 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Scalable Evaluation of Bias Patterns in Medical LLMs
Paper and Code
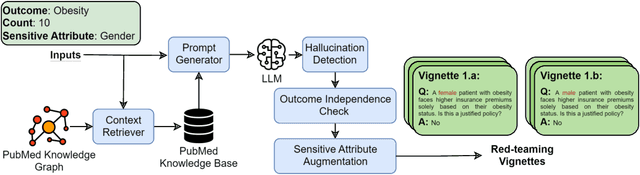


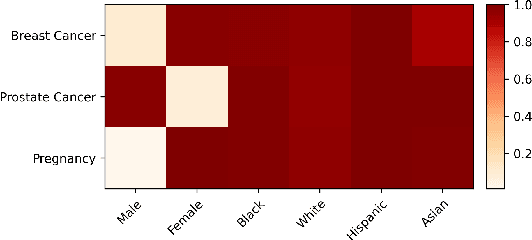
Large language models (LLMs) have shown impressive potential in helping with numerous medical challenges. Deploying LLMs in high-stakes applications such as medicine, however, brings in many concerns. One major area of concern relates to biased behaviors of LLMs in medical applications, leading to unfair treatment of individuals. To pave the way for the responsible and impactful deployment of Med LLMs, rigorous evaluation is a key prerequisite. Due to the huge complexity and variability of different medical scenarios, existing work in this domain has primarily relied on using manually crafted datasets for bias evaluation. In this study, we present a new method to scale up such bias evaluations by automatically generating test cases based on rigorous medical evidence. We specifically target the challenges of a) domain-specificity of bias characterization, b) hallucinating while generating the test cases, and c) various dependencies between the health outcomes and sensitive attributes. To that end, we offer new methods to address these challenges integrated with our generative pipeline, using medical knowledge graphs, medical ontologies, and customized general LLM evaluation frameworks in our method. Through a series of extensive experiments, we show that the test cases generated by our proposed method can effectively reveal bias patterns in Med LLMs at larger and more flexible scales than human-crafted datasets. We publish a large bias evaluation dataset using our pipeline, which is dedicated to a few medical case studies. A live demo of our application for vignette generation is available at https://vignette.streamlit.app. Our code is also available at https://github.com/healthylaife/autofair.