 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLI:Non-uniform Linear Interpolation Approximation of Nonlinear Operations for Efficient LLMs Inference
Feb 03, 2026Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of tasks, but their deployment is often constrained by substantial memory footprints and computational costs. While prior work has achieved significant progress in compressing and accelerating linear layers, nonlinear layers-such as SiLU, RMSNorm, and Softmax-still heavily depend on high-precision floating-point operations. In this paper, we propose a calibration-free, dynamic-programming-optimal, and hardware-friendly framework called Non-uniform Linear Interpolation (NLI). NLI is capable of efficiently approximating a variety of nonlinear functions, enabling seamless integration into LLMs and other deep neural networks with almost no loss in accuracy. NLI ingeniously recasts cutpoint selection as a dynamic-programming problem, achieving the globally minimal interpolation error in O(MxN2) time via Bellman's optimality principle. Based on the NLI algorithm, we also design and implement a plug-and-play universal nonlinear computation unit. Hardware experiments demonstrate that the NLI Engine achieves more than 4x improvement in computational efficiency compared to the state-of-the-art designs.
FQ-PETR: Fully Quantized Position Embedding Transformation for Multi-View 3D Object Detection
Nov 14, 2025Camera-based multi-view 3D detection is crucial for autonomous driving. PETR and its variants (PETRs) excel in benchmarks but face deployment challenges due to high computational cost and memory footprint. Quantization is an effective technique for compressing deep neural networks by reducing the bit width of weights and activations. However, directly applying existing quantization methods to PETRs leads to severe accuracy degradation. This issue primarily arises from two key challenges: (1) significant magnitude disparity between multi-modal features-specifically, image features and camera-ray positional embeddings (PE), and (2) the inefficiency and approximation error of quantizing non-linear operators, which commonly rely on hardware-unfriendly computations. In this paper, we propose FQ-PETR, a fully quantized framework for PETRs, featuring three key innovations: (1) Quantization-Friendly LiDAR-ray Position Embedding (QFPE): Replacing multi-point sampling with LiDAR-prior-guided single-point sampling and anchor-based embedding eliminates problematic non-linearities (e.g., inverse-sigmoid) and aligns PE scale with image features, preserving accuracy. (2) Dual-Lookup Table (DULUT): This algorithm approximates complex non-linear functions using two cascaded linear