 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate de novo sequencing of the modified proteome with OmniNovo
Dec 13, 2025Post-translational modifications (PTMs) serve as a dynamic chemical language regulating protein function, yet current proteomic methods remain blind to a vast portion of the modified proteome. Standard database search algorithms suffer from a combinatorial explosion of search spaces, limiting the identification of uncharacterized or complex modifications. Here we introduce OmniNovo, a unified deep learning framework for reference-free sequencing of unmodified and modified peptides directly from tandem mass spectra. Unlike existing tools restricted to specific modification types, OmniNovo learns universal fragmentation rules to decipher diverse PTMs within a single coherent model. By integrating a mass-constrained decoding algorithm with rigorous false discovery rate estimation, OmniNovo achieves state-of-the-art accuracy, identifying 51\% more peptides than standard approaches at a 1\% false discovery rate. Crucially, the model generalizes to biological sites unseen during training, illuminating the dark matter of the proteome and enabling unbiased comprehensive analysis of cellular regulation.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
Automating Exploratory Multiomics Research via Language Models
Jun 09, 2025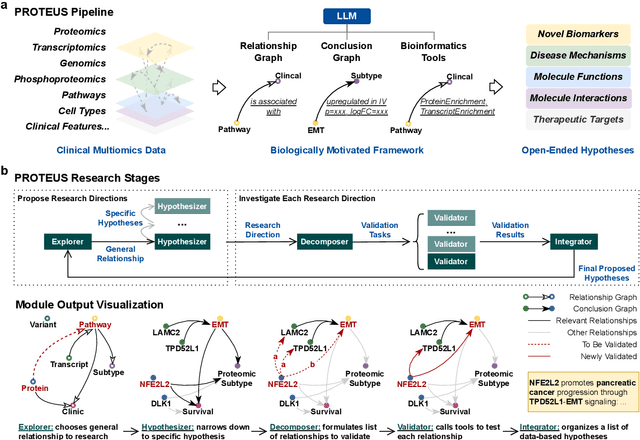
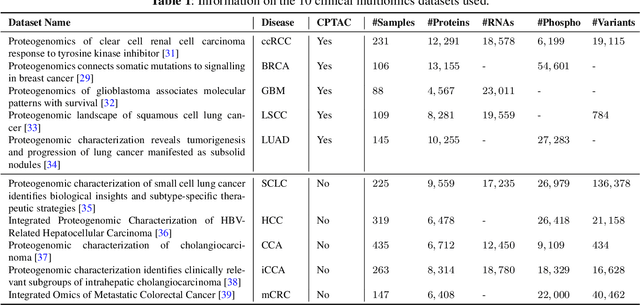
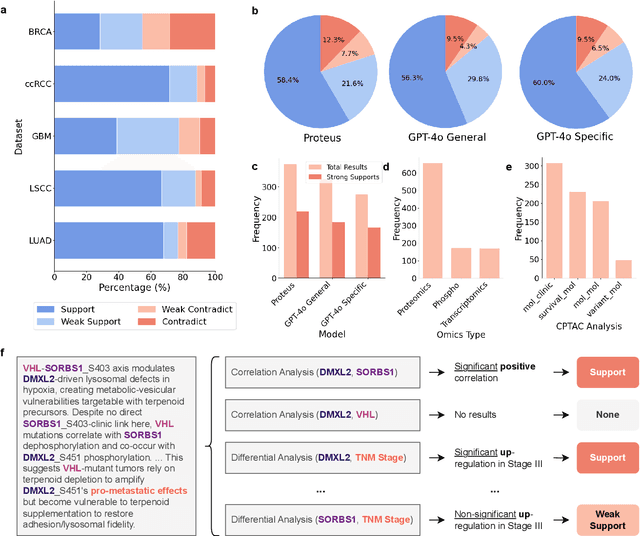

This paper introduces PROTEUS, a fully automated system that produces data-driven hypotheses from raw data files. We apply PROTEUS to clinical proteogenomics, a field where effective downstream data analysis and hypothesis proposal is crucial for producing novel discoveries. PROTEUS uses separate modules to simulate different stages of the scientific process, from open-ended data exploration to specific statistical analysis and hypothesis proposal. It formulates research directions, tools, and results in terms of relationships between biological entities, using unified graph structures to manage complex research processes. We applied PROTEUS to 10 clinical multiomics datasets from published research, arriving at 360 total hypotheses. Results were evaluated through external data validation and automatic open-ended scoring. Through exploratory and iterative research, the system can navigate high-throughput and heterogeneous multiomics data to arrive at hypotheses that balance reliability and novelty. In addition to accelerating multiomic analysis, PROTEUS represents a path towards tailoring general autonomous systems to specialized scientific domains to achieve open-ended hypothesis generation from data.
