 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Trained MoE Can Skip Half Experts via Self-Distillation
May 18, 2026Mixture-of-Experts (MoE) scales language models efficiently through sparse expert activation, and its dynamic variant further reduces computation by adjusting the activated experts in an input-dependent manner. Existing dynamic MoE methods usually rely on pre-training from scratch or task-specific adaptation, leaving the practical conversion of fully trained MoE underexplored. Enabling such adaptation would directly alleviate the inference costs by allowing easy tokens to bypass unnecessary expert during serving. This paper introduces Zero-Expert Self-Distillation Adaptation (ZEDA), a low-cost framework that transforms post-trained static MoE models into efficient dynamic ones. To stabilize this architectural conversion, ZEDA injects parameter-free zero-output experts into each MoE layer and adapts the augmented model through two-stage self-distillation, utilizing the original MoE as a frozen teacher and applying a group-level balancing loss. On Qwen3-30B-A3B and GLM-4.7-Flash across 11 benchmarks spanning math, code, and instruction following, ZEDA eliminates over 50% of expert FLOPs at marginal accuracy loss. It outperforms the strongest dynamic MoE baseline by 6.1 and 4.0 points on the two models, and delivers ~1.20$\times$ end-to-end inference speedup.
How Far Can Unsupervised RLVR Scale LLM Training?
Mar 09, 2026Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
Finite-Time Analysis of Stochastic Nonconvex Nonsmooth Optimization on the Riemannian Manifolds
Oct 24, 2025
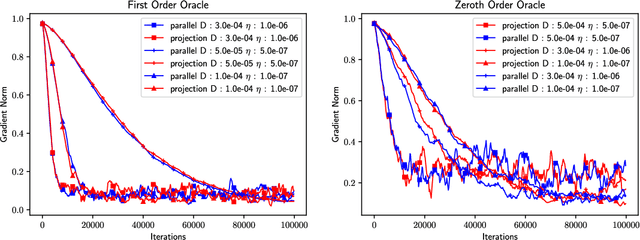
This work addresses the finite-time analysis of nonsmooth nonconvex stochastic optimization under Riemannian manifold constraints. We adapt the notion of Goldstein stationarity to the Riemannian setting as a performance metric for nonsmooth optimization on manifolds. We then propose a Riemannian Online to NonConvex (RO2NC) algorithm, for which we establish the sample complexity of $O(\epsilon^{-3}\delta^{-1})$ in finding $(\delta,\epsilon)$-stationary points. This result is the first-ever finite-time guarantee for fully nonsmooth, nonconvex optimization on manifolds and matches the optimal complexity in the Euclidean setting. When gradient information is unavailable, we develop a zeroth order version of RO2NC algorithm (ZO-RO2NC), for which we establish the same sample complexity. The numerical results support the theory and demonstrate the practical effectiveness of the algorithms.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Sep 11, 2025Vision-Language-Action (VLA) models have recently emerged as a powerful paradigm for robotic manipulation. Despite substantial progress enabled by large-scale pretraining and supervised fine-tuning (SFT), these models face two fundamental challenges: (i) the scarcity and high cost of large-scale human-operated robotic trajectories required for SFT scaling, and (ii) limited generalization to tasks involving distribution shift. Recent breakthroughs in Large Reasoning Models (LRMs) demonstrate that reinforcement learning (RL) can dramatically enhance step-by-step reasoning capabilities, raising a natural question: Can RL similarly improve the long-horizon step-by-step action planning of VLA? In this work, we introduce SimpleVLA-RL, an efficient RL framework tailored for VLA models. Building upon veRL, we introduce VLA-specific trajectory sampling, scalable parallelization, multi-environment rendering, and optimized loss computation. When applied to OpenVLA-OFT, SimpleVLA-RL achieves SoTA performance on LIBERO and even outperforms $\pi_0$ on RoboTwin 1.0\&2.0 with the exploration-enhancing strategies we introduce. SimpleVLA-RL not only reduces dependence on large-scale data and enables robust generalization, but also remarkably surpasses SFT in real-world tasks. Moreover, we identify a novel phenomenon ``pushcut'' during RL training, wherein the policy discovers previously unseen patterns beyond those seen in the previous training process. Github: https://github.com/PRIME-RL/SimpleVLA-RL
