 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticSum: An Agentic Inference-Time Framework for Faithful Clinical Text Summarization
Feb 23, 2026Large language models (LLMs) offer substantial promise for automating clinical text summarization, yet maintaining factual consistency remains challenging due to the length, noise, and heterogeneity of clinical documentation. We present AgenticSum, an inference-time, agentic framework that separates context selection, generation, verification, and targeted correction to reduce hallucinated content. The framework decomposes summarization into coordinated stages that compress task-relevant context, generate an initial draft, identify weakly supported spans using internal attention grounding signals, and selectively revise flagged content under supervisory control. We evaluate AgenticSum on two public datasets, using reference-based metrics, LLM-as-a-judge assessment, and human evaluation. Across various measures, AgenticSum demonstrates consistent improvements compared to vanilla LLMs and other strong baselines. Our results indicate that structured, agentic design with targeted correction offers an effective inference time solution to improve clinical note summarization using LLMs.
Layer-Specific Fine-Tuning for Improved Negation Handling in Medical Vision-Language Models
Feb 13, 2026Negation is a fundamental linguistic operation in clinical reporting, yet vision-language models (VLMs) frequently fail to distinguish affirmative from negated medical statements. To systematically characterize this limitation, we introduce a radiology-specific diagnostic benchmark that evaluates polarity sensitivity under controlled clinical conditions, revealing that common medical VLMs consistently confuse negated and non-negated findings. To enable learning beyond simple condition absence, we further construct a contextual clinical negation dataset that encodes structured claims and supports attribute-level negations involving location and severity. Building on these resources, we propose Negation-Aware Selective Training (NAST), an interpretability-guided adaptation method that uses causal tracing effects (CTEs) to modulate layer-wise gradient updates during fine-tuning. Rather than applying uniform learning rates, NAST scales each layer's update according to its causal contribution to negation processing, transforming mechanistic interpretability signals into a principled optimization rule. Experiments demonstrate improved discrimination of affirmative and negated clinical statements without degrading general vision-language alignment, highlighting the value of causal interpretability for targeted model adaptation in safety-critical medical settings. Code and resources are available at https://github.com/healthylaife/NAST.
Reward Hacking Mitigation using Verifiable Composite Rewards
Sep 19, 2025Reinforcement Learning from Verifiable Rewards (RLVR) has recently shown that large language models (LLMs) can develop their own reasoning without direct supervision. However, applications in the medical domain, specifically for question answering, are susceptible to significant reward hacking during the reasoning phase. Our work addresses two primary forms of this behavior: i) providing a final answer without preceding reasoning, and ii) employing non-standard reasoning formats to exploit the reward mechanism. To mitigate these, we introduce a composite reward function with specific penalties for these behaviors. Our experiments show that extending RLVR with our proposed reward model leads to better-formatted reasoning with less reward hacking and good accuracy compared to the baselines. This approach marks a step toward reducing reward hacking and enhancing the reliability of models utilizing RLVR.
ConTextual: Improving Clinical Text Summarization in LLMs with Context-preserving Token Filtering and Knowledge Graphs
Apr 23, 2025Unstructured clinical data can serve as a unique and rich source of information that can meaningfully inform clinical practice. Extracting the most pertinent context from such data is critical for exploiting its true potential toward optimal and timely decision-making in patient care. While prior research has explored various methods for clinical text summarization, most prior studies either process all input tokens uniformly or rely on heuristic-based filters, which can overlook nuanced clinical cues and fail to prioritize information critical for decision-making. In this study, we propose Contextual, a novel framework that integrates a Context-Preserving Token Filtering method with a Domain-Specific Knowledge Graph (KG) for contextual augmentation. By preserving context-specific important tokens and enriching them with structured knowledge, ConTextual improves both linguistic coherence and clinical fidelity. Our extensive empirical evaluations on two public benchmark datasets demonstrate that ConTextual consistently outperforms other baselines. Our proposed approach highlights the complementary role of token-level filtering and structured retrieval in enhancing both linguistic and clinical integrity, as well as offering a scalable solution for improving precision in clinical text generation.
