 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Composition of Weighted Finite-State Transducers
Paper and Code
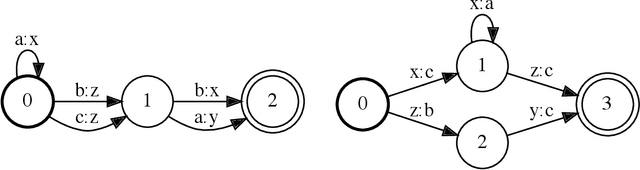


Finite-state transducers (FSTs) are frequently used in speech recognition. Transducer composition is an essential operation for combining different sources of information at different granularities. However, composition is also one of the more computationally expensive operations. Due to the heterogeneous structure of FSTs, parallel algorithms for composition are suboptimal in efficiency, generality, or both. We propose an algorithm for parallel composition and implement it on graphics processing units. We benchmark our parallel algorithm on the composition of random graphs and the composition of graphs commonly used in speech recognition. The parallel composition scales better with the size of the input graphs and for large graphs can be as much as 10 to 30 times faster than a sequential CPU algorithm.