 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASSION: Towards Effective Incomplete Multi-Modal Medical Image Segmentation with Imbalanced Missing Rates
Jul 20, 2024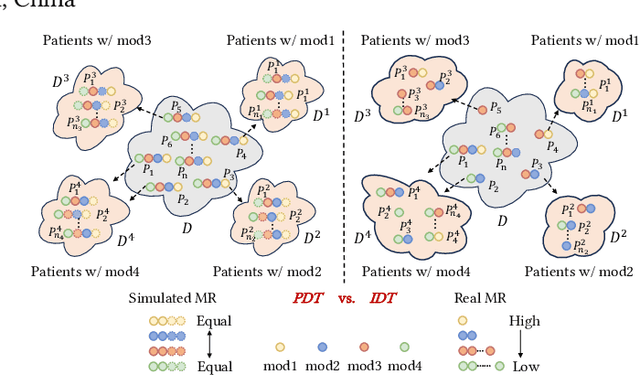
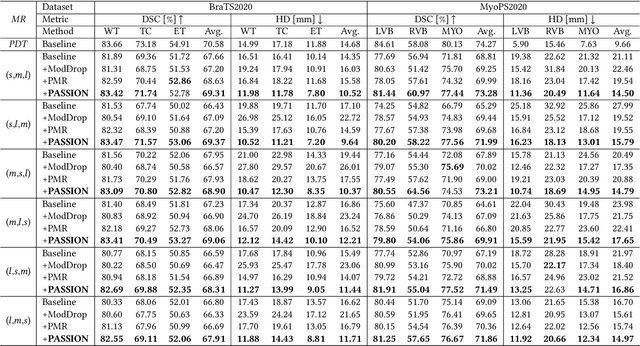
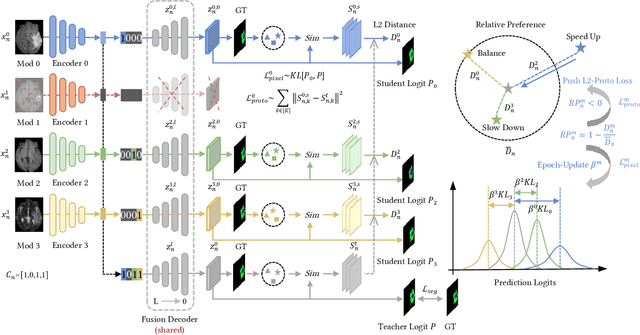
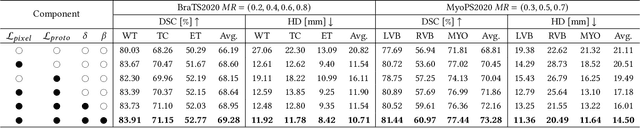
Incomplete multi-modal image segmentation is a fundamental task in medical imaging to refine deployment efficiency when only partial modalities are available. However, the common practice that complete-modality data is visible during model training is far from realistic, as modalities can have imbalanced missing rates in clinical scenarios. In this paper, we, for the first time, formulate such a challenging setting and propose Preference-Aware Self-diStillatION (PASSION) for incomplete multi-modal medical image segmentation under imbalanced missing rates. Specifically, we first construct pixel-wise and semantic-wise self-distillation to balance the optimization objective of each modality. Then, we define relative preference to evaluate the dominance of each modality during training, based on which to design task-wise and gradient-wise regularization to balance the convergence rates of different modalities. Experimental results on two publicly available multi-modal datasets demonstrate the superiority of PASSION against existing approaches for modality balancing. More importantly, PASSION is validated to work as a plug-and-play module for consistent performance improvement across different backbones. Code is available at https://github.com/Jun-Jie-Shi/PASSION.
FedMLP: Federated Multi-Label Medical Image Classification under Task Heterogeneity
Jun 27, 2024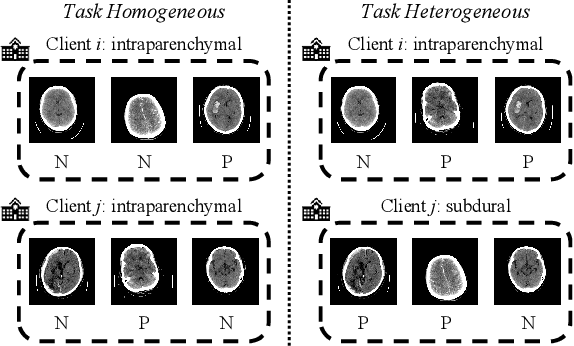
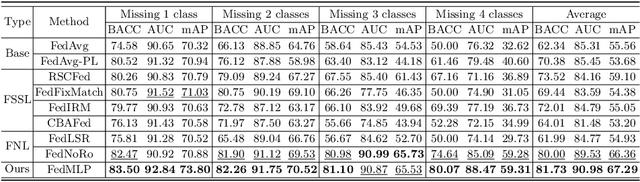
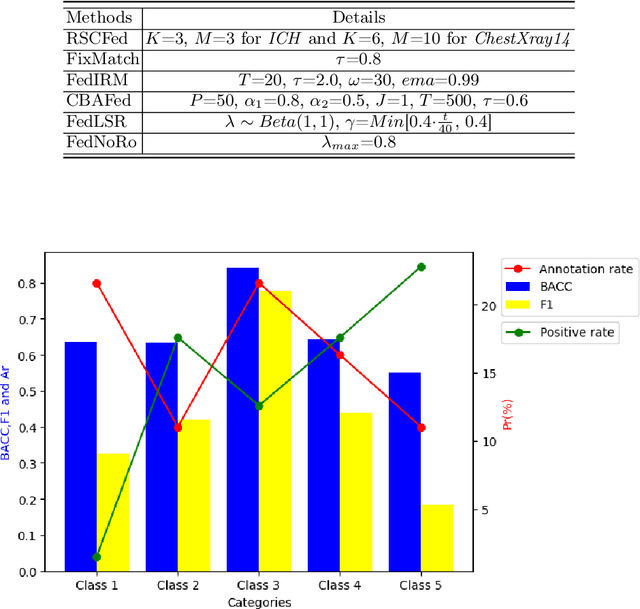
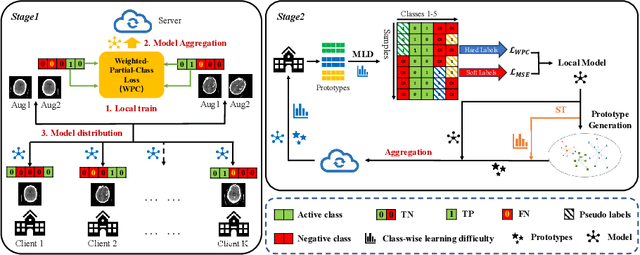
Cross-silo federated learning (FL) enables decentralized organizations to collaboratively train models while preserving data privacy and has made significant progress in medical image classification. One common assumption is task homogeneity where each client has access to all classes during training. However, in clinical practice, given a multi-label classification task, constrained by the level of medical knowledge and the prevalence of diseases, each institution may diagnose only partial categories, resulting in task heterogeneity. How to pursue effective multi-label medical image classification under task heterogeneity is under-explored. In this paper, we first formulate such a realistic label missing