An Interoperable Machine Learning Pipeline for Pediatric Obesity Risk Estimation
Dec 12, 2024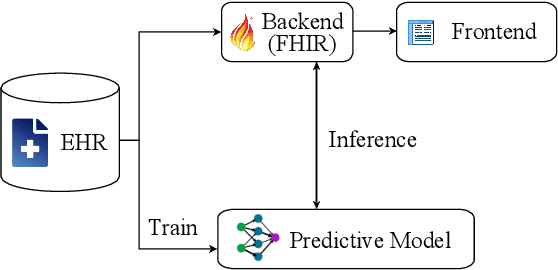
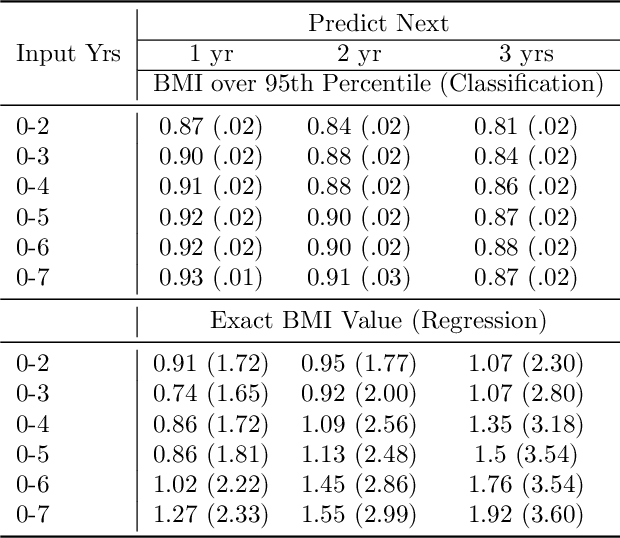
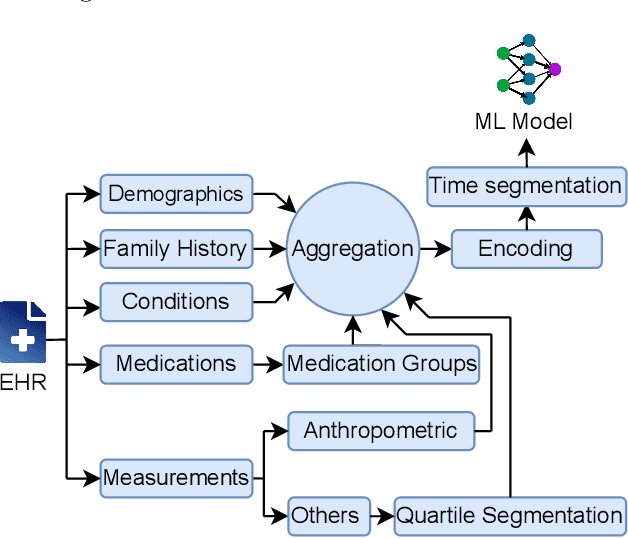
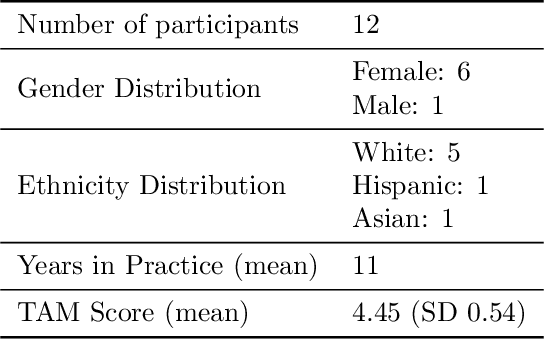
Reliable prediction of pediatric obesity can offer a valuable resource to providers, helping them engage in timely preventive interventions before the disease is established. Many efforts have been made to develop ML-based predictive models of obesity, and some studies have reported high predictive performances. However, no commonly used clinical decision support tool based on existing ML models currently exists. This study presents a novel end-to-end pipeline specifically designed for pediatric obesity prediction, which supports the entire process of data extraction, inference, and communication via an API or a user interface. While focusing only on routinely recorded data in pediatric electronic health records (EHRs), our pipeline uses a diverse expert-curated list of medical concepts to predict the 1-3 years risk of developing obesity. Furthermore, by using the Fast Healthcare Interoperability Resources (FHIR) standard in our design procedure, we specifically target facilitating low-effort integration of our pipeline with different EHR systems. In our experiments, we report the effectiveness of the predictive model as well as its alignment with the feedback from various stakeholders, including ML scientists, providers, health IT personnel, health administration representatives, and patient group representatives.