TTRL: Test-Time Reinforcement Learning
Apr 22, 2025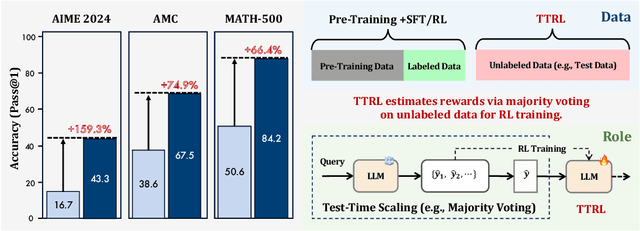
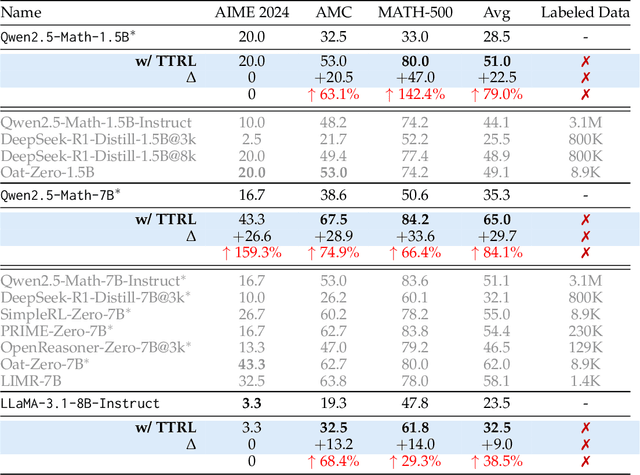
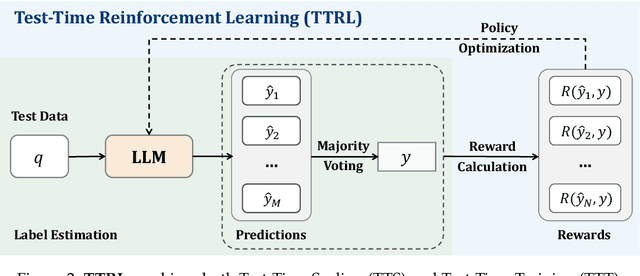
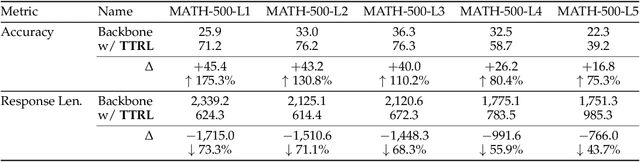
This paper investigates Reinforcement Learning (RL) on data without explicit labels for reasoning tasks in Large Language Models (LLMs). The core challenge of the problem is reward estimation during inference while not having access to ground-truth information. While this setting appears elusive, we find that common practices in Test-Time Scaling (TTS), such as majority voting, yield surprisingly effective rewards suitable for driving RL training. In this work, we introduce Test-Time Reinforcement Learning (TTRL), a novel method for training LLMs using RL on unlabeled data. TTRL enables self-evolution of LLMs by utilizing the priors in the pre-trained models. Our experiments demonstrate that TTRL consistently improves performance across a variety of tasks and models. Notably, TTRL boosts the pass@1 performance of Qwen-2.5-Math-7B by approximately 159% on the AIME 2024 with only unlabeled test data. Furthermore, although TTRL is only supervised by the Maj@N metric, TTRL has demonstrated performance to consistently surpass the upper limit of the initial model, and approach the performance of models trained directly on test data with ground-truth labels. Our experimental findings validate the general effectiveness of TTRL across various tasks, and highlight TTRL's potential for broader tasks and domains. GitHub: https://github.com/PRIME-RL/TTRL
Technologies on Effectiveness and Efficiency: A Survey of State Spaces Models
Mar 14, 2025



State Space Models (SSMs) have emerged as a promising alternative to the popular transformer-based models and have been increasingly gaining attention. Compared to transformers, SSMs excel at tasks with sequential data or longer contexts, demonstrating comparable performances with significant efficiency gains. In this survey, we provide a coherent and systematic overview for SSMs, including their theoretical motivations, mathematical formulations, comparison with existing model classes, and various applications. We divide the SSM series into three main sections, providing a detailed introduction to the original SSM, the structured SSM represented by S4, and the selective SSM typified by Mamba. We put an emphasis on technicality, and highlight the various key techniques introduced to address the effectiveness and efficiency of SSMs. We hope this manuscript serves as an introduction for researchers to explore the theoretical foundations of SSMs.
