 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interoperable Machine Learning Pipeline for Pediatric Obesity Risk Estimation
Dec 12, 2024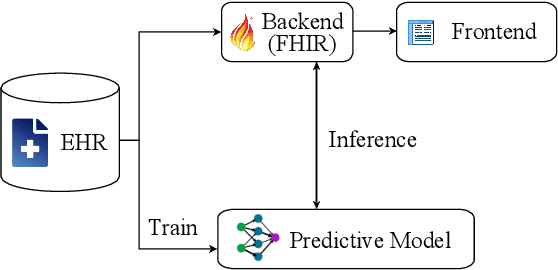
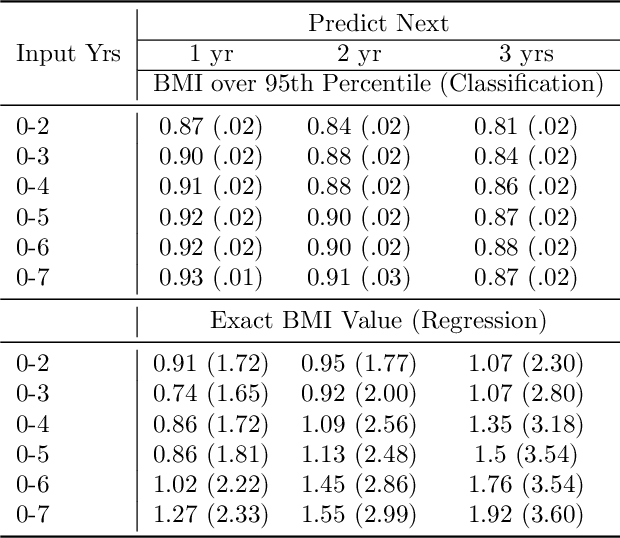
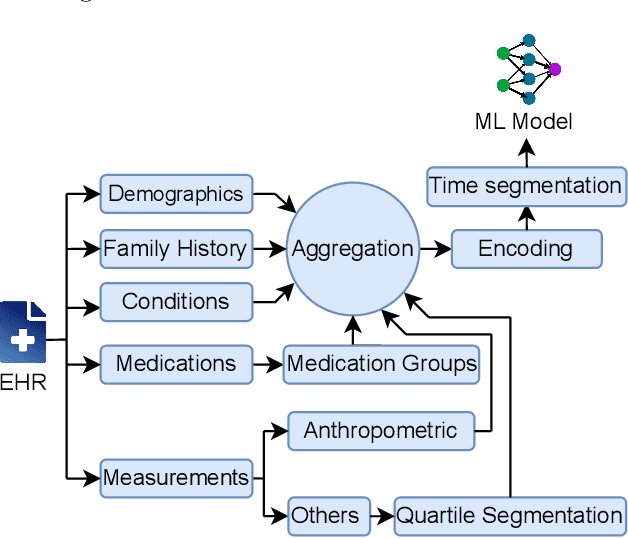
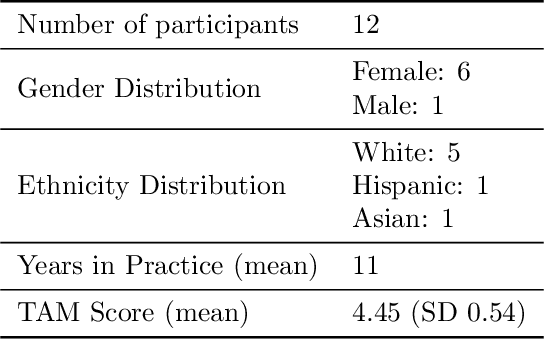
Reliable prediction of pediatric obesity can offer a valuable resource to providers, helping them engage in timely preventive interventions before the disease is established. Many efforts have been made to develop ML-based predictive models of obesity, and some studies have reported high predictive performances. However, no commonly used clinical decision support tool based on existing ML models currently exists. This study presents a novel end-to-end pipeline specifically designed for pediatric obesity prediction, which supports the entire process of data extraction, inference, and communication via an API or a user interface. While focusing only on routinely recorded data in pediatric electronic health records (EHRs), our pipeline uses a diverse expert-curated list of medical concepts to predict the 1-3 years risk of developing obesity. Furthermore, by using the Fast Healthcare Interoperability Resources (FHIR) standard in our design procedure, we specifically target facilitating low-effort integration of our pipeline with different EHR systems. In our experiments, we report the effectiveness of the predictive model as well as its alignment with the feedback from various stakeholders, including ML scientists, providers, health IT personnel, health administration representatives, and patient group representatives.
