 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePubSub-VFL: Towards Efficient Two-Party Split Learning in Heterogeneous Environments via Publisher/Subscriber Architecture
Oct 14, 2025With the rapid advancement of the digital economy, data collaboration between organizations has become a well-established business model, driving the growth of various industries. However, privacy concerns make direct data sharing impractical. To address this, Two-Party Split Learning (a.k.a. Vertical Federated Learning (VFL)) has emerged as a promising solution for secure collaborative learning. Despite its advantages, this architecture still suffers from low computational resource utilization and training efficiency. Specifically, its synchronous dependency design increases training latency, while resource and data heterogeneity among participants further hinder efficient computation. To overcome these challenges, we propose PubSub-VFL, a novel VFL paradigm with a Publisher/Subscriber architecture optimized for two-party collaborative learning with high computational efficiency. PubSub-VFL leverages the decoupling capabilities of the Pub/Sub architecture and the data parallelism of the parameter server architecture to design a hierarchical asynchronous mechanism, reducing training latency and improving system efficiency. Additionally, to mitigate the training imbalance caused by resource and data heterogeneity, we formalize an optimization problem based on participants' system profiles, enabling the selection of optimal hyperparameters while preserving privacy. We conduct a theoretical analysis to demonstrate that PubSub-VFL achieves stable convergence and is compatible with security protocols such as differential privacy. Extensive case studies on five benchmark datasets further validate its effectiveness, showing that, compared to state-of-the-art baselines, PubSub-VFL not only accelerates training by $2 \sim 7\times$ without compromising accuracy, but also achieves a computational resource utilization rate of up to 91.07%.
Rethinking Testing for LLM Applications: Characteristics, Challenges, and a Lightweight Interaction Protocol
Aug 28, 2025Applications of Large Language Models~(LLMs) have evolved from simple text generators into complex software systems that integrate retrieval augmentation, tool invocation, and multi-turn interactions. Their inherent non-determinism, dynamism, and context dependence pose fundamental challenges for quality assurance. This paper decomposes LLM applications into a three-layer architecture: \textbf{\textit{System Shell Layer}}, \textbf{\textit{Prompt Orchestration Layer}}, and \textbf{\textit{LLM Inference Core}}. We then assess the applicability of traditional software testing methods in each layer: directly applicable at the shell layer, requiring semantic reinterpretation at the orchestration layer, and necessitating paradigm shifts at the inference core. A comparative analysis of Testing AI methods from the software engineering community and safety analysis techniques from the AI community reveals structural disconnects in testing unit abstraction, evaluation metrics, and lifecycle management. We identify four fundamental differences that underlie 6 core challenges. To address these, we propose four types of collaborative strategies (\emph{Retain}, \emph{Translate}, \emph{Integrate}, and \emph{Runtime}) and explore a closed-loop, trustworthy quality assurance framework that combines pre-deployment validation with runtime monitoring. Based on these strategies, we offer practical guidance and a protocol proposal to support the standardization and tooling of LLM application testing. We propose a protocol \textbf{\textit{Agent Interaction Communication Language}} (AICL) that is used to communicate between AI agents. AICL has the test-oriented features and is easily integrated in the current agent framework.
TCDformer-based Momentum Transfer Model for Long-term Sports Prediction
Sep 16, 2024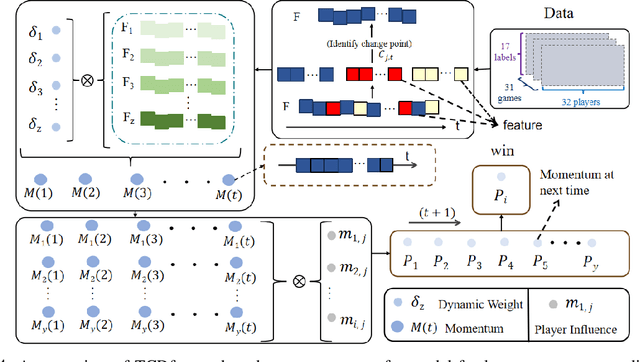
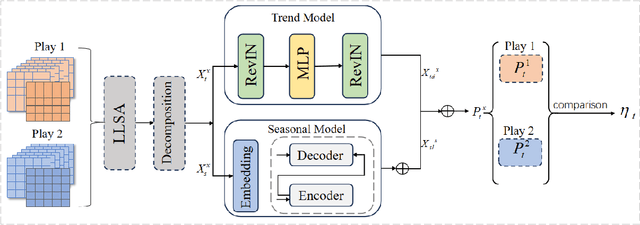
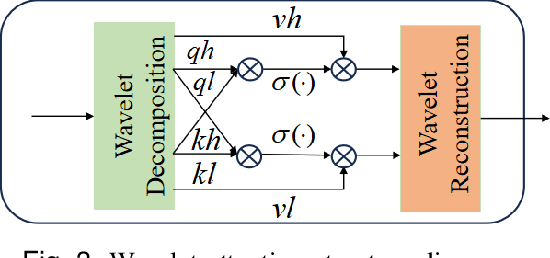

Accurate sports prediction is a crucial skill for professional coaches, which can assist in developing effective training strategies and scientific competition tactics. Traditional methods often use complex mathematical statistical techniques to boost predictability, but this often is limited by dataset scale and has difficulty handling long-term predictions with variable distributions, notably underperforming when predicting point-set-game multi-level matches. To deal with this challenge, this paper proposes TM2, a TCDformer-based Momentum Transfer Model for long-term sports prediction, which encompasses a momentum encoding module and a prediction module based on momentum transfer. TM2 initially encodes momentum in large-scale unstructured time series using the local linear scaling approximation (LLSA) module. Then it decomposes the reconstructed time series with momentum transfer into trend and seasonal components. The final prediction results are derived from the additive combination of a multilayer perceptron (MLP) for predicting trend components and wavelet attention mechanisms for seasonal components. Comprehensive experimental results show that on the 2023 Wimbledon men's tournament datasets, TM2 significantly surpasses existing sports prediction models in terms of performance, reducing MSE by 61.64% and MAE by 63.64%.
