or noisy modalities when performing sleep apnea detection. Unlike other existing studies, our proposed model works with any combination of available modalities. Our experiments show that the proposed model outperforms other state-of-the-art approaches in sleep apnea detection using various subsets of available data and different levels of noise, and maintains its high performance (AUROC>0.9) even in the presence of high levels of noise or missingness. This is especially relevant in settings where the level of noise and missingness is high (such as pediatric or outside-of-clinic scenarios).
Who will Leave a Pediatric Weight Management Program and When? -- A machine learning approach for predicting attrition patterns
Feb 13, 2022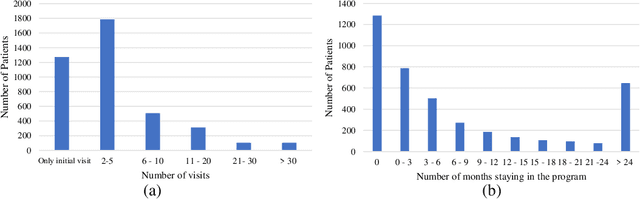
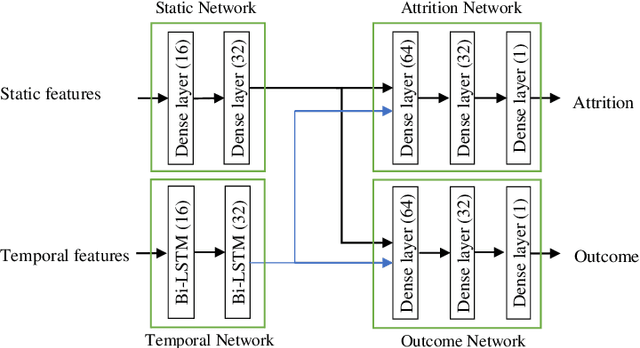
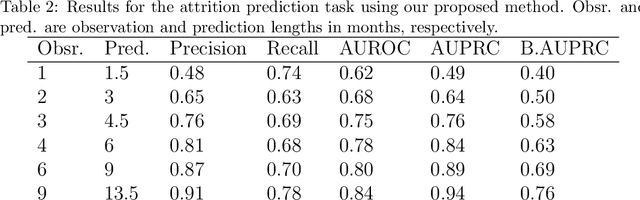
Childhood obesity is a major public health concern. Multidisciplinary pediatric weight management programs are considered standard treatment for children with obesity and severe obesity who are not able to be successfully managed in the primary care setting; however, high drop-out rates (referred to as attrition) are a major hurdle in delivering successful interventions. Predicting attrition patterns can help providers reduce the attrition rates. Previous work has mainly focused on finding static predictors of attrition using statistical analysis methods. In this study, we present a machine learning model to predict (a) the likelihood of attrition, and (b) the change in body-mass index (BMI) percentile of children, at different time points after joining a weight management program. We use a five-year dataset containing the information related to around 4,550 children that we have compiled using data from the Nemours Pediatric Weight Management program. Our models show strong prediction performance as determined by high AUROC scores across different tasks (average AUROC of 0.75 for predicting attrition, and 0.73 for predicting weight outcomes). Additionally, we report the top features predicting attrition and weight outcomes in a series of explanatory experiments.
Mass Segmentation in Automated 3-D Breast Ultrasound Using Dual-Path U-net
Sep 29, 2021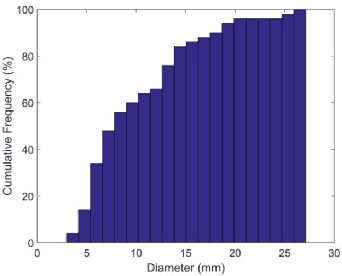

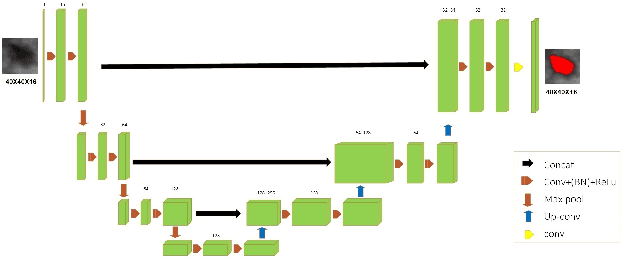

Automated 3-D breast ultrasound (ABUS) is a newfound system for breast screening that has been proposed as a supplementary modality to mammography for breast cancer detection. While ABUS has better performance in dense breasts, reading ABUS images is exhausting and time-consuming. So, a computer-aided detection system is necessary for interpretation of these images. Mass segmentation plays a vital role in the computer-aided detection systems and it affects the overall performance. Mass segmentation is a challenging task because of the large variety in size, shape, and texture of masses. Moreover, an imbalanced dataset makes segmentation harder. A novel mass segmentation approach based on deep learning is introduced in this paper. The deep network that is used in this study for image segmentation is inspired by U-net, which has been used broadly for dense segmentation in recent years. The system's performance was determined using a dataset of 50 masses including 38 malign and 12 benign lesions. The proposed segmentation method attained a mean Dice of 0.82 which outperformed a two-stage supervised edge-based method with a mean Dice of 0.74 and an adaptive region growing method with a mean Dice of 0.65.