Co-occurrence of medical conditions: Exposing patterns through probabilistic topic modeling of SNOMED codes
Sep 19, 2021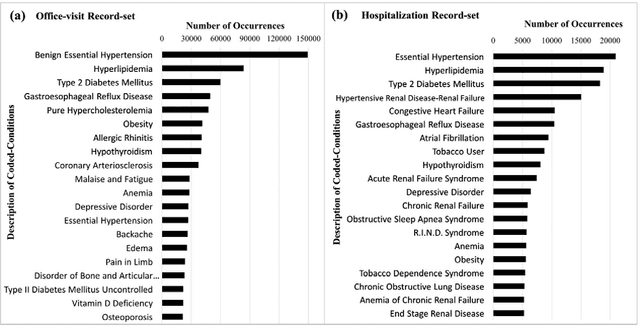
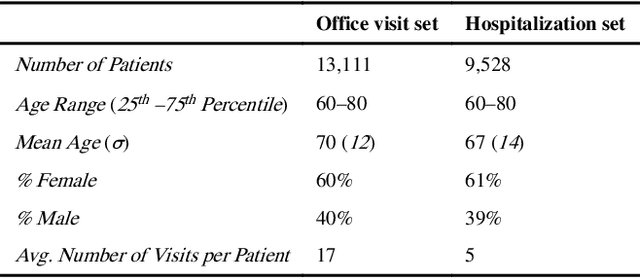
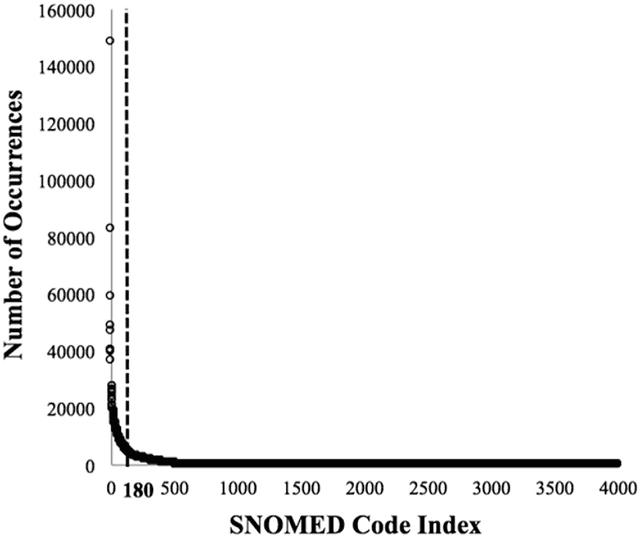
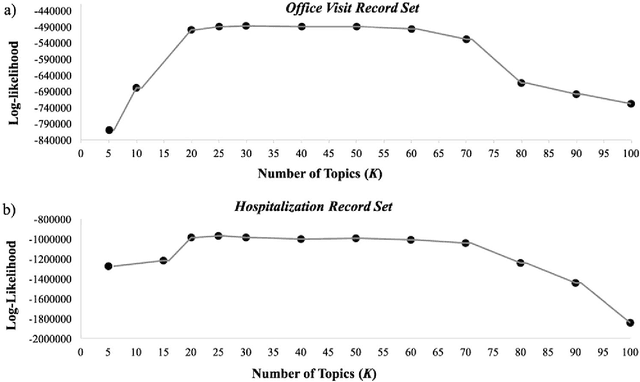
Patients associated with multiple co-occurring health conditions often face aggravated complications and less favorable outcomes. Co-occurring conditions are especially prevalent among individuals suffering from kidney disease, an increasingly widespread condition affecting 13% of the general population in the US. This study aims to identify and characterize patterns of co-occurring medical conditions in patients employing a probabilistic framework. Specifically, we apply topic modeling in a non-traditional way to find associations across SNOMEDCT codes assigned and recorded in the EHRs of>13,000 patients diagnosed with kidney disease. Unlike most prior work on topic modeling, we apply the method to codes rather than to natural language. Moreover, we quantitatively evaluate the topics, assessing their tightness and distinctiveness, and also assess the medical validity of our results. Our experiments show that each topic is succinctly characterized by a few highly probable and unique disease codes, indicating that the topics are tight. Furthermore, inter-topic distance between each pair of topics is typically high, illustrating distinctiveness. Last, most coded conditions