 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Causal Structure Learning with Additive Models
Nov 05, 2025Causal structure learning has long been the central task of inferring causal insights from data. Despite the abundance of real-world processes exhibiting higher-order mechanisms, however, an explicit treatment of interactions in causal discovery has received little attention. In this work, we focus on extending the causal additive model (CAM) to additive models with higher-order interactions. This second level of modularity we introduce to the structure learning problem is most easily represented by a directed acyclic hypergraph which extends the DAG. We introduce the necessary definitions and theoretical tools to handle the novel structure we introduce and then provide identifiability results for the hyper DAG, extending the typical Markov equivalence classes. We next provide insights into why learning the more complex hypergraph structure may actually lead to better empirical results. In particular, more restrictive assumptions like CAM correspond to easier-to-learn hyper DAGs and better finite sample complexity. We finally develop an extension of the greedy CAM algorithm which can handle the more complex hyper DAG search space and demonstrate its empirical usefulness in synthetic experiments.
InstaSHAP: Interpretable Additive Models Explain Shapley Values Instantly
Feb 20, 2025In recent years, the Shapley value and SHAP explanations have emerged as one of the most dominant paradigms for providing post-hoc explanations of black-box models. Despite their well-founded theoretical properties, many recent works have focused on the limitations in both their computational efficiency and their representation power. The underlying connection with additive models, however, is left critically under-emphasized in the current literature. In this work, we find that a variational perspective linking GAM models and SHAP explanations is able to provide deep insights into nearly all recent developments. In light of this connection, we borrow in the other direction to develop a new method to train interpretable GAM models which are automatically purified to compute the Shapley value in a single forward pass. Finally, we provide theoretical results showing the limited representation power of GAM models is the same Achilles' heel existing in SHAP and discuss the implications for SHAP's modern usage in CV and NLP.
A Complete Decomposition of KL Error using Refined Information and Mode Interaction Selection
Oct 15, 2024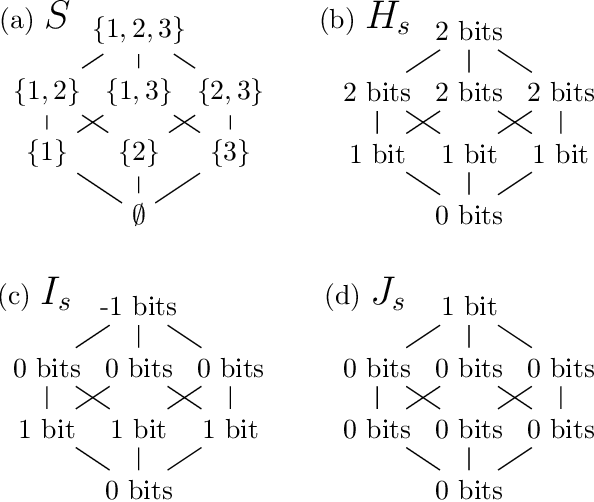

