 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecialized Language Models with Cheap Inference from Limited Domain Data
Feb 02, 2024



Large language models have emerged as a versatile tool but are challenging to apply to tasks lacking large inference budgets and large in-domain training sets. This work formalizes these constraints and distinguishes four important variables: the pretraining budget (for training before the target domain is known), the specialization budget (for training after the target domain is known), the inference budget, and the in-domain training set size. Across these settings, we compare different approaches from the machine learning literature. Limited by inference cost, we find better alternatives to the standard practice of training very large vanilla transformer models. In particular, we show that hyper-networks and mixture of experts have better perplexity for large pretraining budgets, while small models trained on importance sampled datasets are attractive for large specialization budgets.
Adaptive Training Distributions with Scalable Online Bilevel Optimization
Nov 20, 2023



Large neural networks pretrained on web-scale corpora are central to modern machine learning. In this paradigm, the distribution of the large, heterogeneous pretraining data rarely matches that of the application domain. This work considers modifying the pretraining distribution in the case where one has a small sample of data reflecting the targeted test conditions. We propose an algorithm motivated by a recent formulation of this setting as an online, bilevel optimization problem. With scalability in mind, our algorithm prioritizes computing gradients at training points which are likely to most improve the loss on the targeted distribution. Empirically, we show that in some cases this approach is beneficial over existing strategies from the domain adaptation literature but may not succeed in other cases. We propose a simple test to evaluate when our approach can be expected to work well and point towards further research to address current limitations.
Transfer Learning for Structured Pruning under Limited Task Data
Nov 10, 2023



Large, pre-trained models are problematic to use in resource constrained applications. Fortunately, task-aware structured pruning methods offer a solution. These approaches reduce model size by dropping structural units like layers and attention heads in a manner that takes into account the end-task. However, these pruning algorithms require more task-specific data than is typically available. We propose a framework which combines structured pruning with transfer learning to reduce the need for task-specific data. Our empirical results answer questions such as: How should the two tasks be coupled? What parameters should be transferred? And, when during training should transfer learning be introduced? Leveraging these insights, we demonstrate that our framework results in pruned models with improved generalization over strong baselines.
