 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPER: Hierarchical Reinforcement Learning with Explicit Credit Assignment for Large Language Model Agents
Feb 18, 2026Training LLMs as interactive agents for multi-turn decision-making remains challenging, particularly in long-horizon tasks with sparse and delayed rewards, where agents must execute extended sequences of actions before receiving meaningful feedback. Most existing reinforcement learning (RL) approaches model LLM agents as flat policies operating at a single time scale, selecting one action at each turn. In sparse-reward settings, such flat policies must propagate credit across the entire trajectory without explicit temporal abstraction, which often leads to unstable optimization and inefficient credit assignment. We propose HiPER, a novel Hierarchical Plan-Execute RL framework that explicitly separates high-level planning from low-level execution. HiPER factorizes the policy into a high-level planner that proposes subgoals and a low-level executor that carries them out over multiple action steps. To align optimization with this structure, we introduce a key technique called hierarchical advantage estimation (HAE), which carefully assigns credit at both the planning and execution levels. By aggregating returns over the execution of each subgoal and coordinating updates across the two levels, HAE provides an unbiased gradient estimator and provably reduces variance compared to flat generalized advantage estimation. Empirically, HiPER achieves state-of-the-art performance on challenging interactive benchmarks, reaching 97.4\% success on ALFWorld and 83.3\% on WebShop with Qwen2.5-7B-Instruct (+6.6\% and +8.3\% over the best prior method), with especially large gains on long-horizon tasks requiring multiple dependent subtasks. These results highlight the importance of explicit hierarchical decomposition for scalable RL training of multi-turn LLM agents.
Local Linear Convergence of Infeasible Optimization with Orthogonal Constraints
Dec 07, 2024Many classical and modern machine learning algorithms require solving optimization tasks under orthogonality constraints. Solving these tasks with feasible methods requires a gradient descent update followed by a retraction operation on the Stiefel manifold, which can be computationally expensive. Recently, an infeasible retraction-free approach, termed the landing algorithm, was proposed as an efficient alternative. Motivated by the common occurrence of orthogonality constraints in tasks such as principle component analysis and training of deep neural networks, this paper studies the landing algorithm and establishes a novel linear convergence rate for smooth non-convex functions using only a local Riemannian P{\L} condition. Numerical experiments demonstrate that the landing algorithm performs on par with the state-of-the-art retraction-based methods with substantially reduced computational overhead.
Distributed Networked Multi-task Learning
Oct 04, 2024


We consider a distributed multi-task learning scheme that accounts for multiple linear model estimation tasks with heterogeneous and/or correlated data streams. We assume that nodes can be partitioned into groups corresponding to different learning tasks and communicate according to a directed network topology. Each node estimates a linear model asynchronously and is subject to local (within-group) regularization and global (across groups) regularization terms targeting noise reduction and generalization performance improvement respectively. We provide a finite-time characterization of convergence of the estimators and task relation and illustrate the scheme's general applicability in two examples: random field temperature estimation and modeling student performance from different academic districts.
FedGlu: A personalized federated learning-based glucose forecasting algorithm for improved performance in glycemic excursion regions
Aug 25, 2024Continuous glucose monitoring (CGM) devices provide real-time glucose monitoring and timely alerts for glycemic excursions, improving glycemic control among patients with diabetes. However, identifying rare events like hypoglycemia and hyperglycemia remain challenging due to their infrequency. Moreover, limited access to sensitive patient data hampers the development of robust machine learning models. Our objective is to accurately predict glycemic excursions while addressing data privacy concerns. To tackle excursion prediction, we propose a novel Hypo-Hyper (HH) loss function, which significantly improves performance in the glycemic excursion regions. The HH loss function demonstrates a 46% improvement over mean-squared error (MSE) loss across 125 patients. To address privacy concerns, we propose FedGlu, a machine learning model trained in a federated learning (FL) framework. FL allows collaborative learning without sharing sensitive data by training models locally and sharing only model parameters across other patients. FedGlu achieves a 35% superior glycemic excursion detection rate compared to local models. This improvement translates to enhanced performance in predicting both, hypoglycemia and hyperglycemia, for 105 out of 125 patients. These results underscore the effectiveness of the proposed HH loss function in augmenting the predictive capabilities of glucose predictions. Moreover, implementing models within a federated learning framework not only ensures better predictive capabilities but also safeguards sensitive data concurrently.