PASSION: Towards Effective Incomplete Multi-Modal Medical Image Segmentation with Imbalanced Missing Rates
Jul 20, 2024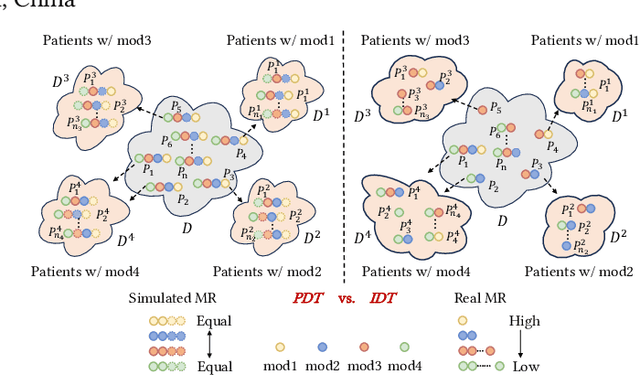
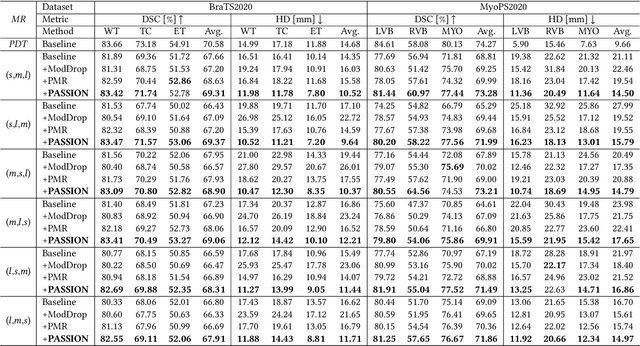
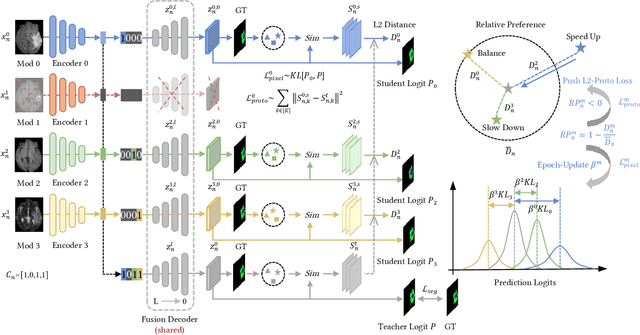
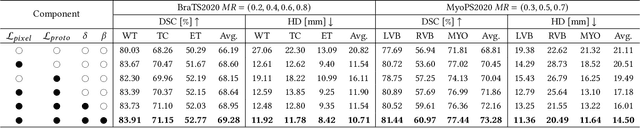
Incomplete multi-modal image segmentation is a fundamental task in medical imaging to refine deployment efficiency when only partial modalities are available. However, the common practice that complete-modality data is visible during model training is far from realistic, as modalities can have imbalanced missing rates in clinical scenarios. In this paper, we, for the first time, formulate such a challenging setting and propose Preference-Aware Self-diStillatION (PASSION) for incomplete multi-modal medical image segmentation under imbalanced missing rates. Specifically, we first construct pixel-wise and semantic-wise self-distillation to balance the optimization objective of each modality. Then, we define relative preference to evaluate the dominance of each modality during training, based on which to design task-wise and gradient-wise regularization to balance the convergence rates of different modalities. Experimental results on two publicly available multi-modal datasets demonstrate the superiority of PASSION against existing approaches for modality balancing. More importantly, PASSION is validated to work as a plug-and-play module for consistent performance improvement across different backbones. Code is available at https://github.com/Jun-Jie-Shi/PASSION.