Flashlight: Enabling Innovation in Tools for Machine Learning
Jan 29, 2022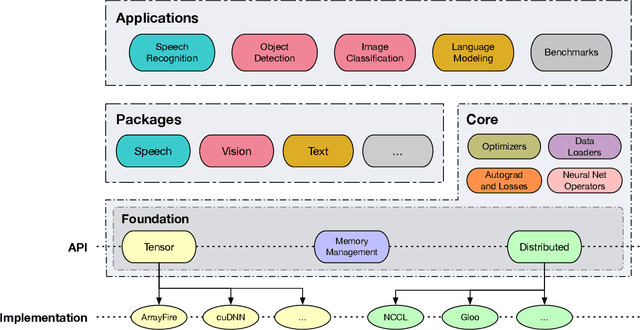
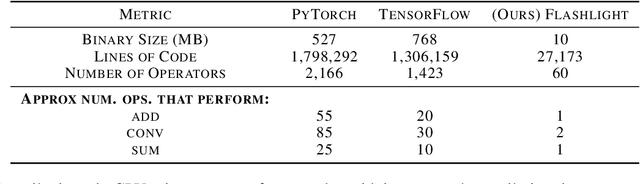
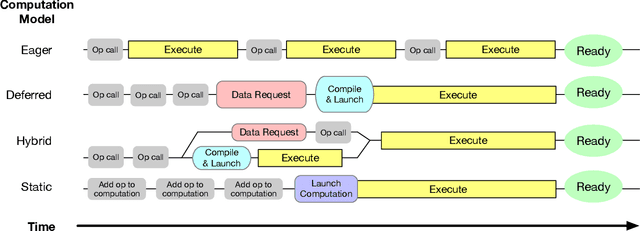
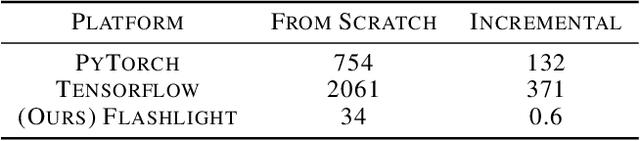
As the computational requirements for machine learning systems and the size and complexity of machine learning frameworks increases, essential framework innovation has become challenging. While computational needs have driven recent compiler, networking, and hardware advancements, utilization of those advancements by machine learning tools is occurring at a slower pace. This is in part due to the difficulties involved in prototyping new computational paradigms with existing frameworks. Large frameworks prioritize machine learning researchers and practitioners as end users and pay comparatively little attention to systems researchers who can push frameworks forward -- we argue that both are equally important stakeholders. We introduce Flashlight, an open-source library built to spur innovation in machine learning tools and systems by prioritizing open, modular, customizable internals and state-of-the-art, research-ready models and training setups across a variety of domains. Flashlight allows systems researchers to rapidly prototype and experiment with novel ideas in machine learning computation and has low overhead, competing with and often outperforming other popular machine learning frameworks. We see Flashlight as a tool enabling research that can benefit widely used libraries downstream and bring machine learning and systems researchers closer together.
Star Temporal Classification: Sequence Classification with Partially Labeled Data
Jan 28, 2022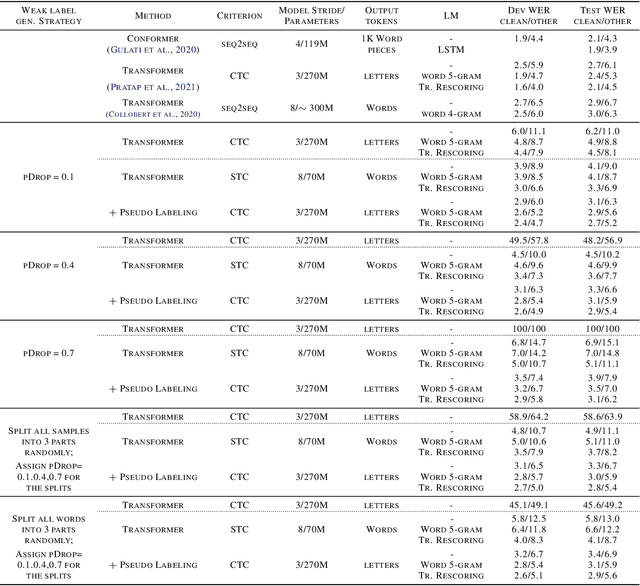
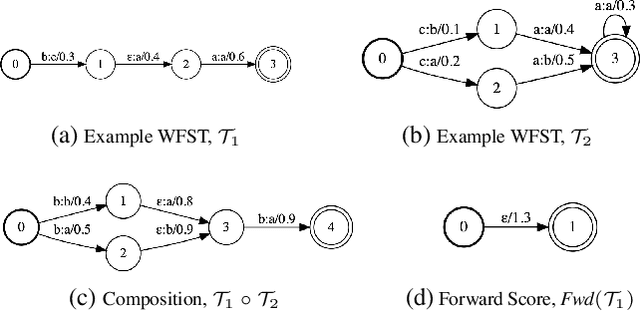
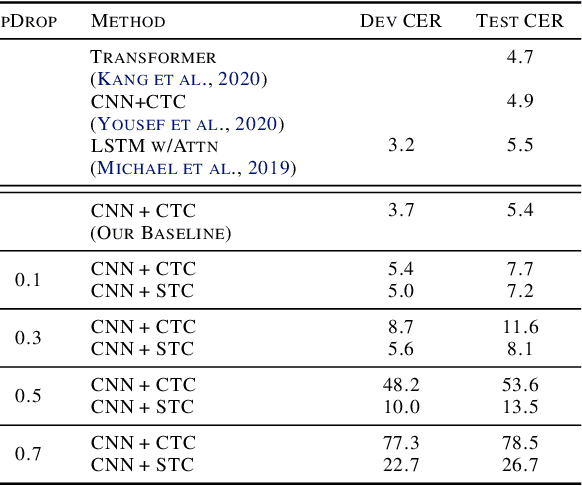
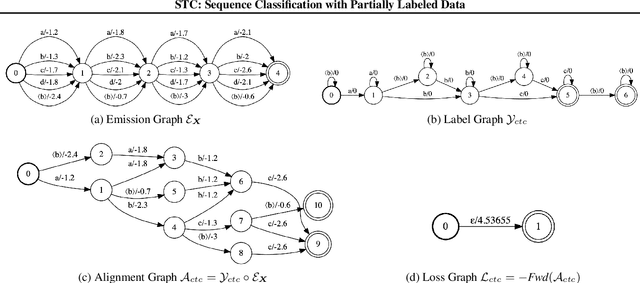
We develop an algorithm which can learn from partially labeled and unsegmented sequential data. Most sequential loss functions, such as Connectionist Temporal Classification (CTC), break down when many labels are missing. We address this problem with Star Temporal Classification (STC) which uses a special star token to allow alignments which include all possible tokens whenever a token could be missing. We express STC as the composition of weighted finite-state transducers (WFSTs) and use GTN (a framework for automatic differentiation with WFSTs) to compute gradients. We perform extensive experiments on automatic speech recognition. These experiments show that STC can recover most of the performance of supervised baseline when up to 70% of the labels are missing. We also perform experiments in handwriting recognition to show that our method easily applies to other sequence classification tasks.