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
Towards a Unified View of Large Language Model Post-Training
Sep 04, 2025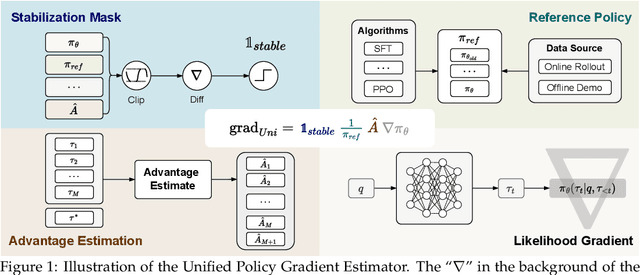

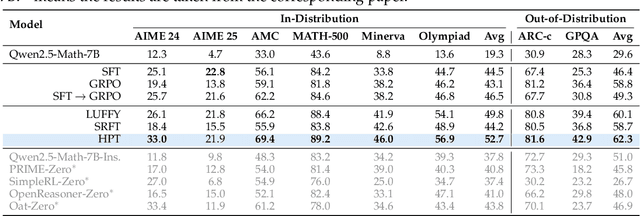
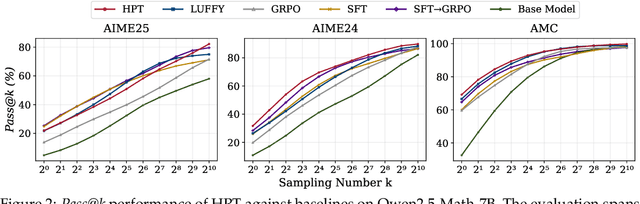
Two major sources of training data exist for post-training modern language models: online (model-generated rollouts) data, and offline (human or other-model demonstrations) data. These two types of data are typically used by approaches like Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT), respectively. In this paper, we show that these approaches are not in contradiction, but are instances of a single optimization process. We derive a Unified Policy Gradient Estimator, and present the calculations of a wide spectrum of post-training approaches as the gradient of a common objective under different data distribution assumptions and various bias-variance tradeoffs. The gradient estimator is constructed with four interchangeable parts: stabilization mask, reference policy denominator, advantage estimate, and likelihood gradient. Motivated by our theoretical findings, we propose Hybrid Post-Training (HPT), an algorithm that dynamically selects different training signals. HPT is designed to yield both effective exploitation of demonstration and stable exploration without sacrificing learned reasoning patterns. We provide extensive experiments and ablation studies to verify the effectiveness of our unified theoretical framework and HPT. Across six mathematical reasoning benchmarks and two out-of-distribution suites, HPT consistently surpasses strong baselines across models of varying scales and families.
Automating Exploratory Multiomics Research via Language Models
Jun 09, 2025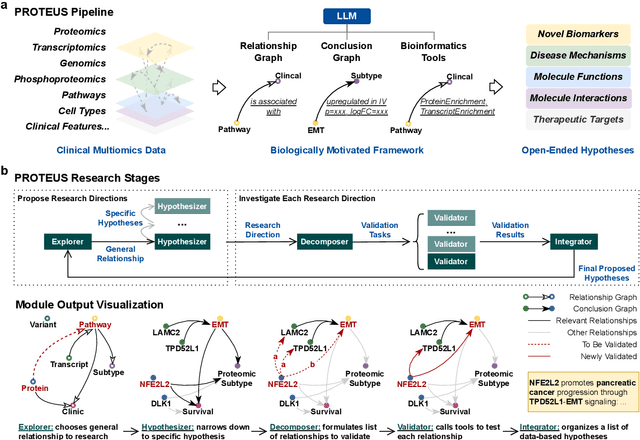
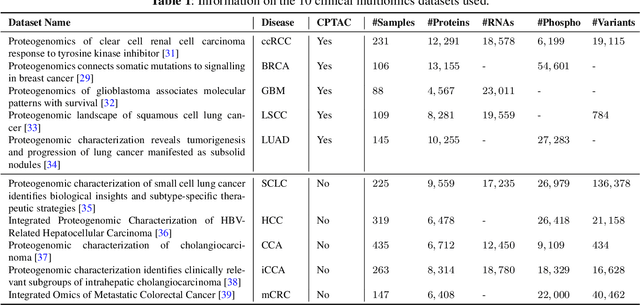
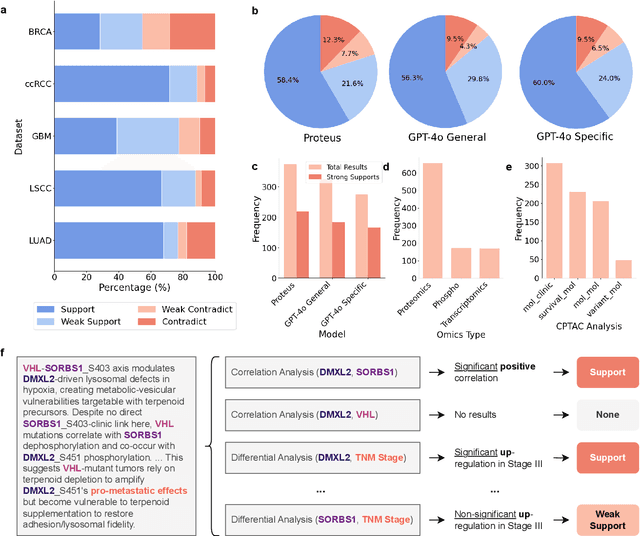

This paper introduces PROTEUS, a fully automated system that produces data-driven hypotheses from raw data files. We apply PROTEUS to clinical proteogenomics, a field where effective downstream data analysis and hypothesis proposal is crucial for producing novel discoveries. PROTEUS uses separate modules to simulate different stages of the scientific process, from open-ended data exploration to specific statistical analysis and hypothesis proposal. It formulates research directions, tools, and results in terms of relationships between biological entities, using unified graph structures to manage complex research processes. We applied PROTEUS to 10 clinical multiomics datasets from published research, arriving at 360 total hypotheses. Results were evaluated through external data validation and automatic open-ended scoring. Through exploratory and iterative research, the system can navigate high-throughput and heterogeneous multiomics data to arrive at hypotheses that balance reliability and novelty. In addition to accelerating multiomic analysis, PROTEUS represents a path towards tailoring general autonomous systems to specialized scientific domains to achieve open-ended hypothesis generation from data.