grouped together within a topic, are indeed reported to co-occur in the medical literature. Notably, our results uncover a few indirect associations among conditions that have hitherto not been reported as correlated in the medical literature.
Identifying Patterns of Associated-Conditions through Topic Models of Electronic Medical Records
Nov 17, 2017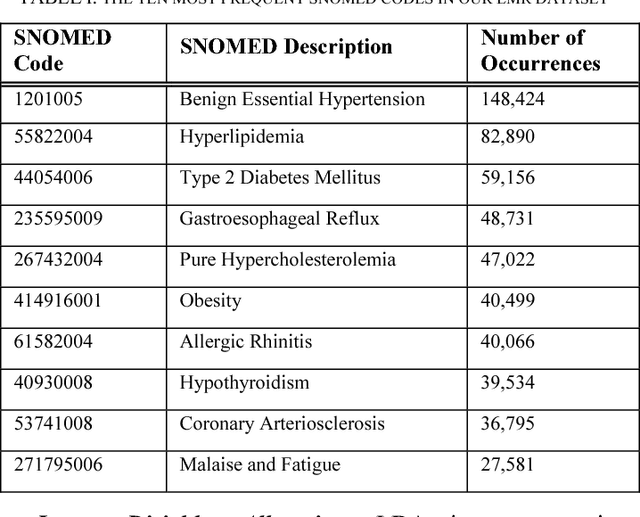
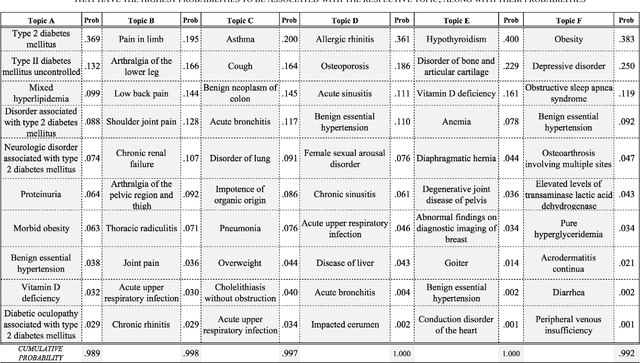
Multiple adverse health conditions co-occurring in a patient are typically associated with poor prognosis and increased office or hospital visits. Developing methods to identify patterns of co-occurring conditions can assist in diagnosis. Thus identifying patterns of associations among co-occurring conditions is of growing interest. In this paper, we report preliminary results from a data-driven study, in which we apply a machine learning method, namely, topic modeling, to electronic medical records, aiming to identify patterns of associated conditions. Specifically, we use the well established latent dirichlet allocation, a method based on the idea that documents can be modeled as a mixture of latent topics, where each topic is a distribution over words. In our study, we adapt the LDA model to identify latent topics in patients' EMRs. We evaluate the performance of our method both qualitatively, and show that the obtained topics indeed align well with distinct medical phenomena characterized by co-occurring conditions.