 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Scaling Trends and Diminishing Returns in Large-Scale Distributed Training
Nov 20, 2024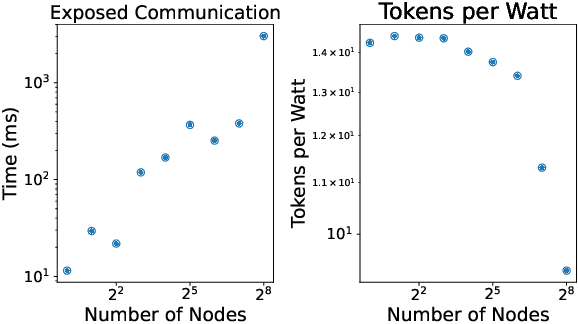

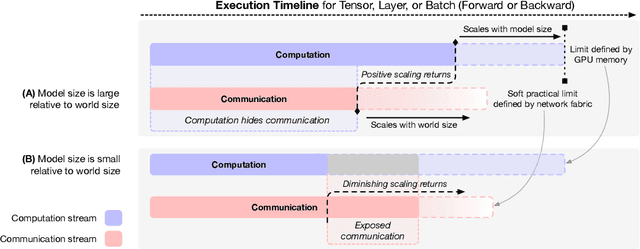
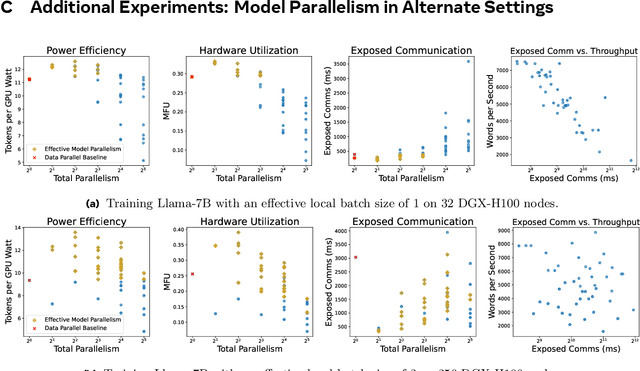
Dramatic increases in the capabilities of neural network models in recent years are driven by scaling model size, training data, and corresponding computational resources. To develop the exceedingly large networks required in modern applications, such as large language models (LLMs), model training is distributed across tens of thousands of hardware accelerators (e.g. GPUs), requiring orchestration of computation and communication across large computing clusters. In this work, we demonstrate that careful consideration of hardware configuration and parallelization strategy is critical for effective (i.e. compute- and cost-efficient) scaling of model size, training data, and total computation. We conduct an extensive empirical study of the performance of large-scale LLM training workloads across model size, hardware configurations, and distributed parallelization strategies. We demonstrate that: (1) beyond certain scales, overhead incurred from certain distributed communication strategies leads parallelization strategies previously thought to be sub-optimal in fact become preferable; and (2) scaling the total number of accelerators for large model training quickly yields diminishing returns even when hardware and parallelization strategies are properly optimized, implying poor marginal performance per additional unit of power or GPU-hour.
Revisiting Reliability in Large-Scale Machine Learning Research Clusters
Oct 29, 2024



Reliability is a fundamental challenge in operating large-scale machine learning (ML) infrastructures, particularly as the scale of ML models and training clusters continues to grow. Despite decades of research on infrastructure failures, the impact of job failures across different scales remains unclear. This paper presents a view of managing two large, multi-tenant ML clusters, providing quantitative analysis, operational experience, and our own perspective in understanding and addressing reliability concerns at scale. Our analysis reveals that while large jobs are most vulnerable to failures, smaller jobs make up the majority of jobs in the clusters and should be incorporated into optimization objectives. We identify key workload properties, compare them across clusters, and demonstrate essential reliability requirements for pushing the boundaries of ML training at scale. We hereby introduce a taxonomy of failures and key reliability metrics, analyze 11 months of data from two state-of-the-art ML environments with over 150 million A100 GPU hours and 4 million jobs. Building on our data, we fit a failure model to project Mean Time to Failure for various GPU scales. We further propose a method to estimate a related metric, Effective Training Time Ratio, as a function of job parameters, and we use this model to gauge the efficacy of potential software mitigations at scale. Our work provides valuable insights and future research directions for improving the reliability of AI supercomputer clusters, emphasizing the need for flexible, workload-agnostic, and reliability-aware infrastructure, system software, and algorithms.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.