Joint Demonstration and Preference Learning Improves Policy Alignment with Human Feedback
Jun 11, 2024Aligning human preference and value is an important requirement for building contemporary foundation models and embodied AI. However, popular approaches such as reinforcement learning with human feedback (RLHF) break down the task into successive stages, such as supervised fine-tuning (SFT), reward modeling (RM), and reinforcement learning (RL), each performing one specific learning task. Such a sequential approach results in serious issues such as significant under-utilization of data and distribution mismatch between the learned reward model and generated policy, which eventually lead to poor alignment performance. We develop a single stage approach named Alignment with Integrated Human Feedback (AIHF), capable of integrating both human preference and demonstration to train reward models and the policy. The proposed approach admits a suite of efficient algorithms, which can easily reduce to, and leverage, popular alignment algorithms such as RLHF and Directly Policy Optimization (DPO), and only requires minor changes to the existing alignment pipelines. We demonstrate the efficiency of the proposed solutions with extensive experiments involving alignment problems in LLMs and robotic control problems in MuJoCo. We observe that the proposed solutions outperform the existing alignment algorithms such as RLHF and DPO by large margins, especially when the amount of high-quality preference data is relatively limited.
Getting More Juice Out of the SFT Data: Reward Learning from Human Demonstration Improves SFT for LLM Alignment
May 29, 2024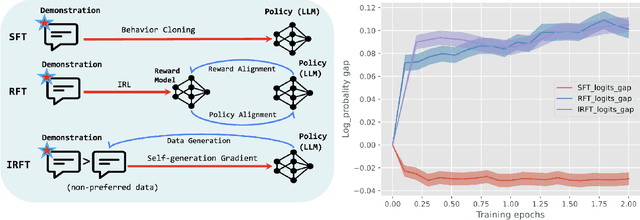

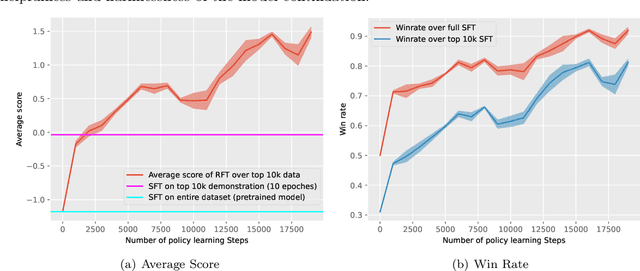
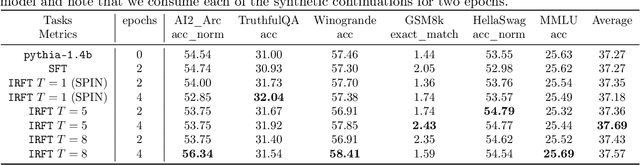
Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to (explicitly or implicitly) build an reward model, while learning the policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but also promote the ability to distinguish between the preferred and non-preferred continuations. Moreover, we identify a connection between the proposed IRL based approach, and certain self-play approach proposed recently, and showed that self-play is a special case of modeling a reward-learning agent. Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to explicitly or implicitly leverage reward learning throughout the entire alignment process.
Global Convergence of Decentralized Retraction-Free Optimization on the Stiefel Manifold
May 19, 2024Many classical and modern machine learning algorithms require solving optimization tasks under orthogonal constraints. Solving these tasks often require calculating retraction-based gradient descent updates on the corresponding Riemannian manifold, which can be computationally expensive. Recently Ablin et al. proposed an infeasible retraction-free algorithm, which is significantly more efficient. In this paper, we study the decentralized non-convex optimization task over a network of agents on the Stiefel manifold with retraction-free updates. We propose \textbf{D}ecentralized \textbf{R}etraction-\textbf{F}ree \textbf{G}radient \textbf{T}racking (DRFGT) algorithm, and show that DRFGT exhibits ergodic $\mathcal{O}(1/K)$ convergence rate, the same rate of convergence as the centralized, retraction-based methods. We also provide numerical experiments demonstrating that DRFGT performs on par with the state-of-the-art retraction based methods with substantially reduced computational overhead.
