 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Q-Learning with Linear Function Approximation
Paper and Code
Jan 26, 2024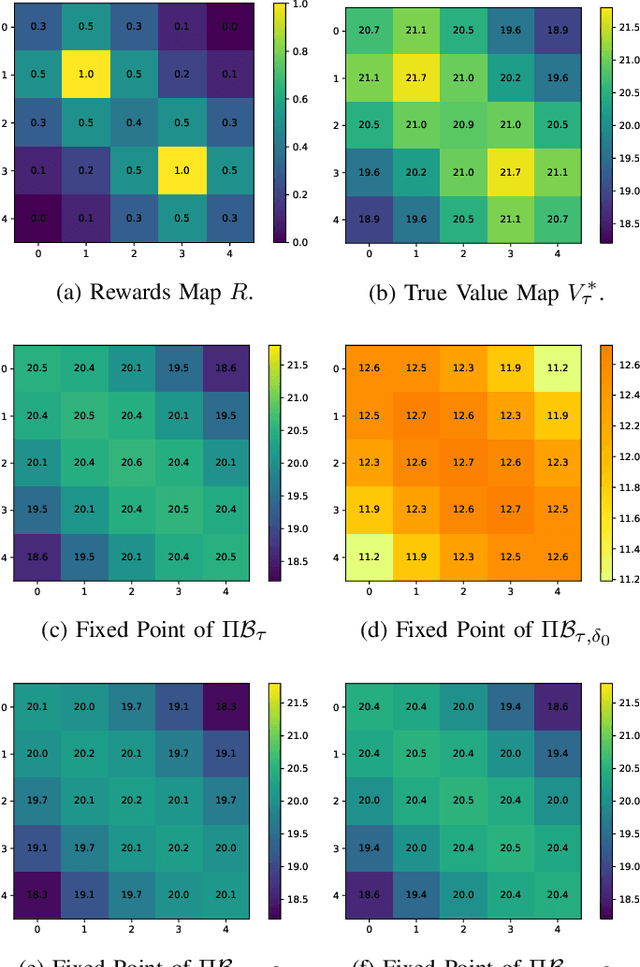
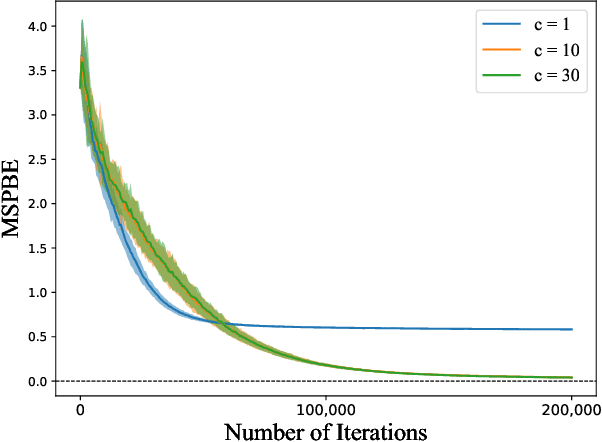

Several successful reinforcement learning algorithms make use of regularization to promote multi-modal policies that exhibit enhanced exploration and robustness. With functional approximation, the convergence properties of some of these algorithms (e.g. soft Q-learning) are not well understood. In this paper, we consider a single-loop algorithm for minimizing the projected Bellman error with finite time convergence guarantees in the case of linear function approximation. The algorithm operates on two scales: a slower scale for updating the target network of the state-action values, and a faster scale for approximating the Bellman backups in the subspace of the span of basis vectors. We show that, under certain assumptions, the proposed algorithm converges to a stationary point in the presence of Markovian noise. In addition, we provide a performance guarantee for the policies derived from the proposed algorithm.