FedMLP: Federated Multi-Label Medical Image Classification under Task Heterogeneity
Jun 27, 2024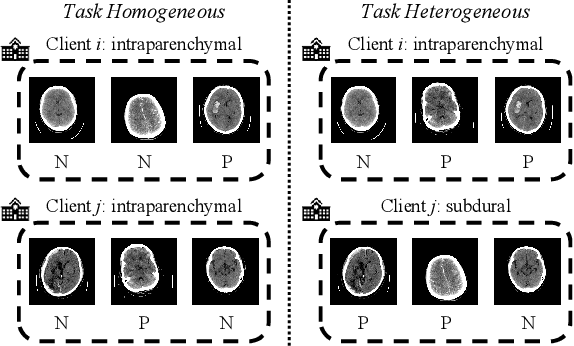
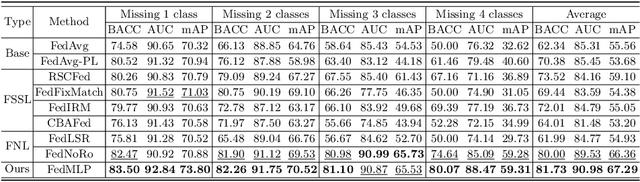
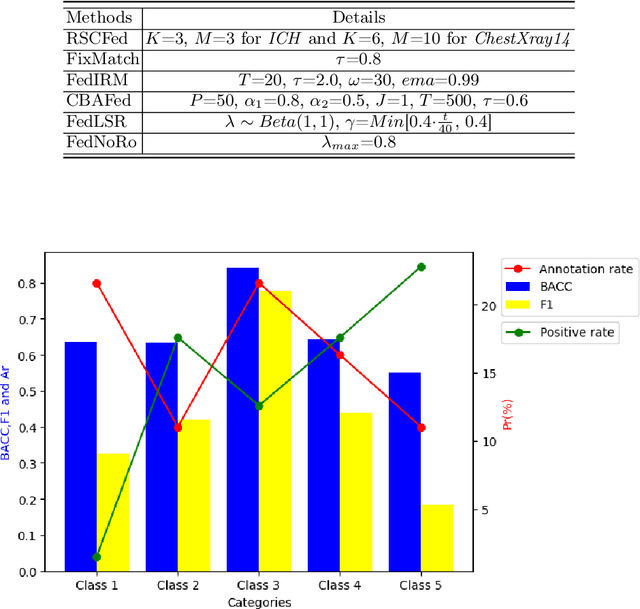
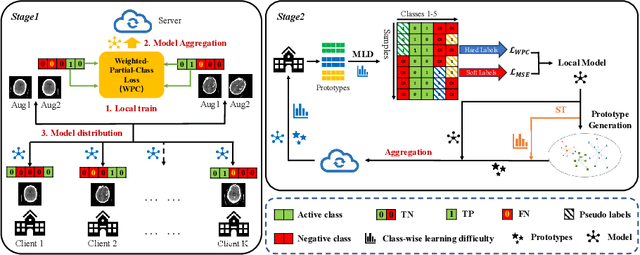
Cross-silo federated learning (FL) enables decentralized organizations to collaboratively train models while preserving data privacy and has made significant progress in medical image classification. One common assumption is task homogeneity where each client has access to all classes during training. However, in clinical practice, given a multi-label classification task, constrained by the level of medical knowledge and the prevalence of diseases, each institution may diagnose only partial categories, resulting in task heterogeneity. How to pursue effective multi-label medical image classification under task heterogeneity is under-explored. In this paper, we first formulate such a realistic label missing setting in the multi-label FL domain and propose a two-stage method FedMLP to combat class missing from two aspects: pseudo label tagging and global knowledge learning. The former utilizes a warmed-up model to generate class prototypes and select samples with high confidence to supplement missing labels, while the latter uses a global model as a teacher for consistency regularization to prevent forgetting missing class knowledge. Experiments on two publicly-available medical datasets validate the superiority of FedMLP against the state-of-the-art both federated semi-supervised and noisy label learning approaches under task heterogeneity. Code is available at https://github.com/szbonaldo/FedMLP.
Binaural Rendering of Ambisonic Signals by Neural Networks
Nov 04, 2022



Binaural rendering of ambisonic signals is of broad interest to virtual reality and immersive media. Conventional methods often require manually measured Head-Related Transfer Functions (HRTFs). To address this issue, we collect a paired ambisonic-binaural dataset and propose a deep learning framework in an end-to-end manner. Experimental results show that neural networks outperform the conventional method in objective metrics and achieve comparable subjective metrics. To validate the proposed framework, we experimentally explore different settings of the input features, model structures, output features, and loss functions. Our proposed system achieves an SDR of 7.32 and MOSs of 3.83, 3.58, 3.87, 3.58 in quality, timbre, localization, and immersion dimensions.