 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interoperable Machine Learning Pipeline for Pediatric Obesity Risk Estimation
Dec 12, 2024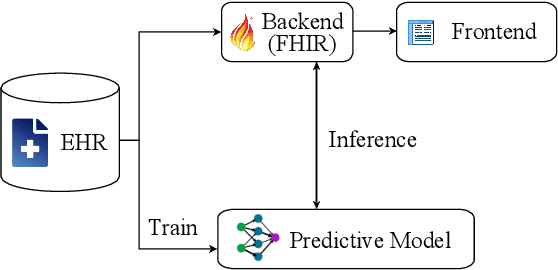
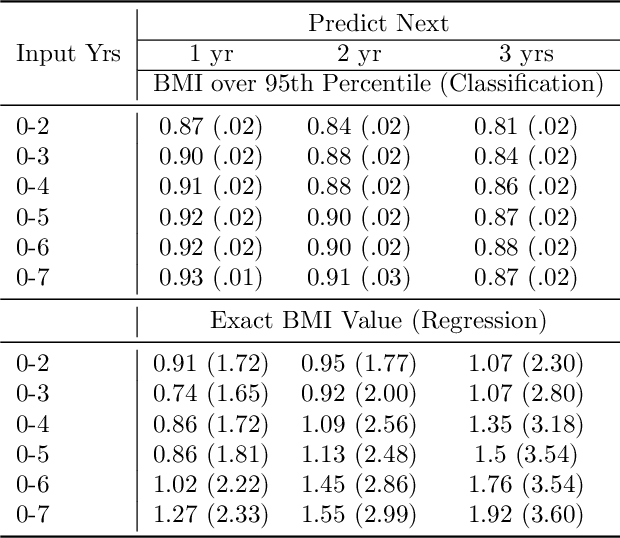
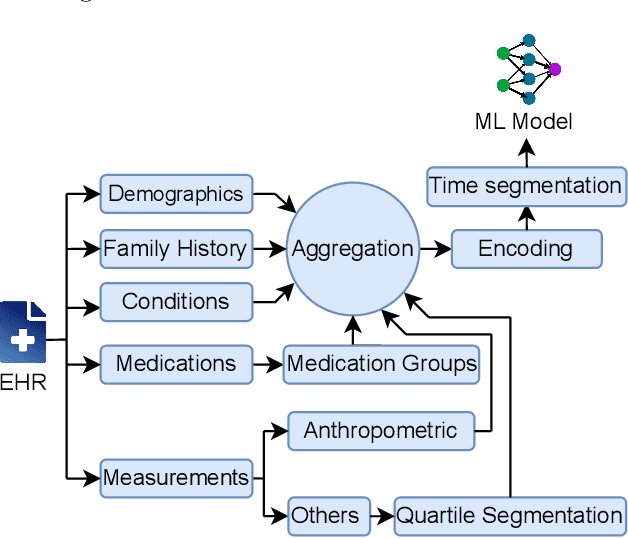
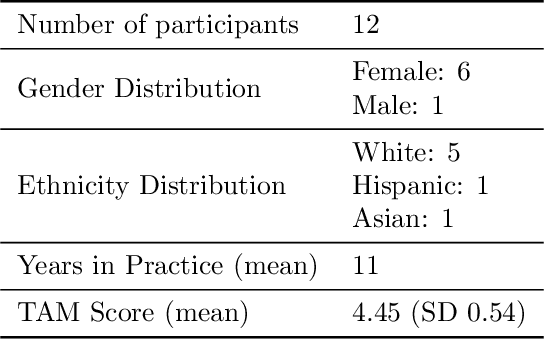
Reliable prediction of pediatric obesity can offer a valuable resource to providers, helping them engage in timely preventive interventions before the disease is established. Many efforts have been made to develop ML-based predictive models of obesity, and some studies have reported high predictive performances. However, no commonly used clinical decision support tool based on existing ML models currently exists. This study presents a novel end-to-end pipeline specifically designed for pediatric obesity prediction, which supports the entire process of data extraction, inference, and communication via an API or a user interface. While focusing only on routinely recorded data in pediatric electronic health records (EHRs), our pipeline uses a diverse expert-curated list of medical concepts to predict the 1-3 years risk of developing obesity. Furthermore, by using the Fast Healthcare Interoperability Resources (FHIR) standard in our design procedure, we specifically target facilitating low-effort integration of our pipeline with different EHR systems. In our experiments, we report the effectiveness of the predictive model as well as its alignment with the feedback from various stakeholders, including ML scientists, providers, health IT personnel, health administration representatives, and patient group representatives.
