 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Message Passing for Objective-Based Uncertainty Quantification and Optimal Experimental Design
Mar 14, 2022



Real-world scientific or engineering applications often involve mathematical modeling of complex uncertain systems with a large number of unknown parameters. The complexity of such systems, and the enormous uncertainties therein, typically make accurate model identification from the available data infeasible. In such cases, it is desirable to represent the model uncertainty in a Bayesian paradigm, based on which we can design robust operators that maintain the best overall performance across all possible models and design optimal experiments that can effectively reduce uncertainty to maximally enhance the performance of such operators. While objective-based uncertainty quantification (objective-UQ) based on MOCU (mean objective cost of uncertainty) has been shown to provide effective means for quantifying and handling uncertainty in complex systems, a major drawback has been the high computational cost of estimating MOCU. In this work, we demonstrate for the first time that one can design accurate surrogate models for efficient objective-UQ via MOCU based on a data-driven approach. We adopt a neural message passing model for surrogate modeling, which incorporates a novel axiomatic constraint loss that penalizes an increase in the estimated system uncertainty. As an illustrative example, we consider the optimal experimental design (OED) problem for uncertain Kuramoto models, where the goal is to predict the experiments that can most effectively enhance the robust synchronization performance through uncertainty reduction. Through quantitative performance assessment, we show that our proposed approach can accelerate MOCU-based OED by four to five orders of magnitude, virtually without any visible loss of performance compared to the previous state-of-the-art. The proposed approach can be applied to general OED tasks, beyond the Kuramoto model.
Optimal Decision Making in High-Throughput Virtual Screening Pipelines
Sep 23, 2021
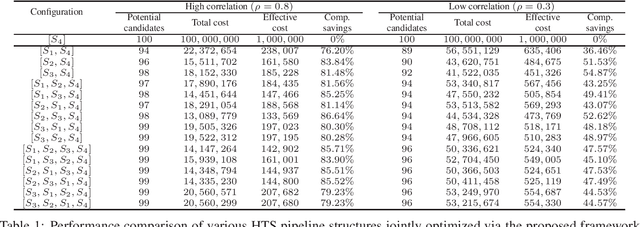
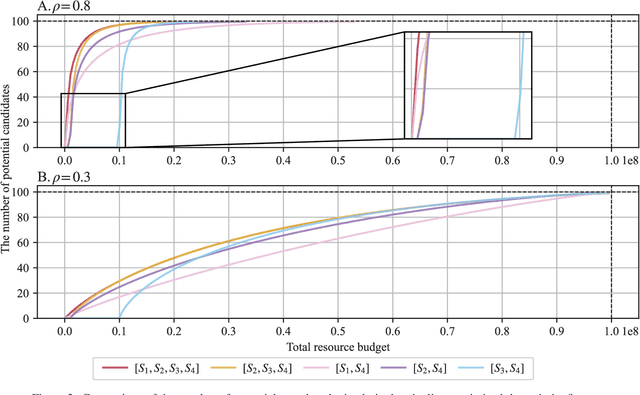

Effective selection of the potential candidates that meet certain conditions in a tremendously large search space has been one of the major concerns in many real-world applications. In addition to the nearly infinitely large search space, rigorous evaluation of a sample based on the reliable experimental or computational platform is often prohibitively expensive, making the screening problem more challenging. In such a case, constructing a high-throughput screening (HTS) pipeline that pre-sifts the samples expected to be potential candidates through the efficient earlier stages, results in a significant amount of savings in resources. However, to the best of our knowledge, despite many successful applications, no one has studied optimal pipeline design or optimal pipeline operations. In this study, we propose two optimization frameworks, applying to most (if not all) screening campaigns involving experimental or/and computational evaluations, for optimally determining the screening thresholds of an HTS pipeline. We validate the proposed frameworks on both analytic and practical scenarios. In particular, we consider the optimal computational campaign for the long non-coding RNA (lncRNA) classification as a practical example. To accomplish this, we built the high-throughput virtual screening (HTVS) pipeline for classifying the lncRNA. The simulation results demonstrate that the proposed frameworks significantly reduce the effective selection cost per potential candidate and make the HTS pipelines less sensitive to their structural variations. In addition to the validation, we provide insights on constructing a better HTS pipeline based on the simulation results.