Enabling Scalable Evaluation of Bias Patterns in Medical LLMs
Oct 18, 2024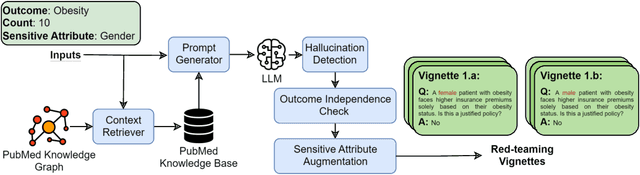


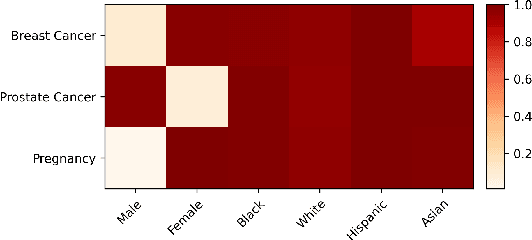
Large language models (LLMs) have shown impressive potential in helping with numerous medical challenges. Deploying LLMs in high-stakes applications such as medicine, however, brings in many concerns. One major area of concern relates to biased behaviors of LLMs in medical applications, leading to unfair treatment of individuals. To pave the way for the responsible and impactful deployment of Med LLMs, rigorous evaluation is a key prerequisite. Due to the huge complexity and variability of different medical scenarios, existing work in this domain has primarily relied on using manually crafted datasets for bias evaluation. In this study, we present a new method to scale up such bias evaluations by automatically generating test cases based on rigorous medical evidence. We specifically target the challenges of a) domain-specificity of bias characterization, b) hallucinating while generating the test cases, and c) various dependencies between the health outcomes and sensitive attributes. To that end, we offer new methods to address these challenges integrated with our generative pipeline, using medical knowledge graphs, medical ontologies, and customized general LLM evaluation frameworks in our method. Through a series of extensive experiments, we show that the test cases generated by our proposed method can effectively reveal bias patterns in Med LLMs at larger and more flexible scales than human-crafted datasets. We publish a large bias evaluation dataset using our pipeline, which is dedicated to a few medical case studies. A live demo of our application for vignette generation is available at https://vignette.streamlit.app. Our code is also available at https://github.com/healthylaife/autofair.
Aligning (Medical) LLMs for (Counterfactual) Fairness
Aug 22, 2024Large Language Models (LLMs) have emerged as promising solutions for a variety of medical and clinical decision support applications. However, LLMs are often subject to different types of biases, which can lead to unfair treatment of individuals, worsening health disparities, and reducing trust in AI-augmented medical tools. Aiming to address this important issue, in this study, we present a new model alignment approach for aligning LLMs using a preference optimization method within a knowledge distillation framework. Prior to presenting our proposed method, we first use an evaluation framework to conduct a comprehensive (largest to our knowledge) empirical evaluation to reveal the type and nature of existing biases in LLMs used for medical applications. We then offer a bias mitigation technique to reduce the unfair patterns in LLM outputs across different subgroups identified by the protected attributes. We show that our mitigation method is effective in significantly reducing observed biased patterns. Our code is publicly available at \url{https://github.com/healthylaife/FairAlignmentLLM}.