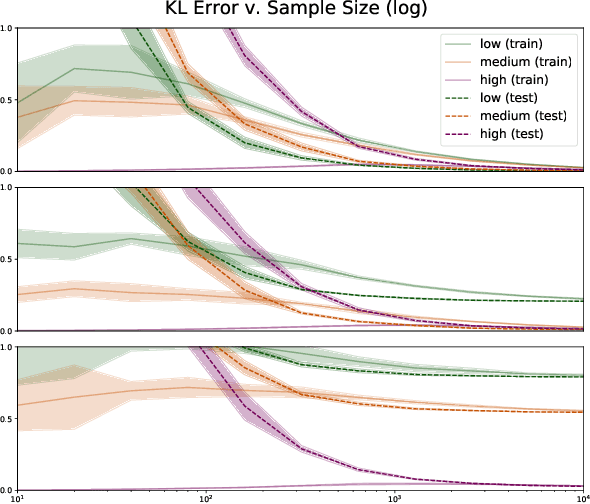

The log-linear model has received a significant amount of theoretical attention in previous decades and remains the fundamental tool used for learning probability distributions over discrete variables. Despite its large popularity in statistical mechanics and high-dimensional statistics, the vast majority of such energy-based modeling approaches only focus on the two-variable relationships, such as Boltzmann machines and Markov graphical models. Although these approaches have easier-to-solve structure learning problems and easier-to-optimize parametric distributions, they often ignore the rich structure which exists in the higher-order interactions between different variables. Using more recent tools from the field of information geometry, we revisit the classical formulation of the log-linear model with a focus on higher-order mode interactions, going beyond the 1-body modes of independent distributions and the 2-body modes of Boltzmann distributions. This perspective allows us to define a complete decomposition of the KL error. This then motivates the formulation of a sparse selection problem over the set of possible mode interactions. In the same way as sparse graph selection allows for better generalization, we find that our learned distributions are able to more efficiently use the finite amount of data which is available in practice. On both synthetic and real-world datasets, we demonstrate our algorithm's effectiveness in maximizing the log-likelihood for the generative task and also the ease of adaptability to the discriminative task of classification.
Discovering Car-following Dynamics from Trajectory Data through Deep Learning
Aug 01, 2024This study aims to discover the governing mathematical expressions of car-following dynamics from trajectory data directly using deep learning techniques. We propose an expression exploration framework based on deep symbolic regression (DSR) integrated with a variable intersection selection (VIS) method to find variable combinations that encourage interpretable and parsimonious mathematical expressions. In the exploration learning process, two penalty terms are added to improve the reward function: (i) a complexity penalty to regulate the complexity of the explored expressions to be parsimonious, and (ii) a variable interaction penalty to encourage the expression exploration to focus on variable combinations that can best describe the data. We show the performance of the proposed method to learn several car-following dynamics models and discuss its limitations and future research directions.
TextGenSHAP: Scalable Post-hoc Explanations in Text Generation with Long Documents
Dec 03, 2023



Large language models (LLMs) have attracted huge interest in practical applications given their increasingly accurate responses and coherent reasoning abilities. Given their nature as black-boxes using complex reasoning processes on their inputs, it is inevitable that the demand for scalable and faithful explanations for LLMs' generated content will continue to grow. There have been major developments in the explainability of neural network models over the past decade. Among them, post-hoc explainability methods, especially Shapley values, have proven effective for interpreting deep learning models. However, there are major challenges in scaling up Shapley values for LLMs, particularly when dealing with long input contexts containing thousands of tokens and autoregressively generated output sequences. Furthermore, it is often unclear how to effectively utilize generated explanations to improve the performance of LLMs. In this paper, we introduce TextGenSHAP, an efficient post-hoc explanation method incorporating LM-specific techniques. We demonstrate that this leads to significant increases in speed compared to conventional Shapley value computations, reducing processing times from hours to minutes for token-level explanations, and to just seconds for document-level explanations. In addition, we demonstrate how real-time Shapley values can be utilized in two important scenarios, providing better understanding of long-document question answering by localizing important words and sentences; and improving existing document retrieval systems through enhancing the accuracy of selected passages and ultimately the final responses.
Measuring, Interpreting, and Improving Fairness of Algorithms using Causal Inference and Randomized Experiments
Sep 04, 2023



Algorithm fairness has become a central problem for the broad adoption of artificial intelligence. Although the past decade has witnessed an explosion of excellent work studying algorithm biases, achieving fairness in real-world AI production systems has remained a challenging task. Most existing works fail to excel in practical applications since either they have conflicting measurement techniques and/ or heavy assumptions, or require code-access of the production models, whereas real systems demand an easy-to-implement measurement framework and a systematic way to correct the detected sources of bias. In this paper, we leverage recent advances in causal inference and interpretable machine learning to present an algorithm-agnostic framework (MIIF) to Measure, Interpret, and Improve the Fairness of an algorithmic decision. We measure the algorithm bias using randomized experiments, which enables the simultaneous measurement of disparate treatment, disparate impact, and economic value. Furthermore, using modern interpretability techniques, we develop an explainable machine learning model which accurately interprets and distills the beliefs of a blackbox algorithm. Altogether, these techniques create a simple and powerful toolset for studying algorithm fairness, especially for understanding the cost of fairness in practical applications like e-commerce and targeted advertising, where industry A/B testing is already abundant.
Estimating Treatment Effects from Irregular Time Series Observations with Hidden Confounders
Mar 04, 2023