Who will Leave a Pediatric Weight Management Program and When? -- A machine learning approach for predicting attrition patterns
Feb 13, 2022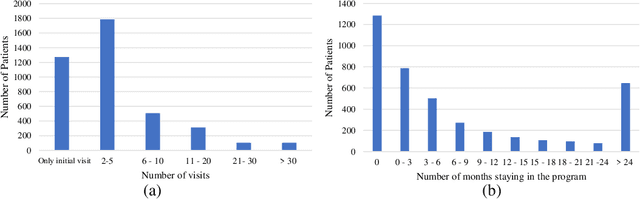
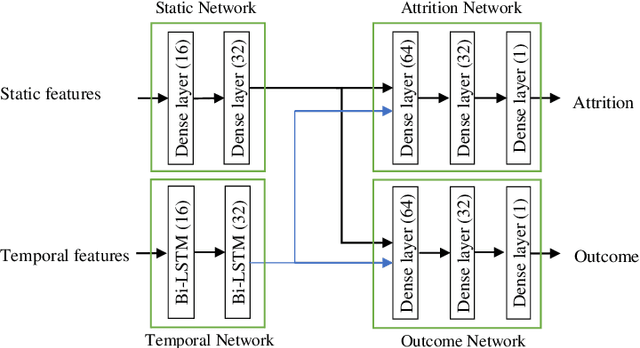
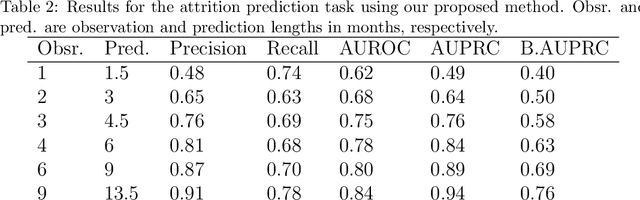
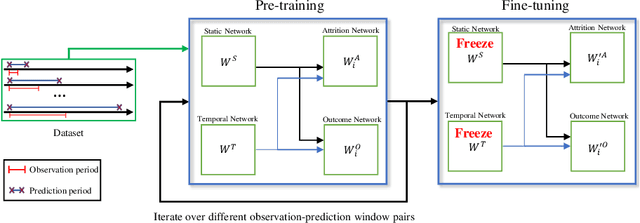
Childhood obesity is a major public health concern. Multidisciplinary pediatric weight management programs are considered standard treatment for children with obesity and severe obesity who are not able to be successfully managed in the primary care setting; however, high drop-out rates (referred to as attrition) are a major hurdle in delivering successful interventions. Predicting attrition patterns can help providers reduce the attrition rates. Previous work has mainly focused on finding static predictors of attrition using statistical analysis methods. In this study, we present a machine learning model to predict (a) the likelihood of attrition, and (b) the change in body-mass index (BMI) percentile of children, at different time points after joining a weight management program. We use a five-year dataset containing the information related to around 4,550 children that we have compiled using data from the Nemours Pediatric Weight Management program. Our models show strong prediction performance as determined by high AUROC scores across different tasks (average AUROC of 0.75 for predicting attrition, and 0.73 for predicting weight outcomes). Additionally, we report the top features predicting attrition and weight outcomes in a series of explanatory experiments.
Obesity Prediction with EHR Data: A deep learning approach with interpretable elements
Jan 30, 2020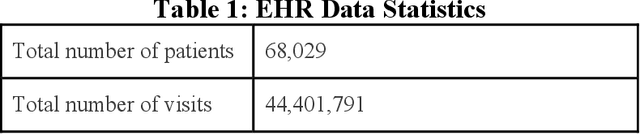
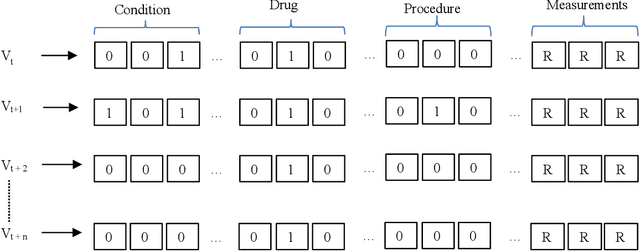
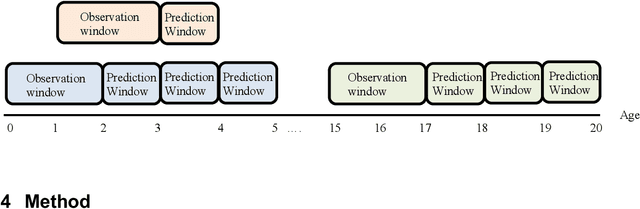
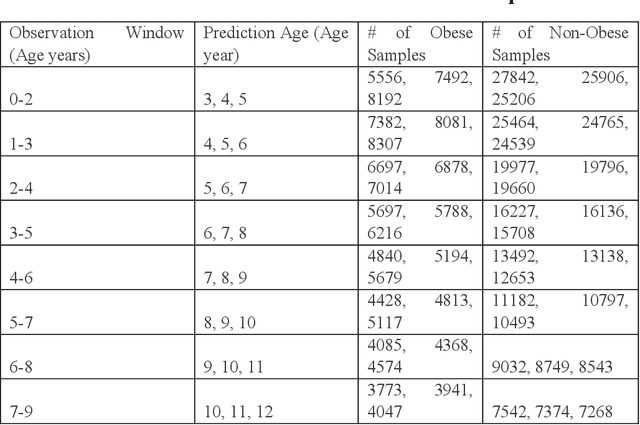
Childhood obesity is a major public health challenge. Obesity in early childhood and adolescence can lead to obesity and other health problems in adulthood. Early prediction and identification of the children at a high risk of developing childhood obesity may help in engaging earlier and more effective interventions to prevent and manage this and other related health conditions. Existing predictive tools designed for childhood obesity primarily rely on traditional regression-type methods without exploiting longitudinal patterns of children's data (ignoring data temporality). In this paper, we present a machine learning model specifically designed for predicting future obesity patterns from generally available items on children's medical history. To do this, we have used a large unaugmented EHR (Electronic Health Record) dataset from a major pediatric health system in the US. We adopt a general LSTM (long short-term memory) network architecture for our model for training over dynamic (sequential) and static (demographic) EHR data. We have additionally included a set embedding and attention layers to compute the feature ranking of each timestamp and attention scores of each hidden layer corresponding to each input timestamp. These feature ranking and attention scores added interpretability at both the features and the timestamp-level.