setting in the multi-label FL domain and propose a two-stage method FedMLP to combat class missing from two aspects: pseudo label tagging and global knowledge learning. The former utilizes a warmed-up model to generate class prototypes and select samples with high confidence to supplement missing labels, while the latter uses a global model as a teacher for consistency regularization to prevent forgetting missing class knowledge. Experiments on two publicly-available medical datasets validate the superiority of FedMLP against the state-of-the-art both federated semi-supervised and noisy label learning approaches under task heterogeneity. Code is available at https://github.com/szbonaldo/FedMLP.
FedA3I: Annotation Quality-Aware Aggregation for Federated Medical Image Segmentation Against Heterogeneous Annotation Noise
Dec 20, 2023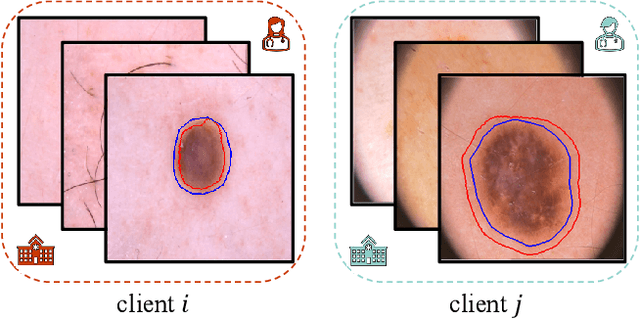

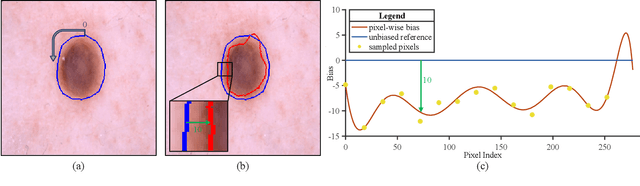
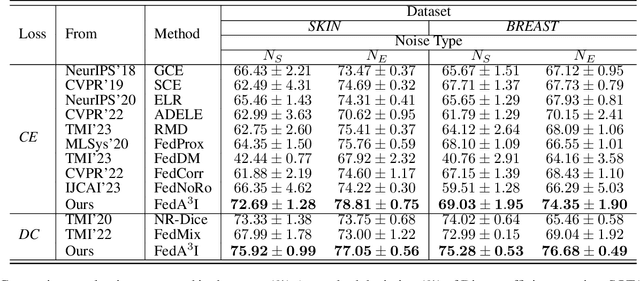
Federated learning (FL) has emerged as a promising paradigm for training segmentation models on decentralized medical data, owing to its privacy-preserving property. However, existing research overlooks the prevalent annotation noise encountered in real-world medical datasets, which limits the performance ceilings of FL. In this paper, we, for the first time, identify and tackle this problem. For problem formulation, we propose a contour evolution for modeling non-independent and identically distributed (Non-IID) noise across pixels within each client and then extend it to the case of multi-source data to form a heterogeneous noise model (\textit{i.e.}, Non-IID annotation noise across clients). For robust learning from annotations with such two-level Non-IID noise, we emphasize the importance of data quality in model aggregation, allowing high-quality clients to have a greater impact on FL. To achieve this, we propose \textbf{Fed}erated learning with \textbf{A}nnotation qu\textbf{A}lity-aware \textbf{A}ggregat\textbf{I}on, named \textbf{FedA$^3$I}, by introducing a quality factor based on client-wise noise estimation. Specifically, noise estimation at each client is accomplished through the Gaussian mixture model and then incorporated into model aggregation in a layer-wise manner to up-weight high-quality clients. Extensive experiments on two real-world medical image segmentation datasets demonstrate the superior performance of FedA$^3$I against the state-of-the-art approaches in dealing with cross-client annotation noise. The code is available at \color{blue}{https://github.com/wnn2000/FedAAAI}.