 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extensive Data Processing Pipeline for MIMIC-IV
Apr 29, 2022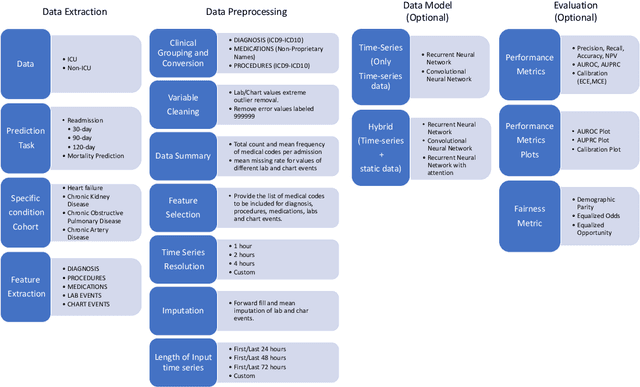

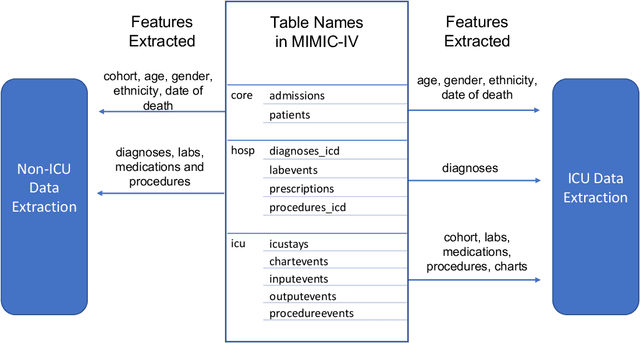
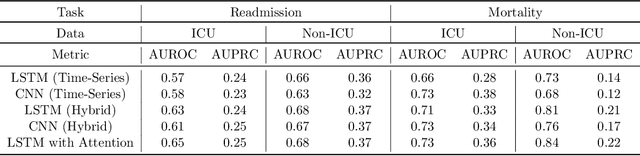
An increasing amount of research is being devoted to applying machine learning methods to electronic health record (EHR) data for various clinical tasks. This growing area of research has exposed the limitation of accessibility of EHR datasets for all, as well as the reproducibility of different modeling frameworks. One reason for these limitations is the lack of standardized pre-processing pipelines. MIMIC is a freely available EHR dataset in a raw format that has been used in numerous studies. The absence of standardized pre-processing steps serves as a major barrier to the wider adoption of the dataset. It also leads to different cohorts being used in downstream tasks, limiting the ability to compare the results among similar studies. Contrasting studies also use various distinct performance metrics, which can greatly reduce the ability to compare model results. In this work, we provide an end-to-end fully customizable pipeline to extract, clean, and pre-process data; and to predict and evaluate the fourth version of the MIMIC dataset (MIMIC-IV) for ICU and non-ICU-related clinical time-series prediction tasks.
Image Enhancement and Object Recognition for Night Vision Surveillance
Jun 10, 2020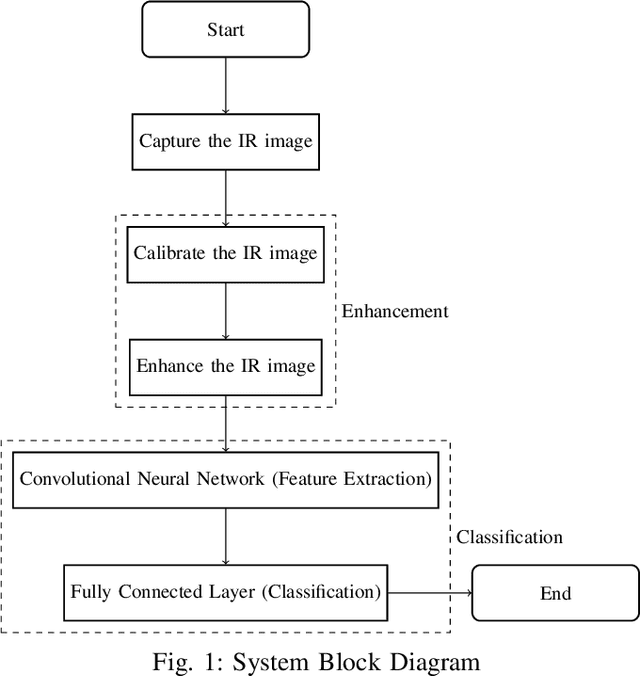