LUTs, achieving high fidelity with minimal entries and no specialized hardware. (3) Quantization After Numerical Stabilization (QANS): Performing quantization after softmax numerical stabilization mitigates attention distortion from large inputs. On PETRs (e.g. PETR, StreamPETR, PETRv2, MV2d), FQ-PETR under W8A8 achieves near-floating-point accuracy (1% degradation) while reducing latency by up to 75%, significantly outperforming existing PTQ and QAT baselines.
MoEQuant: Enhancing Quantization for Mixture-of-Experts Large Language Models via Expert-Balanced Sampling and Affinity Guidance
May 02, 2025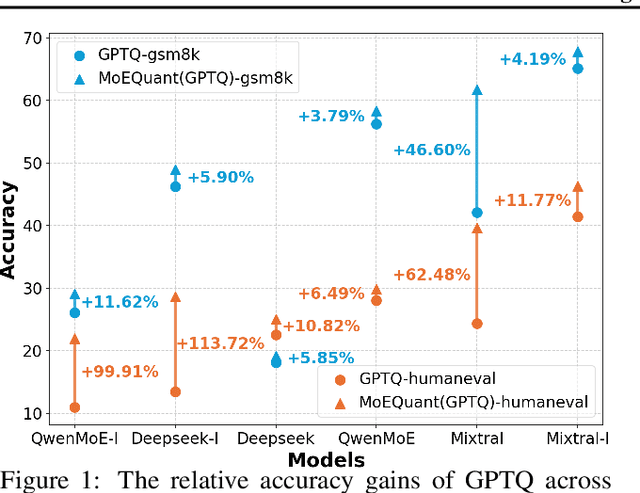
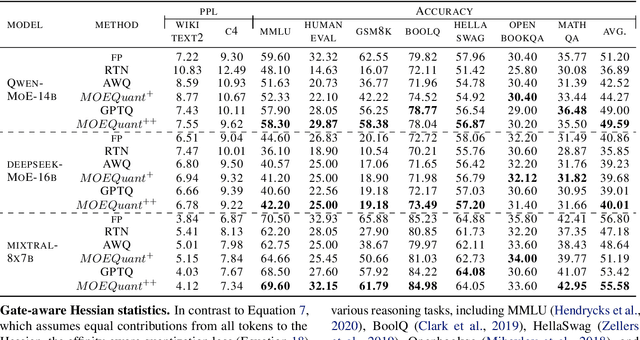
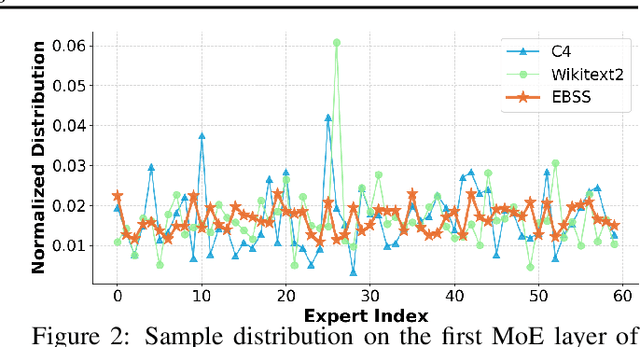
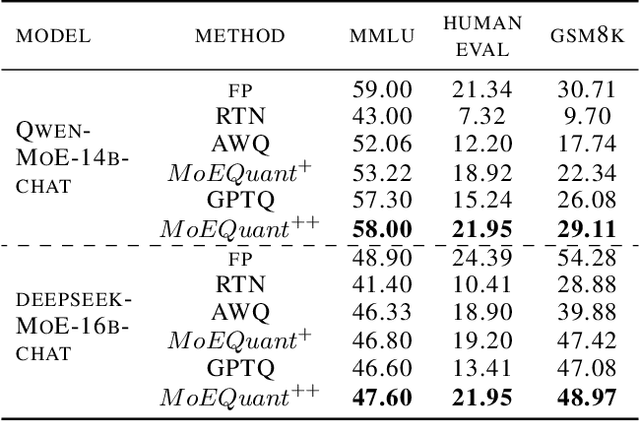
Mixture-of-Experts (MoE) large language models (LLMs), which leverage dynamic routing and sparse activation to enhance efficiency and scalability, have achieved higher performance while reducing computational costs. However, these models face significant memory overheads, limiting their practical deployment and broader adoption. Post-training quantization (PTQ), a widely used method for compressing LLMs, encounters severe accuracy degradation and diminished generalization performance when applied to MoE models. This paper investigates the impact of MoE's sparse and dynamic characteristics on quantization and identifies two primary challenges: (1) Inter-expert imbalance, referring to the uneven distribution of samples across experts, which leads to insufficient and biased calibration for less frequently utilized experts; (2) Intra-expert imbalance, arising from MoE's unique aggregation mechanism, which leads to varying degrees of correlation between different samples and their assigned experts. To address these challenges, we propose MoEQuant, a novel quantization framework tailored for MoE LLMs. MoE-Quant includes two novel techniques: 1) Expert-Balanced Self-Sampling (EBSS) is an efficient sampling method that efficiently constructs a calibration set with balanced expert distributions by leveraging the cumulative probabilities of tokens and expert balance metrics as guiding factors. 2) Affinity-Guided Quantization (AGQ), which incorporates affinities between experts and samples into the quantization process, thereby accurately assessing the impact of individual samples on different experts within the MoE layer. Experiments demonstrate that MoEQuant achieves substantial performance gains (more than 10 points accuracy gain in the HumanEval for DeepSeekMoE-16B under 4-bit quantization) and boosts efficiency.
RWKVQuant: Quantizing the RWKV Family with Proxy Guided Hybrid of Scalar and Vector Quantization
May 02, 2025