Causal analysis for time series data, in particular estimating individualized treatment effect (ITE), is a key task in many real-world applications, such as finance, retail, healthcare, etc. Real-world time series can include large-scale, irregular, and intermittent time series observations, raising significant challenges to existing work attempting to estimate treatment effects. Specifically, the existence of hidden confounders can lead to biased treatment estimates and complicate the causal inference process. In particular, anomaly hidden confounders which exceed the typical range can lead to high variance estimates. Moreover, in continuous time settings with irregular samples, it is challenging to directly handle the dynamics of causality. In this paper, we leverage recent advances in Lipschitz regularization and neural controlled differential equations (CDE) to develop an effective and scalable solution, namely LipCDE, to address the above challenges. LipCDE can directly model the dynamic causal relationships between historical data and outcomes with irregular samples by considering the boundary of hidden confounders given by Lipschitz-constrained neural networks. Furthermore, we conduct extensive experiments on both synthetic and real-world datasets to demonstrate the effectiveness and scalability of LipCDE.
Estimating Treatment Effects in Continuous Time with Hidden Confounders
Feb 21, 2023Estimating treatment effects plays a crucial role in causal inference, having many real-world applications like policy analysis and decision making. Nevertheless, estimating treatment effects in the longitudinal setting in the presence of hidden confounders remains an extremely challenging problem. Recently, there is a growing body of work attempting to obtain unbiased ITE estimates from time-dynamic observational data by ignoring the possible existence of hidden confounders. Additionally, many existing works handling hidden confounders are not applicable for continuous-time settings. In this paper, we extend the line of work focusing on deconfounding in the dynamic time setting in the presence of hidden confounders. We leverage recent advancements in neural differential equations to build a latent factor model using a stochastic controlled differential equation and Lipschitz constrained convolutional operation in order to continuously incorporate information about ongoing interventions and irregularly sampled observations. Experiments on both synthetic and real-world datasets highlight the promise of continuous time methods for estimating treatment effects in the presence of hidden confounders.
Sparse Interaction Additive Networks via Feature Interaction Detection and Sparse Selection
Sep 19, 2022


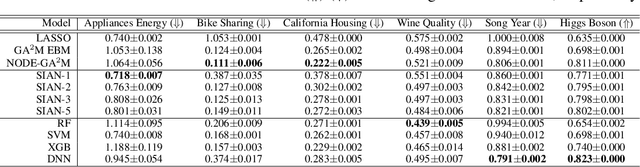
There is currently a large gap in performance between the statistically rigorous methods like linear regression or additive splines and the powerful deep methods using neural networks. Previous works attempting to close this gap have failed to fully investigate the exponentially growing number of feature combinations which deep networks consider automatically during training. In this work, we develop a tractable selection algorithm to efficiently identify the necessary feature combinations by leveraging techniques in feature interaction detection. Our proposed Sparse Interaction Additive Networks (SIAN) construct a bridge from these simple and interpretable models to fully connected neural networks. SIAN achieves competitive performance against state-of-the-art methods across multiple large-scale tabular datasets and consistently finds an optimal tradeoff between the modeling capacity of neural networks and the generalizability of simpler methods.
Interpretable Artificial Intelligence through the Lens of Feature Interaction
Mar 01, 2021
Interpretation of deep learning models is a very challenging problem because of their large number of parameters, complex connections between nodes, and unintelligible feature representations. Despite this, many view interpretability as a key solution to trustworthiness, fairness, and safety, especially as deep learning is applied to more critical decision tasks like credit approval, job screening, and recidivism prediction. There is an abundance of good research providing interpretability to deep learning models; however, many of the commonly used methods do not consider a phenomenon called "feature interaction." This work first explains the historical and modern importance of feature interactions and then surveys the modern interpretability methods which do explicitly consider feature interactions. This survey aims to bring to light the importance of feature interactions in the larger context of machine learning interpretability, especially in a modern context where deep learning models heavily rely on feature interactions.