 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Hacking Mitigation using Verifiable Composite Rewards
Sep 19, 2025Reinforcement Learning from Verifiable Rewards (RLVR) has recently shown that large language models (LLMs) can develop their own reasoning without direct supervision. However, applications in the medical domain, specifically for question answering, are susceptible to significant reward hacking during the reasoning phase. Our work addresses two primary forms of this behavior: i) providing a final answer without preceding reasoning, and ii) employing non-standard reasoning formats to exploit the reward mechanism. To mitigate these, we introduce a composite reward function with specific penalties for these behaviors. Our experiments show that extending RLVR with our proposed reward model leads to better-formatted reasoning with less reward hacking and good accuracy compared to the baselines. This approach marks a step toward reducing reward hacking and enhancing the reliability of models utilizing RLVR.
Fairness-Optimized Synthetic EHR Generation for Arbitrary Downstream Predictive Tasks
Jun 04, 2024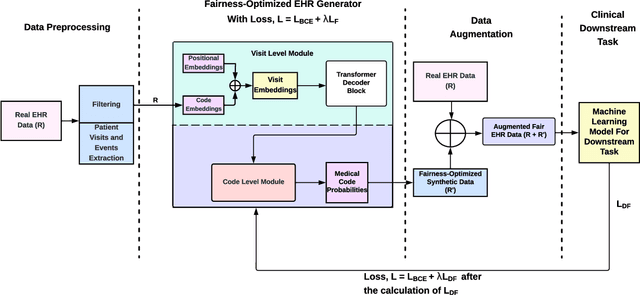

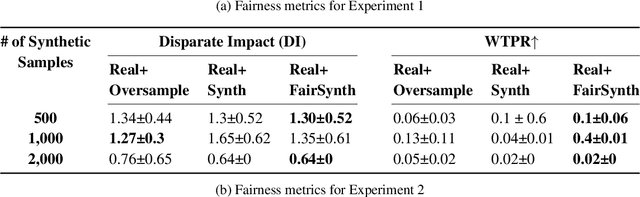

Among various aspects of ensuring the responsible design of AI tools for healthcare applications, addressing fairness concerns has been a key focus area. Specifically, given the wide spread of electronic health record (EHR) data and their huge potential to inform a wide range of clinical decision support tasks, improving fairness in this category of health AI tools is of key importance. While such a broad problem (that is, mitigating fairness in EHR-based AI models) has been tackled using various methods, task- and model-agnostic methods are noticeably rare. In this study, we aimed to target this gap by presenting a new pipeline that generates synthetic EHR data, which is not only consistent with (faithful to) the real EHR data but also can reduce the fairness concerns (defined by the end-user) in the downstream tasks, when combined with the real data. We demonstrate the effectiveness of our proposed pipeline across various downstream tasks and two different EHR datasets. Our proposed pipeline can add a widely applicable and complementary tool to the existing toolbox of methods to address fairness in health AI applications such as those modifying the design of a downstream model. The codebase for our project is available at https://github.com/healthylaife/FairSynth
Improving Fairness in AI Models on Electronic Health Records: The Case for Federated Learning Methods
May 19, 2023
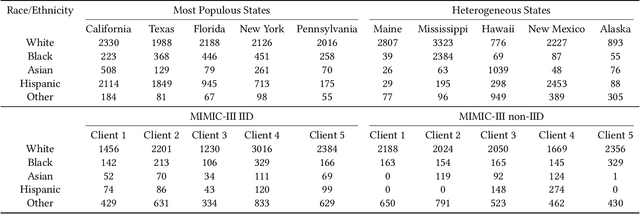
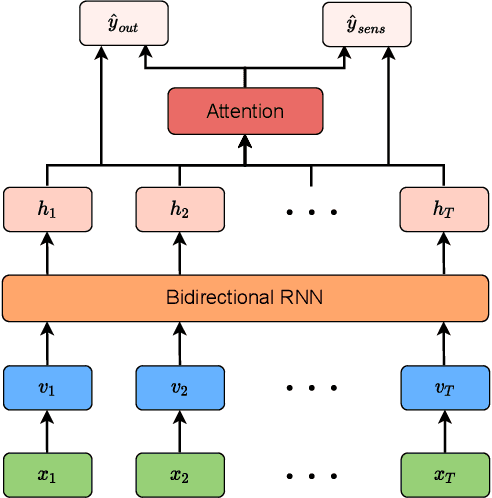
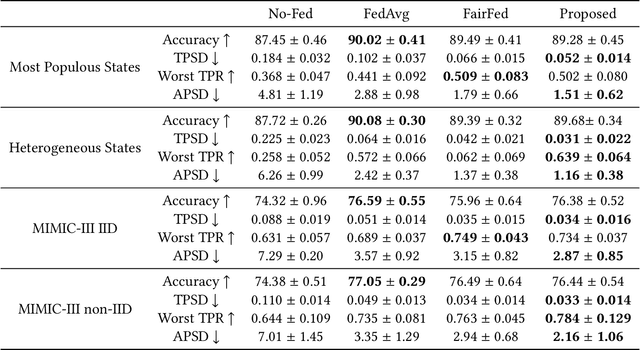
Developing AI tools that preserve fairness is of critical importance, specifically in high-stakes applications such as those in healthcare. However, health AI models' overall prediction performance is often prioritized over the possible biases such models could have. In this study, we show one possible approach to mitigate bias concerns by having healthcare institutions collaborate through a federated learning paradigm (FL; which is a popular choice in healthcare settings). While FL methods with an emphasis on fairness have been previously proposed, their underlying model and local implementation techniques, as well as their possible applications to the healthcare domain remain widely underinvestigated. Therefore, we propose a comprehensive FL approach with adversarial debiasing and a fair aggregation method, suitable to various fairness metrics, in the healthcare domain where electronic health records are used. Not only our approach explicitly mitigates bias as part of the optimization process, but an FL-based paradigm would also implicitly help with addressing data imbalance and increasing the data size, offering a practical solution for healthcare applications. We empirically demonstrate our method's superior performance on multiple experiments simulating large-scale real-world scenarios and compare it to several baselines. Our method has achieved promising fairness performance with the lowest impact on overall discrimination performance (accuracy).