 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCDformer-based Momentum Transfer Model for Long-term Sports Prediction
Sep 16, 2024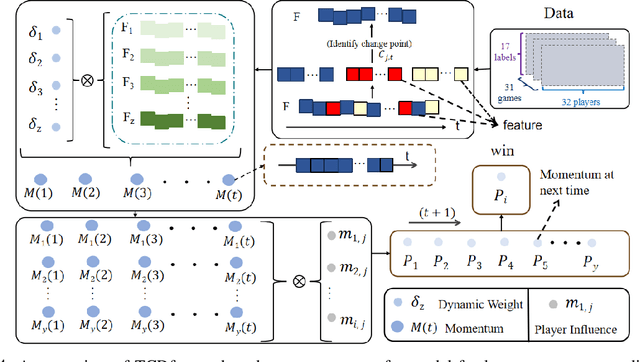
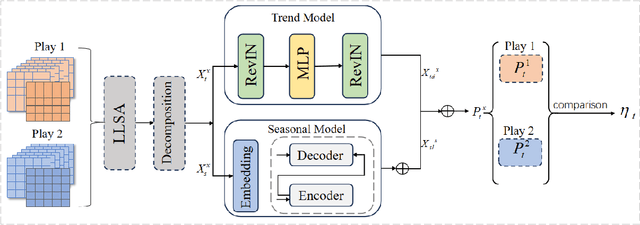
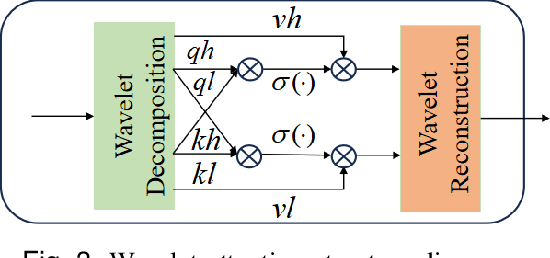

Accurate sports prediction is a crucial skill for professional coaches, which can assist in developing effective training strategies and scientific competition tactics. Traditional methods often use complex mathematical statistical techniques to boost predictability, but this often is limited by dataset scale and has difficulty handling long-term predictions with variable distributions, notably underperforming when predicting point-set-game multi-level matches. To deal with this challenge, this paper proposes TM2, a TCDformer-based Momentum Transfer Model for long-term sports prediction, which encompasses a momentum encoding module and a prediction module based on momentum transfer. TM2 initially encodes momentum in large-scale unstructured time series using the local linear scaling approximation (LLSA) module. Then it decomposes the reconstructed time series with momentum transfer into trend and seasonal components. The final prediction results are derived from the additive combination of a multilayer perceptron (MLP) for predicting trend components and wavelet attention mechanisms for seasonal components. Comprehensive experimental results show that on the 2023 Wimbledon men's tournament datasets, TM2 significantly surpasses existing sports prediction models in terms of performance, reducing MSE by 61.64% and MAE by 63.64%.
Post-Training Quantization for Re-parameterization via Coarse & Fine Weight Splitting
Dec 17, 2023Although neural networks have made remarkable advancements in various applications, they require substantial computational and memory resources. Network quantization is a powerful technique to compress neural networks, allowing for more efficient and scalable AI deployments. Recently, Re-parameterization has emerged as a promising technique to enhance model performance while simultaneously alleviating the computational burden in various computer vision tasks. However, the accuracy drops significantly when applying quantization on the re-parameterized networks. We identify that the primary challenge arises from the large variation in weight distribution across the original branches. To address this issue, we propose a coarse & fine weight splitting (CFWS) method to reduce quantization error of weight, and develop an improved KL metric to determine optimal quantization scales for activation. To the best of our knowledge, our approach is the first work that enables post-training quantization applicable on re-parameterized networks. For example, the quantized RepVGG-A1 model exhibits a mere 0.3% accuracy loss. The code is in https://github.com/NeonHo/Coarse-Fine-Weight-Split.git