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
Jan 30, 2025We introduce MedXpertQA, a highly challenging and comprehensive benchmark to evaluate expert-level medical knowledge and advanced reasoning. MedXpertQA includes 4,460 questions spanning 17 specialties and 11 body systems. It includes two subsets, Text for text evaluation and MM for multimodal evaluation. Notably, MM introduces expert-level exam questions with diverse images and rich clinical information, including patient records and examination results, setting it apart from traditional medical multimodal benchmarks with simple QA pairs generated from image captions. MedXpertQA applies rigorous filtering and augmentation to address the insufficient difficulty of existing benchmarks like MedQA, and incorporates specialty board questions to improve clinical relevance and comprehensiveness. We perform data synthesis to mitigate data leakage risk and conduct multiple rounds of expert reviews to ensure accuracy and reliability. We evaluate 16 leading models on MedXpertQA. Moreover, medicine is deeply connected to real-world decision-making, providing a rich and representative setting for assessing reasoning abilities beyond mathematics and code. To this end, we develop a reasoning-oriented subset to facilitate the assessment of o1-like models.
Automating Exploratory Proteomics Research via Language Models
Nov 06, 2024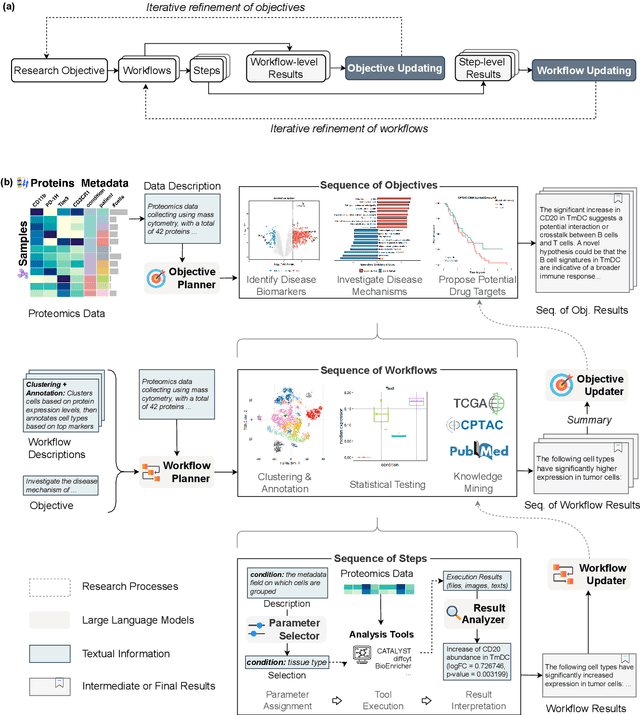
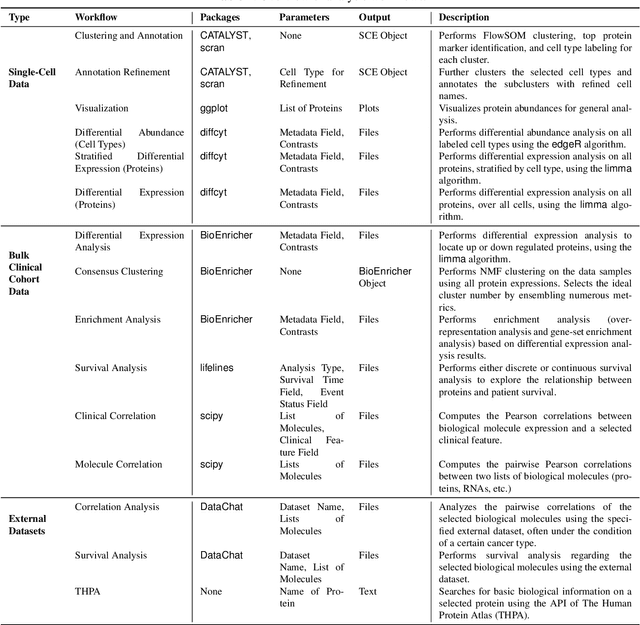
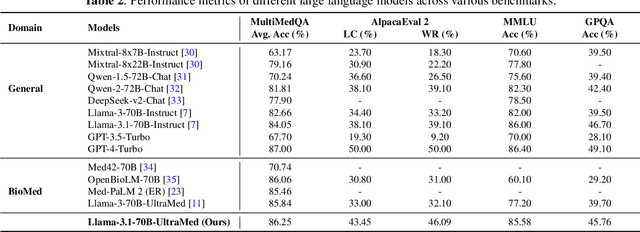
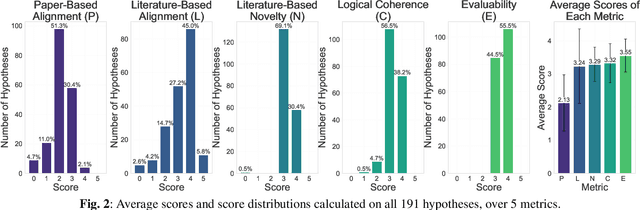
With the development of artificial intelligence, its contribution to science is evolving from simulating a complex problem to automating entire research processes and producing novel discoveries. Achieving this advancement requires both specialized general models grounded in real-world scientific data and iterative, exploratory frameworks that mirror human scientific methodologies. In this paper, we present PROTEUS, a fully automated system for scientific discovery from raw proteomics data. PROTEUS uses large language models (LLMs) to perform hierarchical planning, execute specialized bioinformatics tools, and iteratively refine analysis workflows to generate high-quality scientific hypotheses. The system takes proteomics datasets as input and produces a comprehensive set of research objectives, analysis results, and novel biological hypotheses without human intervention. We evaluated PROTEUS on 12 proteomics datasets collected from various biological samples (e.g. immune cells, tumors) and different sample types (single-cell and bulk), generating 191 scientific hypotheses. These were assessed using both automatic LLM-based scoring on 5 metrics and detailed reviews from human experts. Results demonstrate that PROTEUS consistently produces reliable, logically coherent results that align well with existing literature while also proposing