Parallel Composition of Weighted Finite-State Transducers
Oct 06, 2021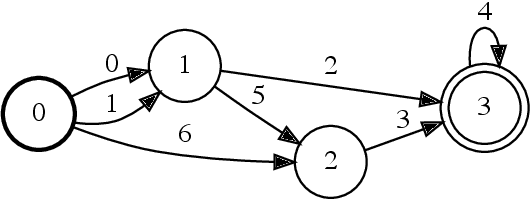
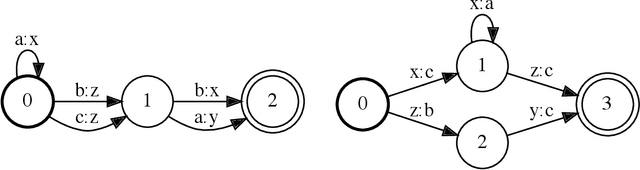


Finite-state transducers (FSTs) are frequently used in speech recognition. Transducer composition is an essential operation for combining different sources of information at different granularities. However, composition is also one of the more computationally expensive operations. Due to the heterogeneous structure of FSTs, parallel algorithms for composition are suboptimal in efficiency, generality, or both. We propose an algorithm for parallel composition and implement it on graphics processing units. We benchmark our parallel algorithm on the composition of random graphs and the composition of graphs commonly used in speech recognition. The parallel composition scales better with the size of the input graphs and for large graphs can be as much as 10 to 30 times faster than a sequential CPU algorithm.
CrypTen: Secure Multi-Party Computation Meets Machine Learning
Sep 02, 2021Secure multi-party computation (MPC) allows parties to perform computations on data while keeping that data private. This capability has great potential for machine-learning applications: it facilitates training of machine-learning models on private data sets owned by different parties, evaluation of one party's private model using another party's private data, etc. Although a range of studies implement machine-learning models via secure MPC, such implementations are not yet mainstream. Adoption of secure MPC is hampered by the absence of flexible software frameworks that "speak the language" of machine-learning researchers and engineers. To foster adoption of secure MPC in machine learning, we present CrypTen: a software framework that exposes popular secure MPC primitives via abstractions that are common in modern machine-learning frameworks, such as tensor computations, automatic differentiation, and modular neural networks. This paper describes the design of CrypTen and measure its performance on state-of-the-art models for text classification, speech recognition, and image classification. Our benchmarks show that CrypTen's GPU support and high-performance communication between (an arbitrary number of) parties allows it to perform efficient private evaluation of modern machine-learning models under a semi-honest threat model. For example, two parties using CrypTen can securely predict phonemes in speech recordings using Wav2Letter faster than real-time. We hope that CrypTen will spur adoption of secure MPC in the machine-learning community.