Regularized Q-Learning with Linear Function Approximation
Jan 26, 2024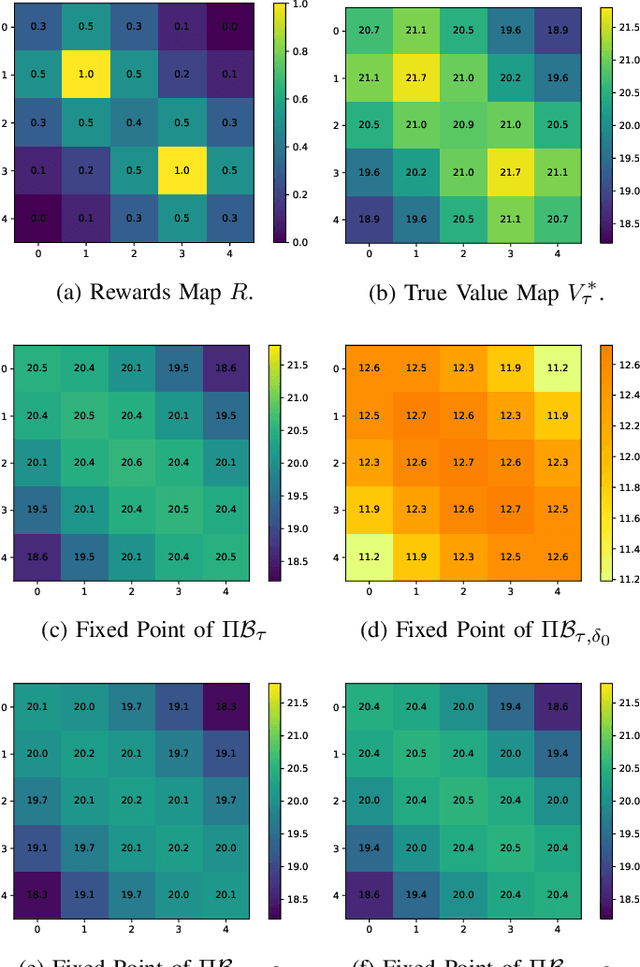
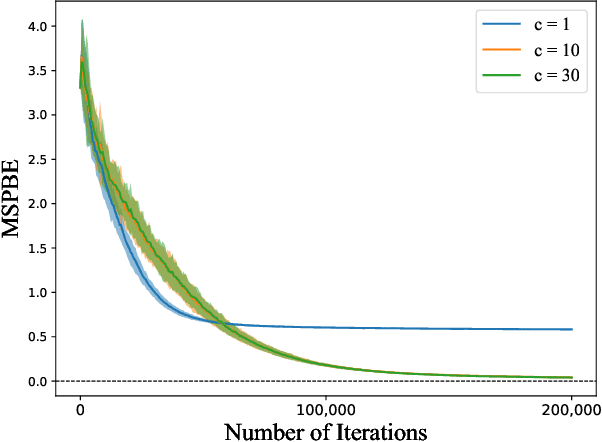

Several successful reinforcement learning algorithms make use of regularization to promote multi-modal policies that exhibit enhanced exploration and robustness. With functional approximation, the convergence properties of some of these algorithms (e.g. soft Q-learning) are not well understood. In this paper, we consider a single-loop algorithm for minimizing the projected Bellman error with finite time convergence guarantees in the case of linear function approximation. The algorithm operates on two scales: a slower scale for updating the target network of the state-action values, and a faster scale for approximating the Bellman backups in the subspace of the span of basis vectors. We show that, under certain assumptions, the proposed algorithm converges to a stationary point in the presence of Markovian noise. In addition, we provide a performance guarantee for the policies derived from the proposed algorithm.