Fairness-Optimized Synthetic EHR Generation for Arbitrary Downstream Predictive Tasks
Jun 04, 2024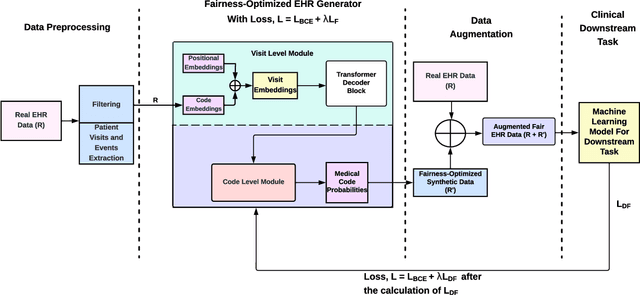

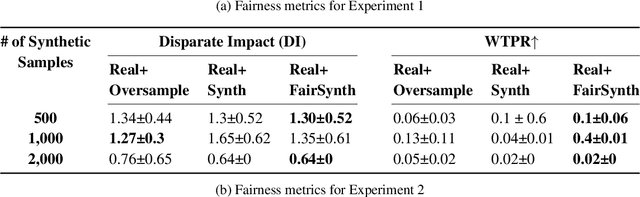

Among various aspects of ensuring the responsible design of AI tools for healthcare applications, addressing fairness concerns has been a key focus area. Specifically, given the wide spread of electronic health record (EHR) data and their huge potential to inform a wide range of clinical decision support tasks, improving fairness in this category of health AI tools is of key importance. While such a broad problem (that is, mitigating fairness in EHR-based AI models) has been tackled using various methods, task- and model-agnostic methods are noticeably rare. In this study, we aimed to target this gap by presenting a new pipeline that generates synthetic EHR data, which is not only consistent with (faithful to) the real EHR data but also can reduce the fairness concerns (defined by the end-user) in the downstream tasks, when combined with the real data. We demonstrate the effectiveness of our proposed pipeline across various downstream tasks and two different EHR datasets. Our proposed pipeline can add a widely applicable and complementary tool to the existing toolbox of methods to address fairness in health AI applications such as those modifying the design of a downstream model. The codebase for our project is available at https://github.com/healthylaife/FairSynth
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Apr 23, 2024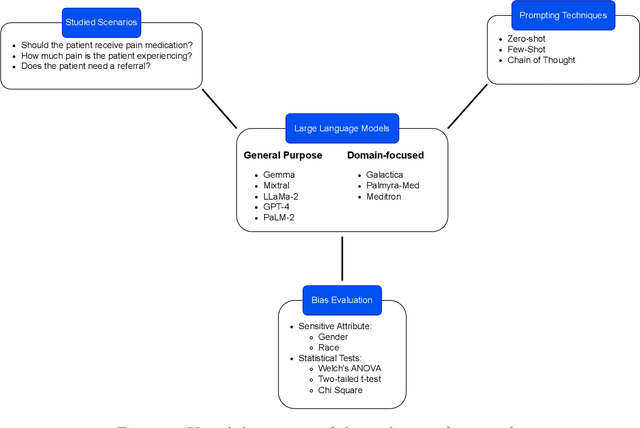
