 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauss-Newton Unlearning for the LLM Era
Feb 11, 2026Standard large language model training can create models that produce outputs their trainer deems unacceptable in deployment. The probability of these outputs can be reduced using methods such as LLM unlearning. However, unlearning a set of data (called the forget set) can degrade model performance on other distributions where the trainer wants to retain the model's behavior. To improve this trade-off, we demonstrate that using the forget set to compute only a few uphill Gauss-Newton steps provides a conceptually simple, state-of-the-art unlearning approach for LLMs. While Gauss-Newton steps adapt Newton's method to non-linear models, it is non-trivial to efficiently and accurately compute such steps for LLMs. Hence, our approach crucially relies on parametric Hessian approximations such as Kronecker-Factored Approximate Curvature (K-FAC). We call this combined approach K-FADE (K-FAC for Distribution Erasure). Our evaluation on the WMDP and ToFU benchmarks demonstrates that K-FADE suppresses outputs from the forget set and approximates, in output space, the results of retraining without the forget set. Critically, our method does this while altering the outputs on the retain set less than previous methods. This is because K-FADE transforms a constraint on the model's outputs across the entire retain set into a constraint on the model's weights, allowing the algorithm to minimally change the model's behavior on the retain set at each step. Moreover, the unlearning updates computed by K-FADE can be reapplied later if the model undergoes further training, allowing unlearning to be cheaply maintained.
Exploring Training Data Attribution under Limited Access Constraints
Sep 16, 2025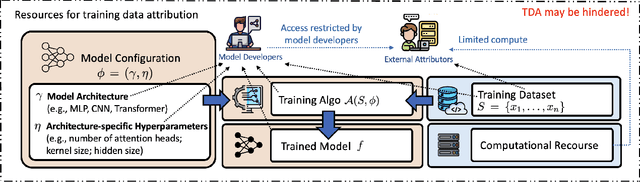
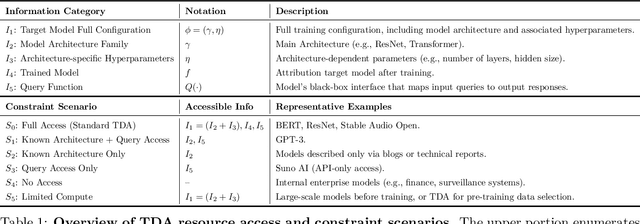
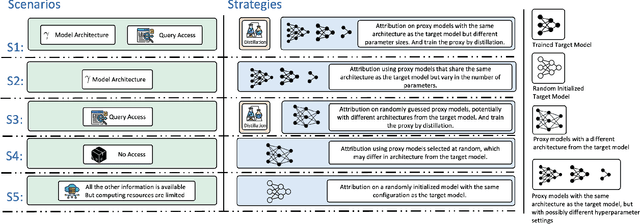

Training data attribution (TDA) plays a critical role in understanding the influence of individual training data points on model predictions. Gradient-based TDA methods, popularized by \textit{influence function} for their superior performance, have been widely applied in data selection, data cleaning, data economics, and fact tracing. However, in real-world scenarios where commercial models are not publicly accessible and computational resources are limited, existing TDA methods are often constrained by their reliance on full model access and high computational costs. This poses significant challenges to the broader adoption of TDA in practical applications. In this work, we present a systematic study of TDA methods under various access and resource constraints. We investigate the feasibility of performing TDA under varying levels of access constraints by leveraging appropriately designed solutions such as proxy models. Besides, we demonstrate that attribution scores obtained from models without prior training on the target dataset remain informative across a range of tasks, which is useful for scenarios where computational resources are limited. Our findings provide practical guidance for deploying TDA in real-world environments, aiming to improve feasibility and efficiency under limited access.
Accelerating Neural Network Training: An Analysis of the AlgoPerf Competition
Feb 20, 2025



The goal of the AlgoPerf: Training Algorithms competition is to evaluate practical speed-ups in neural network training achieved solely by improving the underlying training algorithms. In the external tuning ruleset, submissions must provide workload-agnostic hyperparameter search spaces, while in the self-tuning ruleset they must be completely hyperparameter-free. In both rulesets, submissions are compared on time-to-result across multiple deep learning workloads, training on fixed hardware. This paper presents the inaugural AlgoPerf competition's results, which drew 18 diverse submissions from 10 teams. Our investigation reveals several key findings: (1) The winning submission in the external tuning ruleset, using Distributed Shampoo, demonstrates the effectiveness of non-diagonal preconditioning over popular methods like Adam, even when compared on wall-clock runtime. (2) The winning submission in the self-tuning ruleset, based on the Schedule Free AdamW algorithm, demonstrates a new level of effectiveness for completely hyperparameter-free training algorithms. (3) The top-scoring submissions were surprisingly robust to workload changes. We also discuss the engineering challenges encountered in ensuring a fair comparison between different training algorithms. These results highlight both the significant progress so far, and the considerable room for further improvements.
Spectral-factorized Positive-definite Curvature Learning for NN Training
Feb 10, 2025Many training methods, such as Adam(W) and Shampoo, learn a positive-definite curvature matrix and apply an inverse root before preconditioning. Recently, non-diagonal training methods, such as Shampoo, have gained significant attention; however, they remain computationally inefficient and are limited to specific types of curvature information due to the costly matrix root computation via matrix decomposition. To address this, we propose a Riemannian optimization approach that dynamically adapts spectral-factorized positive-definite curvature estimates, enabling the efficient application of arbitrary matrix roots and generic curvature learning. We demonstrate the efficacy and versatility of our approach in positive-definite matrix optimization and covariance adaptation for gradient-free optimization, as well as its efficiency in curvature learning for neural net training.
Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models
Nov 19, 2024