RWKV is a modern RNN architecture with comparable performance to Transformer, but still faces challenges when deployed to resource-constrained devices. Post Training Quantization (PTQ), which is a an essential technique to reduce model size and inference latency, has been widely used in Transformer models. However, it suffers significant degradation of performance when applied to RWKV. This paper investigates and identifies two key constraints inherent in the properties of RWKV: (1) Non-linear operators hinder the parameter-fusion of both smooth- and rotation-based quantization, introducing extra computation overhead. (2) The larger amount of uniformly distributed weights poses challenges for cluster-based quantization, leading to reduced accuracy. To this end, we propose RWKVQuant, a PTQ framework tailored for RWKV models, consisting of two novel techniques: (1) a coarse-to-fine proxy capable of adaptively selecting different quantization approaches by assessing the uniformity and identifying outliers in the weights, and (2) a codebook optimization algorithm that enhances the performance of cluster-based quantization methods for element-wise multiplication in RWKV. Experiments show that RWKVQuant can quantize RWKV-6-14B into about 3-bit with less than 1% accuracy loss and 2.14x speed up.
Q-PETR: Quant-aware Position Embedding Transformation for Multi-View 3D Object Detection
Feb 21, 2025



PETR-based methods have dominated benchmarks in 3D perception and are increasingly becoming a key component in modern autonomous driving systems. However, their quantization performance significantly degrades when INT8 inference is required, with a degradation of 58.2% in mAP and 36.9% in NDS on the NuScenes dataset. To address this issue, we propose a quantization-aware position embedding transformation for multi-view 3D object detection, termed Q-PETR. Q-PETR offers a quantizationfriendly and deployment-friendly architecture while preserving the original performance of PETR. It substantially narrows the accuracy gap between INT8 and FP32 inference for PETR-series methods. Without bells and whistles, our approach reduces the mAP and NDS drop to within 1% under standard 8-bit per-tensor post-training quantization. Furthermore, our method exceeds the performance of the original PETR in terms of floating-point precision. Extensive experiments across a variety of PETR-series models demonstrate its broad generalization.
Panoptic-FlashOcc: An Efficient Baseline to Marry Semantic Occupancy with Panoptic via Instance Center
Jun 15, 2024Panoptic occupancy poses a novel challenge by aiming to integrate instance occupancy and semantic occupancy within a unified framework. However, there is still a lack of efficient solutions for panoptic occupancy. In this paper, we propose Panoptic-FlashOcc, a straightforward yet robust 2D feature framework that enables realtime panoptic occupancy. Building upon the lightweight design of FlashOcc, our approach simultaneously learns semantic occupancy and class-aware instance clustering in a single network, these outputs are jointly incorporated through panoptic occupancy procession for panoptic occupancy. This approach effectively addresses the drawbacks of high memory and computation requirements associated with three-dimensional voxel-level representations. With its straightforward and efficient design that facilitates easy deployment, Panoptic-FlashOcc demonstrates remarkable achievements in panoptic occupancy prediction. On the Occ3D-nuScenes benchmark, it achieves exceptional performance, with 38.5 RayIoU and 29.1 mIoU for semantic occupancy, operating at a rapid speed of 43.9 FPS. Furthermore, it attains a notable score of 16.0 RayPQ for panoptic occupancy, accompanied by a fast inference speed of 30.2 FPS. These results surpass the performance of existing methodologies in terms of both speed and accuracy. The source code and trained models can be found at the following github repository: https://github.com/Yzichen/FlashOCC.
I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit Large Language Models
May 28, 2024



Post-training quantization (PTQ) serves as a potent technique to accelerate the inference of large language models (LLMs). Nonetheless, existing works still necessitate a considerable number of floating-point (FP) operations during inference, including additional quantization and de-quantization, as well as non-linear operators such as RMSNorm and Softmax. This limitation hinders the deployment of LLMs on the edge and cloud devices. In this paper, we identify the primary obstacle to integer-only quantization for LLMs lies in the large fluctuation of activations across channels and tokens in both linear and non-linear operations. To address this issue, we propose I-LLM, a novel integer-only fully-quantized PTQ framework tailored for LLMs. Specifically, (1) we develop Fully-Smooth Block-Reconstruction (FSBR) to aggressively smooth inter-channel variations of all activations and weights. (2) to alleviate degradation caused by inter-token variations, we introduce a novel approach called Dynamic Integer-only MatMul (DI-MatMul). This method enables dynamic quantization in full-integer matrix multiplication by dynamically quantizing the input and outputs with integer-only operations. (3) we design DI-ClippedSoftmax, DI-Exp, and DI-Normalization, which utilize bit shift to execute non-linear operators efficiently while maintaining accuracy. The experiment shows that our I-LLM achieves comparable accuracy to the FP baseline and outperforms non-integer quantization methods. For example, I-LLM can operate at W4A4 with negligible loss of accuracy. To our knowledge, we are the first to bridge the gap between integer-only quantization and LLMs. We've published our code on anonymous.4open.science, aiming to contribute to the advancement of this field.
Post-Training Quantization for Re-parameterization via Coarse & Fine Weight Splitting
Dec 17, 2023



Although neural networks have made remarkable advancements in various applications, they require substantial computational and memory resources. Network quantization is a powerful technique to compress neural networks, allowing for more efficient and scalable AI deployments. Recently, Re-parameterization has emerged as a promising technique to enhance model performance while simultaneously alleviating the computational burden in various computer vision tasks. However, the accuracy drops significantly when applying quantization on the re-parameterized networks. We identify that the primary challenge arises from the large variation in weight distribution across the original branches. To address this issue, we propose a coarse & fine weight splitting (CFWS) method to reduce quantization error of weight, and develop an improved KL metric to determine optimal quantization scales for activation. To the best of our knowledge, our approach is the first work that enables post-training quantization applicable on re-parameterized networks. For example, the quantized RepVGG-A1 model exhibits a mere 0.3% accuracy loss. The code is in https://github.com/NeonHo/Coarse-Fine-Weight-Split.git
FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Nov 18, 2023



Given the capability of mitigating the long-tail deficiencies and intricate-shaped absence prevalent in 3D object detection, occupancy prediction has become a pivotal component in autonomous driving systems. However, the procession of three-dimensional voxel-level representations inevitably introduces large overhead in both memory and computation, obstructing the deployment of to-date occupancy prediction approaches. In contrast to the trend of making the model larger and more complicated, we argue that a desirable framework should be deployment-friendly to diverse chips while maintaining high precision. To this end, we propose a plug-and-play paradigm, namely FlashOCC, to consolidate rapid and memory-efficient occupancy prediction while maintaining high precision. Particularly, our FlashOCC makes two improvements based on the contemporary voxel-level occupancy prediction approaches. Firstly, the features are kept in the BEV, enabling the employment of efficient 2D convolutional layers for feature extraction. Secondly, a channel-to-height transformation is introduced to lift the output logits from the BEV into the 3D space. We apply the FlashOCC to diverse occupancy prediction baselines on the challenging Occ3D-nuScenes benchmarks and conduct extensive experiments to validate the effectiveness. The results substantiate the superiority of our plug-and-play paradigm over previous state-of-the-art methods in terms of precision, runtime efficiency, and memory costs, demonstrating its potential for deployment. The code will be made available.