novel, evaluable hypotheses. The system's flexible architecture facilitates seamless integration of diverse analysis tools and adaptation to different proteomics data types. By automating complex proteomics analysis workflows and hypothesis generation, PROTEUS has the potential to considerably accelerate the pace of scientific discovery in proteomics research, enabling researchers to efficiently explore large-scale datasets and uncover biological insights.
Curriculum-Driven Edubot: A Framework for Developing Language Learning Chatbots Through Synthesizing Conversational Data
Sep 28, 2023Chatbots have become popular in educational settings, revolutionizing how students interact with material and how teachers teach. We present Curriculum-Driven EduBot, a framework for developing a chatbot that combines the interactive features of chatbots with the systematic material of English textbooks to assist students in enhancing their conversational skills. We begin by extracting pertinent topics from textbooks and then using large language models to generate dialogues related to these topics. We then fine-tune an open-source LLM using our generated conversational data to create our curriculum-driven chatbot. User studies demonstrate that our chatbot outperforms ChatGPT in leading curriculum-based dialogues and adapting its dialogue to match the user's English proficiency level. By combining traditional textbook methodologies with conversational AI, our approach offers learners an interactive tool that aligns with their curriculum and provides user-tailored conversation practice. This facilitates meaningful student-bot dialogues and enriches the overall learning experience within the curriculum's pedagogical framework.
Reformulating Sequential Recommendation: Learning Dynamic User Interest with Content-enriched Language Modeling
Sep 19, 2023



Recommender systems are essential for online applications, and sequential recommendation has enjoyed significant prevalence due to its expressive ability to capture dynamic user interests. However, previous sequential modeling methods still have limitations in capturing contextual information. The primary reason for this issue is that language models often lack an understanding of domain-specific knowledge and item-related textual content. To address this issue, we adopt a new sequential recommendation paradigm and propose LANCER, which leverages the semantic understanding capabilities of pre-trained language models to generate personalized recommendations. Our approach bridges the gap between language models and recommender systems, resulting in more human-like recommendations. We demonstrate the effectiveness of our approach through experiments on several benchmark datasets, showing promising results and providing valuable insights into the influence of our model on sequential recommendation tasks. Furthermore, our experimental codes are publicly available.