The History of Speech Recognition to the Year 2030
Jul 30, 2021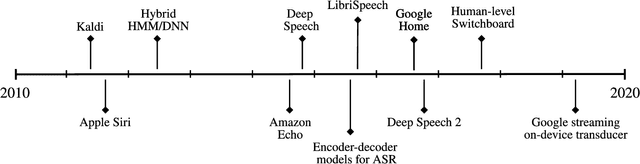

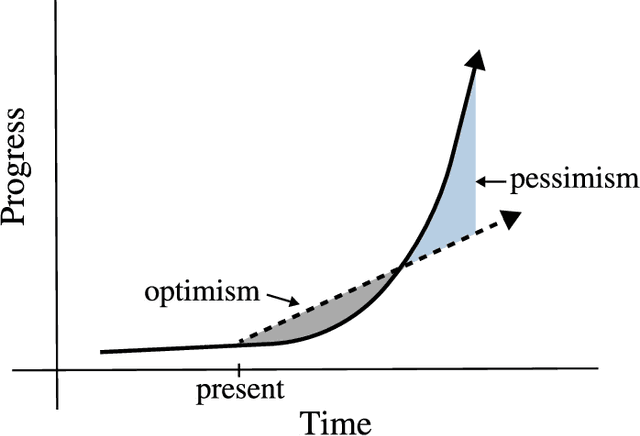
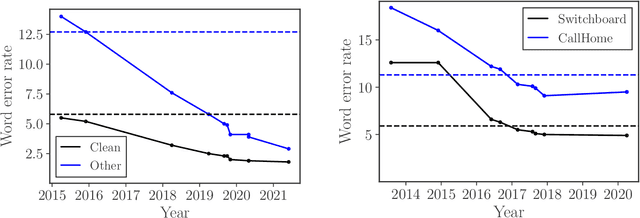
The decade from 2010 to 2020 saw remarkable improvements in automatic speech recognition. Many people now use speech recognition on a daily basis, for example to perform voice search queries, send text messages, and interact with voice assistants like Amazon Alexa and Siri by Apple. Before 2010 most people rarely used speech recognition. Given the remarkable changes in the state of speech recognition over the previous decade, what can we expect over the coming decade? I attempt to forecast the state of speech recognition research and applications by the year 2030. While the changes to general speech recognition accuracy will not be as dramatic as in the previous decade, I suggest we have an exciting decade of progress in speech technology ahead of us.