The capabilities and limitations of Large Language Models have been sketched out in great detail in recent years, providing an intriguing yet conflicting picture. On the one hand, LLMs demonstrate a general ability to solve problems. On the other hand, they show surprising reasoning gaps when compared to humans, casting doubt on the robustness of their generalisation strategies. The sheer volume of data used in the design of LLMs has precluded us from applying the method traditionally used to measure generalisation: train-test set separation. To overcome this, we study what kind of generalisation strategies LLMs employ when performing reasoning tasks by investigating the pretraining data they rely on. For two models of different sizes (7B and 35B) and 2.5B of their pretraining tokens, we identify what documents influence the model outputs for three simple mathematical reasoning tasks and contrast this to the data that are influential for answering factual questions. We find that, while the models rely on mostly distinct sets of data for each factual question, a document often has a similar influence across different reasoning questions within the same task, indicating the presence of procedural knowledge. We further find that the answers to factual questions often show up in the most influential data. However, for reasoning questions the answers usually do not show up as highly influential, nor do the answers to the intermediate reasoning steps. When we characterise the top ranked documents for the reasoning questions qualitatively, we confirm that the influential documents often contain procedural knowledge, like demonstrating how to obtain a solution using formulae or code. Our findings indicate that the approach to reasoning the models use is unlike retrieval, and more like a generalisable strategy that synthesises procedural knowledge from documents doing a similar form of reasoning.
Influence Functions for Scalable Data Attribution in Diffusion Models
Oct 17, 2024Diffusion models have led to significant advancements in generative modelling. Yet their widespread adoption poses challenges regarding data attribution and interpretability. In this paper, we aim to help address such challenges in diffusion models by developing an \textit{influence functions} framework. Influence function-based data attribution methods approximate how a model's output would have changed if some training data were removed. In supervised learning, this is usually used for predicting how the loss on a particular example would change. For diffusion models, we focus on predicting the change in the probability of generating a particular example via several proxy measurements. We show how to formulate influence functions for such quantities and how previously proposed methods can be interpreted as particular design choices in our framework. To ensure scalability of the Hessian computations in influence functions, we systematically develop K-FAC approximations based on generalised Gauss-Newton matrices specifically tailored to diffusion models. We recast previously proposed methods as specific design choices in our framework and show that our recommended method outperforms previous data attribution approaches on common evaluations, such as the Linear Data-modelling Score (LDS) or retraining without top influences, without the need for method-specific hyperparameter tuning.
What is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
May 22, 2024



Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Training Data Attribution via Approximate Unrolled Differentiation
May 21, 2024



Many training data attribution (TDA) methods aim to estimate how a model's behavior would change if one or more data points were removed from the training set. Methods based on implicit differentiation, such as influence functions, can be made computationally efficient, but fail to account for underspecification, the implicit bias of the optimization algorithm, or multi-stage training pipelines. By contrast, methods based on unrolling address these issues but face scalability challenges. In this work, we connect the implicit-differentiation-based and unrolling-based approaches and combine their benefits by introducing Source, an approximate unrolling-based TDA method that is computed using an influence-function-like formula. While being computationally efficient compared to unrolling-based approaches, Source is suitable in cases where implicit-differentiation-based approaches struggle, such as in non-converged models and multi-stage training pipelines. Empirically, Source outperforms existing TDA techniques in counterfactual prediction, especially in settings where implicit-differentiation-based approaches fall short.
Can We Remove the Square-Root in Adaptive Gradient Methods? A Second-Order Perspective
Feb 13, 2024



Adaptive gradient optimizers like Adam(W) are the default training algorithms for many deep learning architectures, such as transformers. Their diagonal preconditioner is based on the gradient outer product which is incorporated into the parameter update via a square root. While these methods are often motivated as approximate second-order methods, the square root represents a fundamental difference. In this work, we investigate how the behavior of adaptive methods changes when we remove the root, i.e. strengthen their second-order motivation. Surprisingly, we find that such square-root-free adaptive methods close the generalization gap to SGD on convolutional architectures, while maintaining their root-based counterpart's performance on transformers. The second-order perspective also has practical benefits for the development of adaptive methods with non-diagonal preconditioner. In contrast to root-based counterparts like Shampoo, they do not require numerically unstable matrix square roots and therefore work well in low precision, which we demonstrate empirically. This raises important questions regarding the currently overlooked role of adaptivity for the success of adaptive methods since the success is often attributed to sign descent induced by the root.
Using Large Language Models for Hyperparameter Optimization
Dec 07, 2023



This paper studies using foundational large language models (LLMs) to make decisions during hyperparameter optimization (HPO). Empirical evaluations demonstrate that in settings with constrained search budgets, LLMs can perform comparably or better than traditional HPO methods like random search and Bayesian optimization on standard benchmarks. Furthermore, we propose to treat the code specifying our model as a hyperparameter, which the LLM outputs, going beyond the capabilities of existing HPO approaches. Our findings suggest that LLMs are a promising tool for improving efficiency in the traditional decision-making problem of hyperparameter optimization.