Resolving uncertainty on the fly: Modeling adaptive driving behavior as active inference
Nov 10, 2023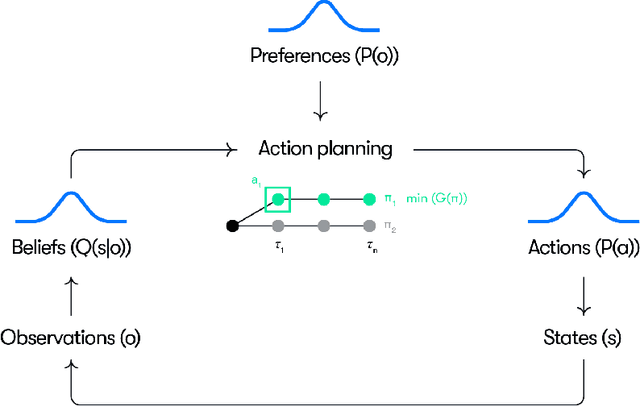
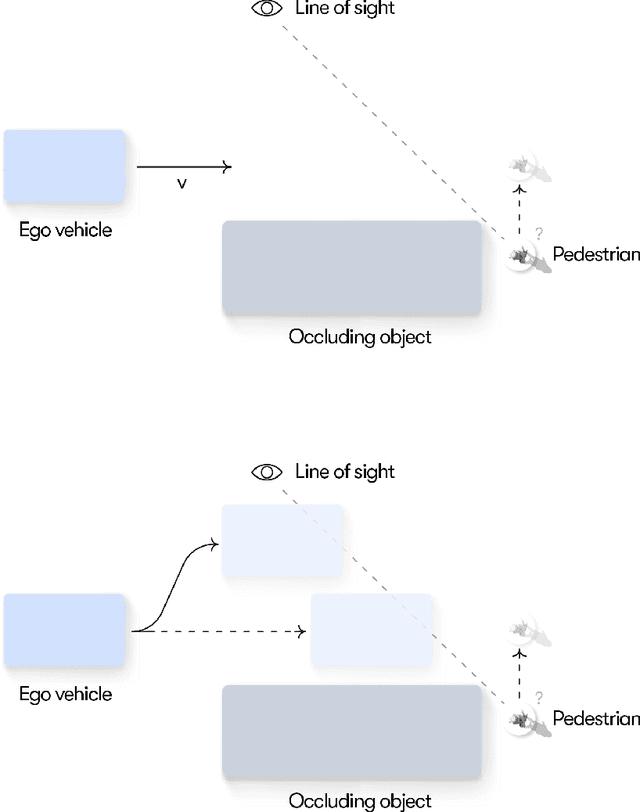

Understanding adaptive human driving behavior, in particular how drivers manage uncertainty, is of key importance for developing simulated human driver models that can be used in the evaluation and development of autonomous vehicles. However, existing traffic psychology models of adaptive driving behavior either lack computational rigor or only address specific scenarios and/or behavioral phenomena. While models developed in the fields of machine learning and robotics can effectively learn adaptive driving behavior from data, due to their black box nature, they offer little or no explanation of the mechanisms underlying the adaptive behavior. Thus, a generalizable, interpretable, computational model of adaptive human driving behavior is still lacking. This paper proposes such a model based on active inference, a behavioral modeling framework originating in computational neuroscience. The model offers a principled solution to how humans trade progress against caution through policy selection based on the single mandate to minimize expected free energy. This casts goal-seeking and information-seeking (uncertainty-resolving) behavior under a single objective function, allowing the model to seamlessly resolve uncertainty as a means to obtain its goals. We apply the model in two apparently disparate driving scenarios that require managing uncertainty, (1) driving past an occluding object and (2) visual time sharing between driving and a secondary task, and show how human-like adaptive driving behavior emerges from the single principle of expected free energy minimization.
A Unified View on Solving Objective Mismatch in Model-Based Reinforcement Learning
Oct 10, 2023Model-based Reinforcement Learning (MBRL) aims to make agents more sample-efficient, adaptive, and explainable by learning an explicit model of the environment. While the capabilities of MBRL agents have significantly improved in recent years, how to best learn the model is still an unresolved question. The majority of MBRL algorithms aim at training the model to make accurate predictions about the environment and subsequently using the model to determine the most rewarding actions. However, recent research has shown that model predictive accuracy is often not correlated with action quality, tracing the root cause to the \emph{objective mismatch} between accurate dynamics model learning and policy optimization of rewards. A number of interrelated solution categories to the objective mismatch problem have emerged as MBRL continues to mature as a research area. In this work, we provide an in-depth survey of these solution categories and propose a taxonomy to foster future research.