The Role of Evolution in Machine Intelligence
Jun 21, 2021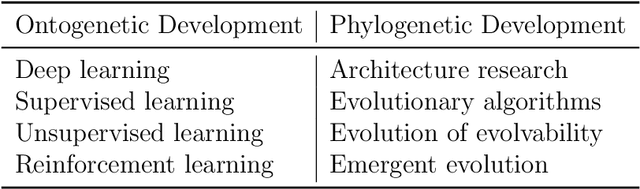
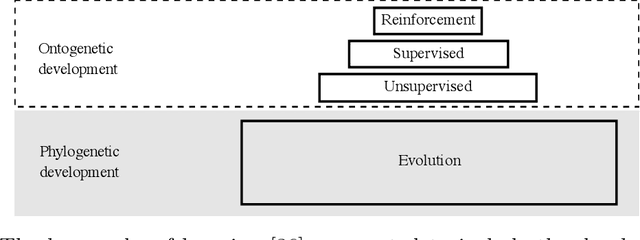
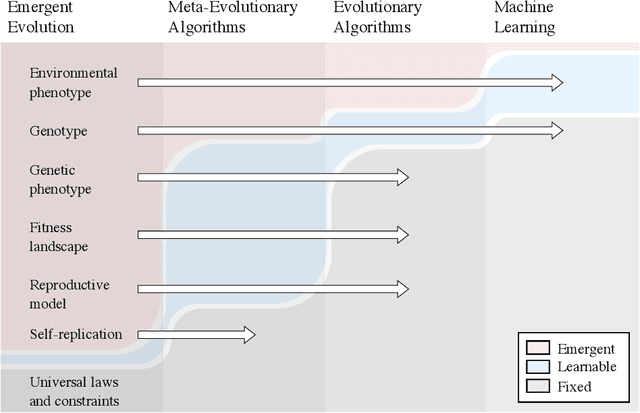
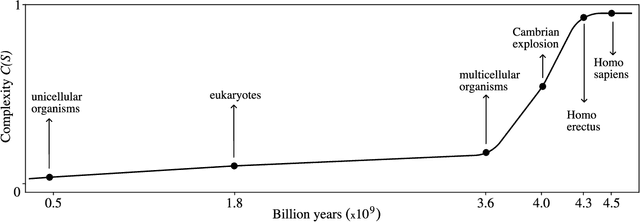
Machine intelligence can develop either directly from experience or by inheriting experience through evolution. The bulk of current research efforts focus on algorithms which learn directly from experience. I argue that the alternative, evolution, is important to the development of machine intelligence and underinvested in terms of research allocation. The primary aim of this work is to assess where along the spectrum of evolutionary algorithms to invest in research. My first-order suggestion is to diversify research across a broader spectrum of evolutionary approaches. I also define meta-evolutionary algorithms and argue that they may yield an optimal trade-off between the many factors influencing the development of machine intelligence.
Gradient Matching for Domain Generalization
Apr 20, 2021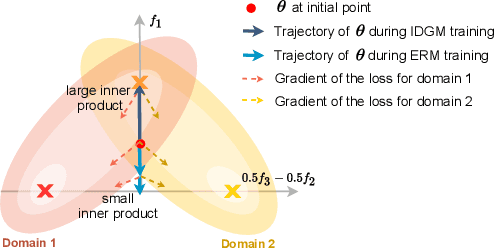


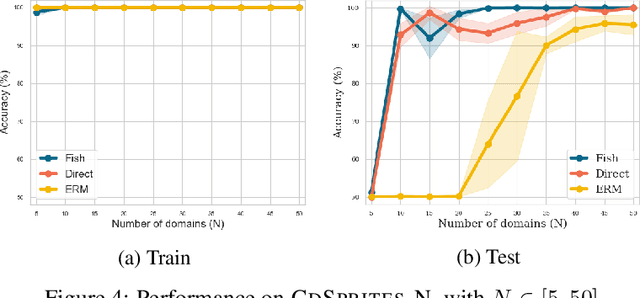
Machine learning systems typically assume that the distributions of training and test sets match closely. However, a critical requirement of such systems in the real world is their ability to generalize to unseen domains. Here, we propose an inter-domain gradient matching objective that targets domain generalization by maximizing the inner product between gradients from different domains. Since direct optimization of the gradient inner product can be computationally prohibitive -- requires computation of second-order derivatives -- we derive a simpler first-order algorithm named Fish that approximates its optimization. We demonstrate the efficacy of Fish on 6 datasets from the Wilds benchmark, which captures distribution shift across a diverse range of modalities. Our method produces competitive results on these datasets and surpasses all baselines on 4 of them. We perform experiments on both the Wilds benchmark, which captures distribution shift in the real world, as well as datasets in DomainBed benchmark that focuses more on synthetic-to-real transfer. Our method produces competitive results on both benchmarks, demonstrating its effectiveness across a wide range of domain generalization tasks.