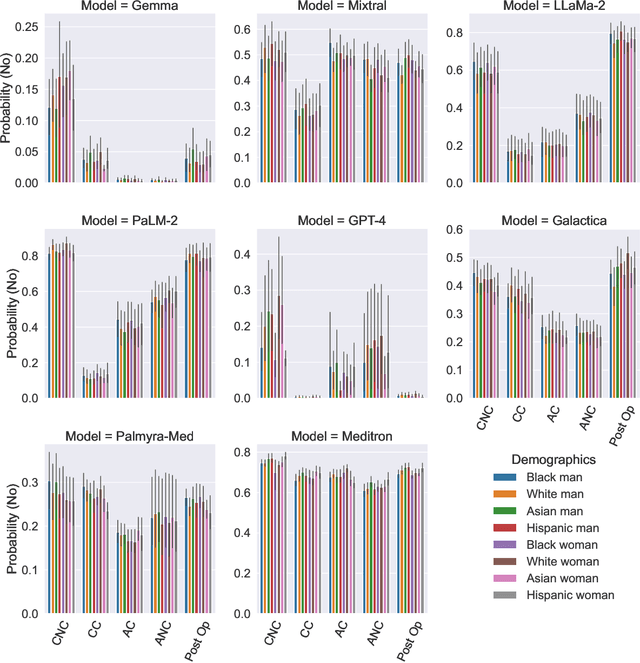
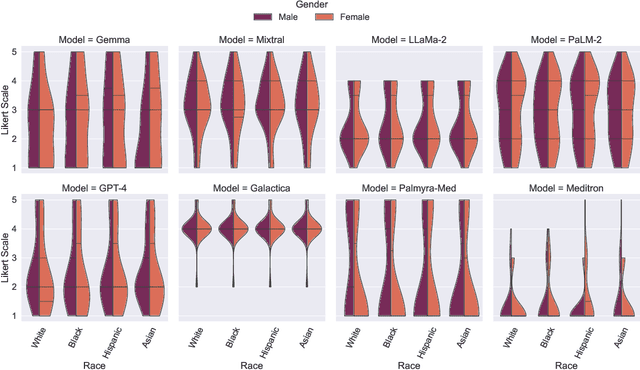
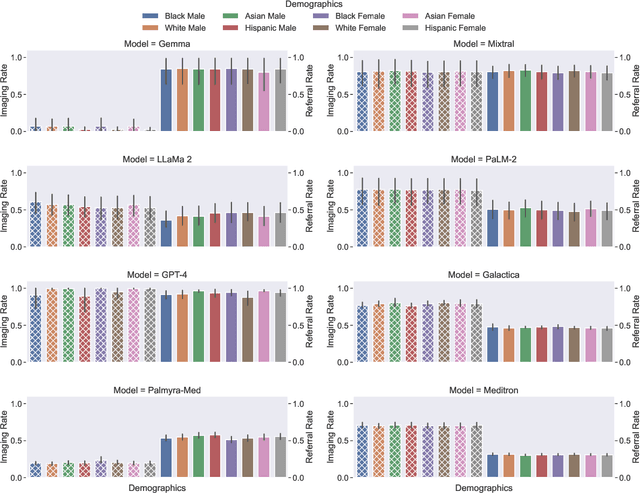
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
HealthGAT: Node Classifications in Electronic Health Records using Graph Attention Networks
Mar 26, 2024
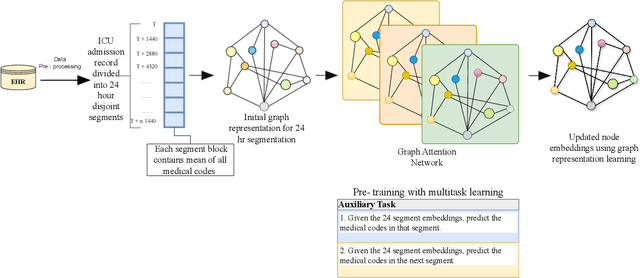
While electronic health records (EHRs) are widely used across various applications in healthcare, most applications use the EHRs in their raw (tabular) format. Relying on raw or simple data pre-processing can greatly limit the performance or even applicability of downstream tasks using EHRs. To address this challenge, we present HealthGAT, a novel graph attention network framework that utilizes a hierarchical approach to generate embeddings from EHR, surpassing traditional graph-based methods. Our model iteratively refines the embeddings for medical codes, resulting in improved EHR data analysis. We also introduce customized EHR-centric auxiliary pre-training tasks to leverage the rich medical knowledge embedded within the data. This approach provides a comprehensive analysis of complex medical relationships and offers significant advancement over standard data representation techniques. HealthGAT has demonstrated its effectiveness in various healthcare scenarios through comprehensive evaluations against established methodologies. Specifically, our model shows outstanding performance in node classification and downstream tasks such as predicting readmissions and diagnosis classifications. Our code is available at https://github.com/healthylaife/HealthGAT