 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrary Shape Text Detection via Segmentation with Probability Maps
Paper and Code

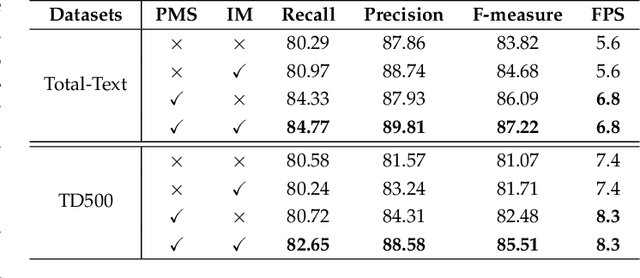

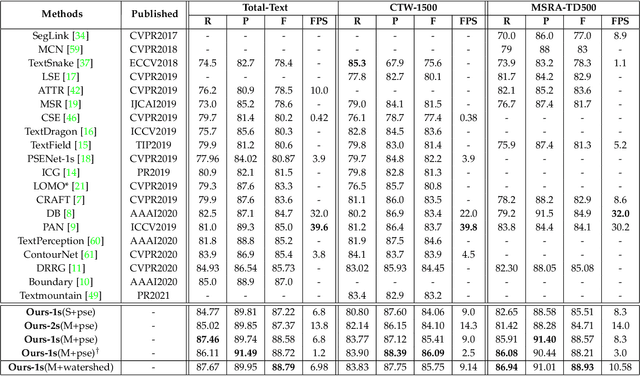
Arbitrary shape text detection is a challenging task due to the significantly varied sizes and aspect ratios, arbitrary orientations or shapes, inaccurate annotations, etc. Due to the scalability of pixel-level prediction, segmentation-based methods can adapt to various shape texts and hence attracted considerable attention recently. However, accurate pixel-level annotations of texts are formidable, and the existing datasets for scene text detection only provide coarse-grained boundary annotations. Consequently, numerous misclassified text pixels or background pixels inside annotations always exist, degrading the performance of segmentation-based text detection methods. Generally speaking, whether a pixel belongs to text or not is highly related to the distance with the adjacent annotation boundary. With this observation, in this paper, we propose an innovative and robust segmentation-based detection method via probability maps for accurately detecting text instances. To be concrete, we adopt a Sigmoid Alpha Function (SAF) to transfer the distances between boundaries and their inside pixels to a probability map. However, one probability map can not cover complex probability distributions well because of the uncertainty of coarse-grained text boundary annotations. Therefore, we adopt a group of probability maps computed by a series of Sigmoid Alpha Functions to describe the possible probability distributions. In addition, we propose an iterative model to learn to predict and assimilate probability maps for providing enough information to reconstruct text instances. Finally, simple region growth algorithms are adopted to aggregate probability maps to complete text instances. Experimental results demonstrate that our method achieves state-of-the-art performance in terms of detection accuracy on several benchmarks.