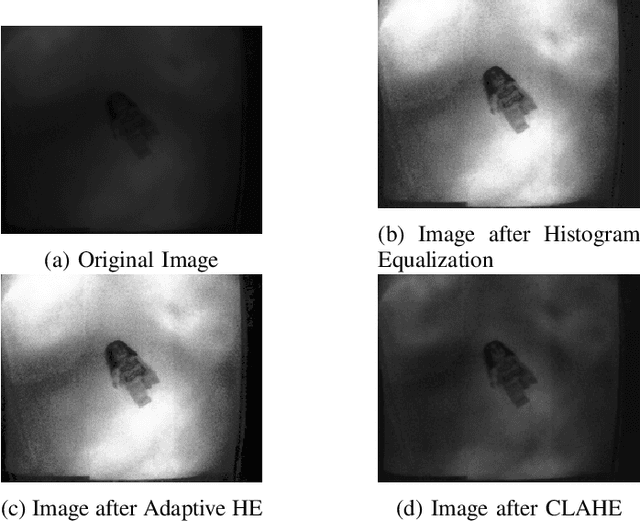

Object recognition is a critical part of any surveillance system. It is the matter of utmost concern to identify intruders and foreign objects in the area where surveillance is done. The performance of surveillance system using the traditional camera in daylight is vastly superior as compared to night. The main problem for surveillance during the night is the objects captured by traditional cameras have low contrast against the background because of the absence of ambient light in the visible spectrum. Due to that reason, the image is taken in low light condition using an Infrared Camera and the image is enhanced to obtain an image with higher contrast using different enhancing algorithms based on the spatial domain. The enhanced image is then sent to the classification process. The classification is done by using convolutional neural network followed by a fully connected layer of neurons. The accuracy of classification after implementing different enhancement algorithms is compared in this paper.
One-Shot Template Matching for Automatic Document Data Capture
Oct 22, 2019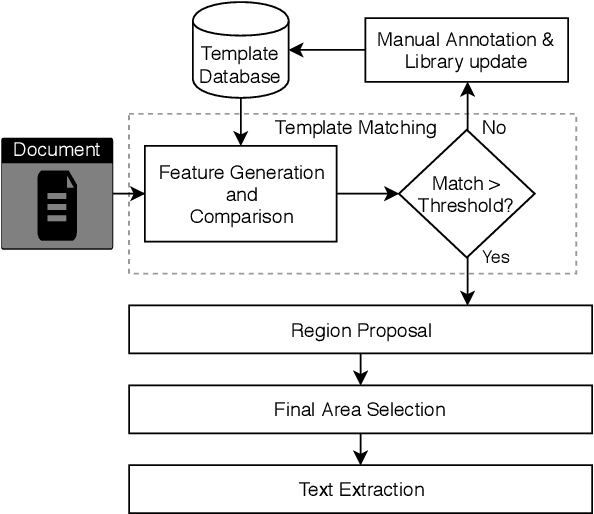
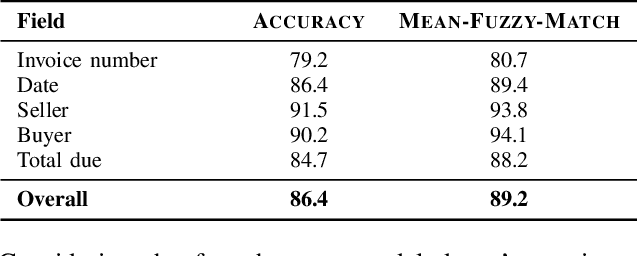
In this paper, we propose a novel one-shot template-matching algorithm to automatically capture data from business documents with an aim to minimize manual data entry. Given one annotated document, our algorithm can automatically extract similar data from other documents having the same format. Based on a set of engineered visual and textual features, our method is invariant to changes in position and value. Experiments on a dataset of 595 real invoices demonstrate 86.4% accuracy.