TTRL: Test-Time Reinforcement Learning
Apr 22, 2025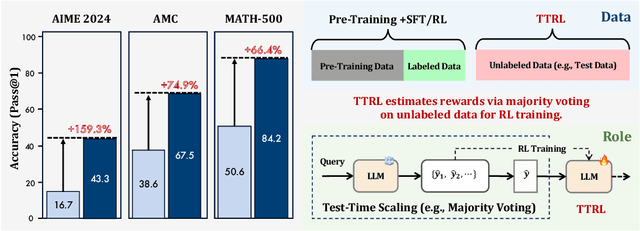
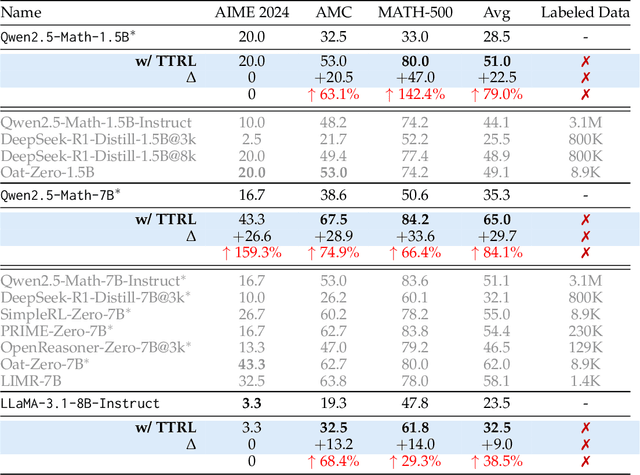
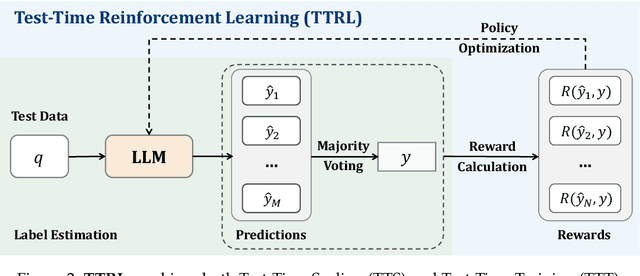
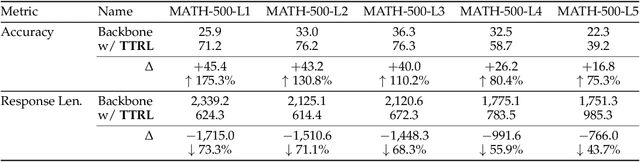
This paper investigates Reinforcement Learning (RL) on data without explicit labels for reasoning tasks in Large Language Models (LLMs). The core challenge of the problem is reward estimation during inference while not having access to ground-truth information. While this setting appears elusive, we find that common practices in Test-Time Scaling (TTS), such as majority voting, yield surprisingly effective rewards suitable for driving RL training. In this work, we introduce Test-Time Reinforcement Learning (TTRL), a novel method for training LLMs using RL on unlabeled data. TTRL enables self-evolution of LLMs by utilizing the priors in the pre-trained models. Our experiments demonstrate that TTRL consistently improves performance across a variety of tasks and models. Notably, TTRL boosts the pass@1 performance of Qwen-2.5-Math-7B by approximately 159% on the AIME 2024 with only unlabeled test data. Furthermore, although TTRL is only supervised by the Maj@N metric, TTRL has demonstrated performance to consistently surpass the upper limit of the initial model, and approach the performance of models trained directly on test data with ground-truth labels. Our experimental findings validate the general effectiveness of TTRL across various tasks, and highlight TTRL's potential for broader tasks and domains. GitHub: https://github.com/PRIME-RL/TTRL
Technologies on Effectiveness and Efficiency: A Survey of State Spaces Models
Mar 14, 2025



State Space Models (SSMs) have emerged as a promising alternative to the popular transformer-based models and have been increasingly gaining attention. Compared to transformers, SSMs excel at tasks with sequential data or longer contexts, demonstrating comparable performances with significant efficiency gains. In this survey, we provide a coherent and systematic overview for SSMs, including their theoretical motivations, mathematical formulations, comparison with existing model classes, and various applications. We divide the SSM series into three main sections, providing a detailed introduction to the original SSM, the structured SSM represented by S4, and the selective SSM typified by Mamba. We put an emphasis on technicality, and highlight the various key techniques introduced to address the effectiveness and efficiency of SSMs. We hope this manuscript serves as an introduction for researchers to explore the theoretical foundations of SSMs.